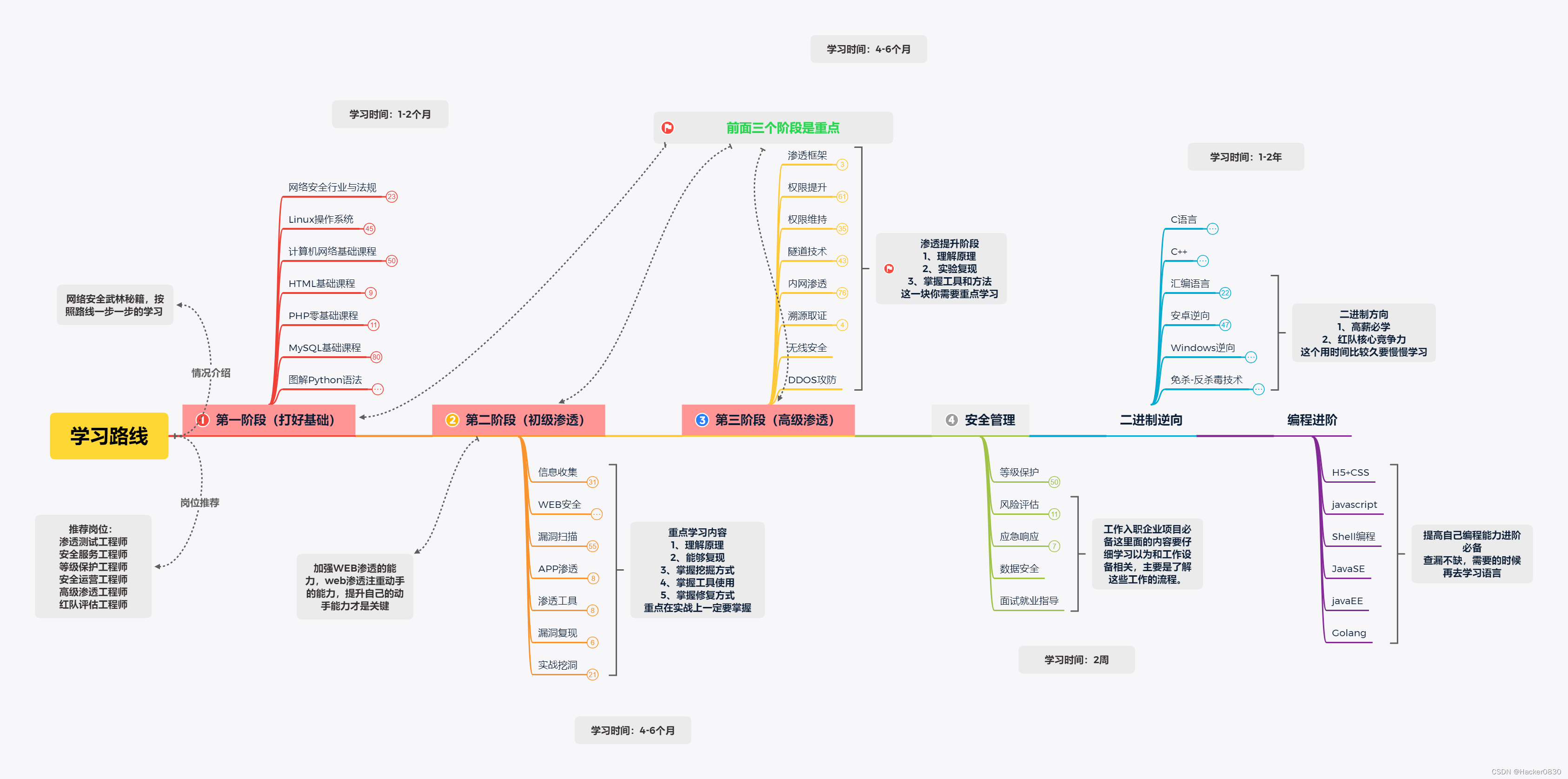
目录
1. 为什么使用文件
2. 什么是文件
2.1 程序文件
2.2 数据文件
2.3 文件名
3. 文件的打开和关闭💢
3.1 文件指针1️⃣
3.2 文件的打开和关闭2️⃣
⭕相对路径
⭕绝对路径
4. 文件的顺序读写
1.fputc写文件--字符输出函数
2.fgetc(pf)读文件--字符输入函数
3.fputs--文本行输出函数
4.fgets--文本行输入函数
5.fprintf--针对所有输出流(文件流/stdout)的格式化输出函数
6.fscanf -- 针对所有输入流(文件流/stdin)的格式化输入函数
为什么需要用到"流"?
stdin和stdout的适用情况
1.fgetc测试:
2.fputc测试:
3.fprintf测试:
4.fscanf测试:
7.sscanf和sprintf
前言:
这篇文章是关于文件是什么、文件的操作、文件的读写函数:fputc、fgetc、fputs、fgets、fprintf、
fscanf、sscanf和sprintf。以及流的概念,与为什么要使用到流,以及stdin和stdout的适用情况的知
识点总结,如有错误欢迎大佬指正,感谢您的支持!
1. 为什么使用文件
2. 什么是文件
2.1 程序文件
包括源程序文件( 后缀为.c ) , 目标文件( windows环境后缀为.obj ) , 可执行程序( windows环境后缀为.exe )。
2.2 数据文件
文件的内容不一定是程序,而是程序运行时读写的数据,比如程序运行需要从中读取数据的文件, 或者输出内容的文件。



2.3 文件名
一个文件要有一个唯一的文件标识,以便用户识别和引用。文件名包含3 部分:文件路径 +文件名主干+文件后缀例如: c:\code\test.txt -->意思是:c:\code\ 是文件路径,放在c盘底下的code文件夹底下的test,是文件名主干 .txt是文件后缀为了方便起见,文件标识常被称为文件名 。
3. 文件的打开和关闭💢
假设我要从冰箱里面拿冰棍-->打开冰箱,拿冰棍,关上冰箱
类比.-->如果想给文件存放数据,或者从文件里面拿数据:打开文件-->写或读数据(使用)-->关闭文件
最核心的是要知道文件如何打开和关闭:

3.1 文件指针1️⃣
当我们要操作一个文件,名为data.txt,要操作这个文件首先就要打开它,这个文件就正在被使用,而被使用的时候,这个文件就会在内存中维护一个 文件信息区(可以理解为一个结构体的变量)这个文件信息区跟文件(.txt)是关联的,是为了描述这个文件的, 文件信息区 里面放了( 文件的名字,文件状态及文件当前的位置等)
struct _iobuf {char * _ptr ;int _cnt ;char * _base ;int _flag ;int _file ;int _charbuf ;int _bufsiz ;char * _tmpfname ;};typedef struct _iobuf FILE;//FILE-->本质是一个结构体类型
不同的C编译器的FILE类型包含的内容不完全相同,但是大同小异:
意思是:(操作系统不同)不同的c编译器对于FILE结构体是怎么定义的是不相同的,windows对于文件的使用习惯、操作、文件后缀等等,跟linux、macos是不一样的,是由不同的研发团队、不同公司去开发的,所以在对FILE这个结构的定义都是有差异的
意思是: 这个变量就是对这个信息区的整合 信息区就是详细的解释
FILE * pf ; // 文件指针变量


3.2 文件的打开和关闭2️⃣
文件在读写之前应该先打开文件,在使用结束之后应该关闭文件

这里我要说一下这个打开方式的意思:例如以读的方式打开,就是说,根据拿到的这个文件指针, 只有读的权限,没有写的权限, 一般是和下面文件的输入输出函数是相对应的。
|
文件使用方式
|
含义
|
如果指定文件不存在
|
|
“r”(只读)
|
为了输入数据,打开一个已经存在的文本文件
|
出错
|
|
"w"(只写)
|
为了输出数据,打开一个文本文件 | 建立一个新的文件 |
|
“a”(追加)
|
向文本文件尾添加数据 | 建立一个新的文件 |
|
“rb”
(只读)
|
为了输入数据,打开一个二进制文件
|
出错
|
|
“wb”(只写)
|
为了输出数据,打开一个二进制文件 | 建立一个新的文件 |
|
“ab”
(追加)
|
向一个二进制文件尾添加数据
|
出错
|
|
“r+”
(读写)
|
为了读和写,打开一个文本文件
|
出错
|
|
“w+”
(读写)
|
为了读和写,建议一个新的文件
|
建立一个新的文件
|
|
“a+”
(读写)
|
打开一个文件,在文件尾进行读写
|
建立一个新的文件
|
|
“rb+”
(读写)
|
为了读和写打开一个二进制文件
|
出错 |
|
“wb+”
(读写)
|
为了读和写,新建一个新的二进制文件
|
建立一个新的文件
|
|
“ab+”
(读写)
|
打开一个二进制文件,在文件尾进行读和写
|
建立一个新的文件
|
实例代码:
#include<stdio.h>
int main()
{
//打开文件
//相对路径
FILE* pf = fopen("test.txt","w");//当打开test.txt,会在内存中创建一个文件信息区,
//这时是把文件信息区的地址放到pf里面去了,
if (pf == NULL) //pf可以通过地址找到这个文件对应的文件信息区,就可以操作这个文件
{
perror("fopen");
return 1;
}
//写文件
//关闭文件
fclose(pf);//不会把pf置为空指针,可以想象成一个变量,以值传递的形式,所以不能改掉pf
pf = NULL;
return 0;
}有两个该注意的点:
经过执行之后:

⭕相对路径
这个test.txt会新建出来,但是里面是没有内容的
fopen("test.txt","w")-->指定的名字test.txt,而且是在这个工程底下去搞得

打开看看:

但是这个时候如果写入东西:

再执行:

里面的内容就销毁掉了:

这时候换成fopen("test.txt", "r")看看
#include<stdio.h>
int main()
{
//打开文件
//相对路径
FILE* pf = fopen("test.txt", "r");//这个位置换成"r"
if (pf == NULL)
{
perror("fopen");
return 1;
}
//写文件//关闭文件
fclose(pf);//不会把pf置为空指针,可以想象成一个变量,以值传递的形式,所以不能改掉pf
pf = NULL;return 0;
}
返回值问题:


返回成功/失败


⭕绝对路径
如果在这个桌面上创建一个文件

右击属性找到路径:

实例代码:
#include<stdio.h>
int main()
{
//打开文件
//相对路径
FILE* pf = fopen("C:\\Users\\zzc\\Desktop\\test.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//写文件
//关闭文件
fclose(pf);//不会把pf置为空指针,可以想象成一个变量,以值传递的形式,所以不能改掉pf
pf = NULL;
return 0;
}留意一下:加多几条'\'的原因是把原来的'\'也转义了,因为中间有个'\t'
这个位置:"C:\Users\zzc\Desktop\test.txt"
说明一下:

如果原来的.txt里面有内容,经过执行以后:

会把原来的内容彻底销毁掉

4. 文件的顺序读写
这些函数的意义:一般与上面fopen的打开方式是相对应的,以什么打开方式就赋予了这个pf指针什么样的权限。
|
功能
|
函数名 | 适用于 |
|
字符输入函数
|
fgetc | 所有输入流 |
| 字符输出函数 | fputc | 所有输出流 |
|
文本行输入函数
|
fgets | 所有输入流 |
| 文本行输出函数 | fputs | 所有输出流 |
|
格式化输入函数
|
fscanf | 所有输入流 |
| 格式化输出函数 | fprintf | 所有输出流 |
|
二进制输入
|
fread | 文件 |
| 二进制输出 | fwrite | 文件 |
1.fputc写文件--字符输出函数
fputc('a' + i,pf);//此函数一次写一个字符,所以需要一个循环来输出26个字符

文献:

翻译:
 代码实例:
代码实例:
//fputc 写文件
#include<stdio.h>
int main()
{
FILE* pf = fopen("test.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//写文件
int ch = 0;
int i = 0;
for (i = 0; i < 26; i++)
{
fputc('a' + i,pf);//此函数一次写一个字符,ascll码值+1
}
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}
效果:

2.fgetc(pf)读文件--字符输入函数
ch = fgetc(pf);//此函数一次读取一个字符
可以看以下执行效果:

文献:

翻译:
 代码实例:
代码实例:
//fgetc - 读文件操作
#include<stdio.h>
int main()
{
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//读文件
//把26个字面写到文件中
int ch=0;//看上面的文献,所以为什么这个地方会用int接收
//printf("%c\n", ch);
int i = 0;
for (i = 0; i < 26; i++)
{
ch = fgetc(pf);//此函数一次读取一个字符
printf("%c ",ch);//ascll码值+1
}
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}代码执行:注意前提是这个文件里面有内容,否则不会输出任何东西

执行:

为什么pf不能++
 如果加入一行代码:pf++
如果加入一行代码:pf++

原因:对于文件指针进行++操作是不允许的,语法不支持
3.fputs--文本行输出函数
文献:

翻译:

代码实现:
//fputs 写一行数据
#include<stdio.h>
int main()
{
FILE* pf = fopen("test.txt", "w");//这里写文件名的话默认是在这个工程底下搞的,写成绝对路径或者其它相对路径,要指定
if (pf == NULL)
{
perror("fopen");
return 1;
}
//写一行数组 hello bit
fputs("hello bit\n", pf);
fputs("hello world\n", pf);
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
}输出不换行:
fputs("hello bit", pf);
fputs("hello world\n", pf);

输出换行: 上面的代码可参考

4.fgets--文本行输入函数
文献:

翻译:

代码实例:以下注释说明了为什么打印hell
//fgets - 读一行数据
int main()
{
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//读
char arr[20];
fgets(arr,5, pf);//在.txt文件有内容的情况下,这里的参数5说明最多读4个,最后一个位置是留给'\0'的
printf("%s\n", arr);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}执行:

5.fprintf--针对所有输出流(文件流/stdout)的格式化输出函数

与printf的区别:printf是针对标准输出流 (stdout) 的格式化的输出函数
假设要把struct S s = { 100,3.14f,"zhangsan" };信息打印出来那应该怎么写呢?
那就应该先写成printf("%d %f %s\n", s.n, s.f, s.arr);,然后在前面加个参数改成fprintf(pf,"%d %f %s\n", s.n, s.f, s.arr)即可
#include<stdio.h>
struct S
{
int n;
float f;
char arr[20];
};
int main()
{
struct S s = { 100,3.14f,"zhangsan" };
//打开文件
FILE* pf = fopen("test.txt", "w");
if (NULL == pf)
{
perror("fopen");
return 1;
}
//写文件
fprintf(pf, "%d %f %s\n", s.n, s.f, s.arr);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}
6.fscanf -- 针对所有输入流(文件流/stdin)的格式化输入函数
跟fprintf传的文件流指针是一样的

与scanf的区别:是针对标准输入流 (stdin)的格式化的输入函数
#include<stdio.h>
struct S
{
int n;
float f;
char arr[20];
};
int main()
{
struct S s = { 100,3.14f,"zhangsan" };
//打开文件
FILE* pf = fopen("test.txt", "w");
if (NULL == pf)
{
perror("fopen");
return 1;
}
//写文件
fscanf(pf, "%d %f %s",&(s.n),&(s.f),s.arr);//数组名arr是首元素地址,所以不需要取地址操作符
printf("%d %f %s\n", s.n, s.f, s.arr);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}执行:

为什么需要用到"流"?
前提:如何把数据写进入外部设备,需要对每一种外部设备的操作比较多的了解,例如数据是怎么写进入文件、屏幕、网络、打印机等外部设备,都得知道它们的实现细节(读和写的细节),对于程序员来说太难了。

流的概念: 这时候抽象化了一个概念“流”,"流"知道怎么把数据写进各种外部设备的细节,那对于程序员而言,要读取数据就从流里面读,要写数据就写到流里面就可以了,至于这个流怎么跟外部设备交互的是不需要关心的。
流的种类:
stdin标准输入流 stdou标准输出流 stderr标准错误流都是FILE*的指针

stdin和stdout的适用情况
回到前面的输入输出函数:
fgetc、fgets、fscanf均适用于文件流以及标准输入流 -- stdin
fputc、fputs、fprintf均适用于文件流以及标准输出流 -- stdout
1.fgetc测试:
#include<stdio.h>
int main()
{
int ch = fgetc(stdin);//输入
printf("%c\n", ch);
return 0;
}执行:以下是输入一个字符和输出的情况


2.fputc测试:
int main()
{
fputc('a', stdout);//输出
fputc('f', stdout);
fputc('g', stdout);
fputc('z', stdout);
return 0;
}执行:

3.fprintf测试:
int main()
{
struct S s = { 1000,3.666f,"hehe" };
fprintf(stdout,"%d %f %s\n",s.n,s.f,s.arr);
return 0;
}执行:

4.fscanf测试:
int main()
{
struct S s = { 0 };
fscanf(stdin, "%d %f %s",&(s.n),&(s.f),s.arr);
fprintf(stdout, "%d %f %s\n", s.n, s.f, s.arr);
}
7.sscanf和sprintf
sscanf文献

翻译:
 sprintf文献
sprintf文献

翻译:

sscanf--把字符串转换成格式化的数据
sprintf--把格式化的数据转换成字符串
struct S
{
int n;
float f;
char arr[20];
};
int main()
{
//序列化和反序列化
struct S s = { 200,3.5f,"wangwu" };
//把一个结构体转换成字符串
char arr[200] = { 0 };
sprintf(arr, "%d %f %s\n", s.n, s.f, arr);
printf("字符串的数据: %s\n", arr);
//把一个字符串转换成对应的格式化数据
struct S tmp = { 0 };
sscanf(arr, "%d %f %s", &(tmp).n, &(tmp.f), &tmp.arr);
printf("格式化的数据:%d %f %s\n", tmp.n, tmp.f, tmp.arr);
return 0;
}执行:
 文章来源:https://www.toymoban.com/news/detail-487781.html
文章来源:https://www.toymoban.com/news/detail-487781.html
关于文件操作的知识还有下半篇,欢迎大佬指正,感谢支持!文章来源地址https://www.toymoban.com/news/detail-487781.html
到了这里,关于【C进阶】文件操作(上)--(详解、非常适合基础入门学习)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[C语言进阶详解]文件操作(上)](https://imgs.yssmx.com/Uploads/2024/01/415011-1.png)