该算法已被很多篇文章讲解,本文将会去除很多较简单的内容,挑选认为重点核心部分进行讲述,内容中有属于信息的收集整理部分,也有属于自己理解的部分。
1、遗传算法概述
遗传算法是一类借鉴生物界的进化规律演化而来的随机化搜索方法。它是由美国的J.Holland教授1975年首先提出,其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,能自动获取和指导优化的搜索空间,自适应地调整搜索方向,不需要确定的规则。遗传算法的这些性质,已被人们广泛地应用于组合优化、机器学习、信号处理、自适应控制和人工生命等领域。它是现代有关智能计算中的关键技术之一。
2、遗传算法的基本操作
遗传算法有三个基本操作: 选择( Selection) 、 交叉( Crossover) 和变异( Mutation)
• 选择。 从当前种群中选出优良的个体, 使它们有机会作为父代种群为下一代种群进行更新迭代。 根据各个个体的适应度值, 按照一定的规则或方法从上一代群体中选择出一些优良的个体遗传到下一代种群中。 选择的依据是适应性强的个体为下一代贡献一个或多个后代的概率大。
• 交叉。 通过交叉操作可以得到新一代个体, 新个体组合了父辈个体的特性。 将群体中的各个个体随机搭配成对, 对每一个个体, 以交叉概率交换它们之间的部分染色体。
• 变异。 对种群中的每一个个体, 以变异概率改变某一个或多个基因座上的基因值为其他的等位基因。 同生物界中一样,变异发生的概率很低, 变异为新个体的产生提供了机会。
3、遗传算法的基本步骤
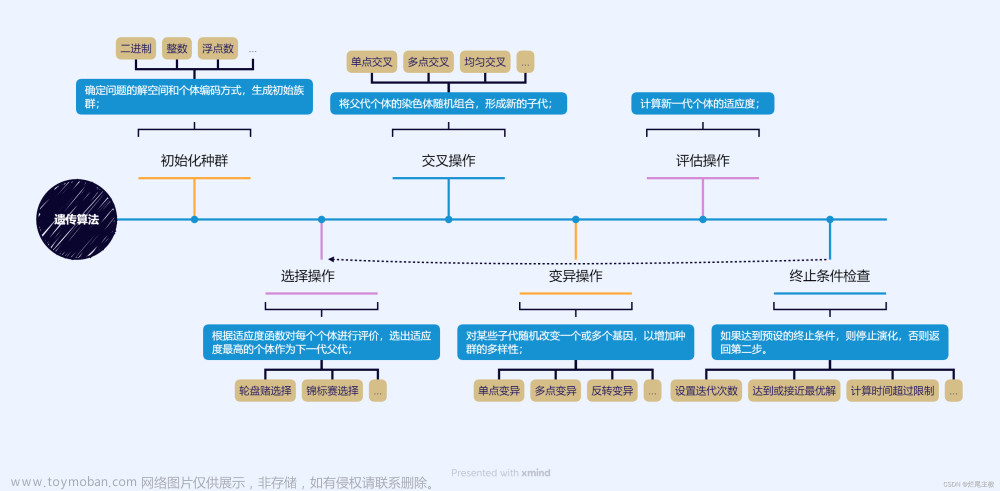
遗传算法的基本步骤包含了编码、解码、初始种群生成、适应度计算、选择、交叉、变异
1)编码: GA在进行搜索之前先将解空间的解数据表示成遗传空间的基因型串结构数据,
这些串结构数据的不同组合便构成了不同的点。
遗传算法的搜索核心是编码方式(遗传算子)的选择,因此对于遗传算法的研究,其中最常见的内容与方向是遗传算子,遗传算子的选择多样性也导致了算法表现的多样性,常见的选择方式如图所示:

常见的编码方式有:二进制编码、自然数编码、实数编码和树形编码等,常见的编码有二进制编码与自然数编码,很多实际问题如VRP调度问题更多采用自然数编码。(编码方式不赘述,根据模型需要自行选择即可)
2)初始群体的生成:随机产生N个初始串结构数据, 每个串结构数据称为一个个体, N个
个体构成了一个群体。
3)适应度评估:适应度表明个体或解的优劣性。 不同的问题, 适应性函数的定义不同。
4)选择:选择的目的是为了从当前群体中选出优良的个体。 选择体现了达尔文的适者生存原则。
常见的选择方式有:
轮盘赌法Roulette-wheel selection:
轮盘赌选择法是依据个体的适应度值计算每个个体在子代中出现的概率,并按照此概率随机选择个体构成子代种群。轮盘赌选择策略的出发点是适应度值越好的个体被选择的概率越大。

为了计算选择概率,需要用到每个个体i的适应度值:
从给定种群中选出M个个体就等价于旋转M次轮盘,在选择个体前实际上不必对种群中的个体进行排序。
锦标赛选择(Tournament selection)
在锦标赛选择中,从种群中随机采样s个个体(注意:采样是有放回的),然后选择最优的个体进入下一代,只有个体的适应度值优于其他s-1个竞争者时才能赢得锦标赛。注意最差的个体永远不会幸存,而最优的个体在其参与的所有锦标赛中都能获胜。

可以通过改变锦标赛的大小s来改变,对于较大的s值,弱者被选中的机会较小,常见的有二元锦标赛和三元锦标赛等。与适应度值比例选择相比,锦标赛选择由于缺乏随机噪声,同时锦标赛选择也和遗传算法适应度函数的尺度无关。
随机遍历选择(Stochastic-universal selection)
随机遍历选择(SUS)是一种根据给定概率以最小化波动概率的方式选择个体的方法。可以将其认为是一种轮盘赌游戏,在轮盘上有p个等间距的点进行旋转。SUS使用一个随机值在等间隔的空间间隔内选择来选择个体。相比较于适应度比例选择法,该方法中较劣个体也有很好的机会被选择,从而奖励了不公平性。该选择方法是由James Baker提出的,展示了其原理,其中n为要选择的个体数量。随机遍历采样保证了选出的子代,比轮盘赌法更加接近希望得到的结果。

精英选择(Elite selection)
精英选择将一小部分最优的候选解,原封不动的复制到下一代中,这会对性能产生巨大的影响,因为这保证了GA不会浪费时间重新发现以前拒绝的部分解。通过精英主义被保留下来的个体仍然有资格被选为下一代的父代。精英主义也与记忆有关:记住目前找到的最优解。不过精英主义的问题在于会导致GA收敛到局部最优,所以纯粹的精英主义是一场通向最近局部最优的竞争。
5)交叉:交叉操作是遗传算法中最主要的遗传操作。 通过交叉操作可以得到新一代个体,
新个体组合了其父辈个体的特性。
常见的交叉方式有:
单点交叉(Single-point crossover)
单点交叉通过选取两条染色体,在随机选择的位置点上进行分割并交换右侧的部分,从而得到两个不同的子染色体。

两点交叉(Two-points crossover)
两点交叉是指在个体染色体中随机设置了两个交叉点,然后再进行部分基因交换。两点交叉的具体操作过程是:
- 在相互配对的两个个体编码串中随机设置两个交叉点;
- 交换两个个体在所设定的两个交叉点之间的部分染色体。

部分匹配交叉(Partially-matched crossover,PMX)
部分匹配交叉保证了每个染色体中的基因仅出现一次,通过该交叉策略在一个染色体中不会出现重复的基因,所以PMX经常用于旅行商(TSP)或其他排序问题编码。
PMX类似于两点交叉,通过随机选择两个交叉点确定交叉区域。执行交叉后一般会得到两个无效的染色体,个别基因会出现重复的情况,为了修复染色体,可以在交叉区域内建立每个染色体的匹配关系,然后在交叉区域外对重复基因应用此匹配关系就可以消除冲突。
Step1:随机选择一对染色体(父代)中几个基因的起止位置(两染色体被选位置相同)。

Step2:交换这两组基因的位置。

Step3:做冲突检测,根据交换的两组基因建立一个映射关系,如图所示,以7-5-2这一映射关系为例,可以看到第二步结果中子代1存在两个基因7,这时将其通过映射关系转变为基因2,以此类推至没有冲突为止。最后所有冲突的基因都会经过映射,保证形成的新一对子代基因无冲突。

最终结果为:

还有其他的交叉方法,这里不一一举例说明。
6)变异:变异首先在群体中随机选择一个个体, 对于选中的个体以一定的概率随机地改变
串结构数据中某个串的值。
整体的流程如下:

4、案例分析
案例后续讲述
TSP优化
遗传算法优化神经网络
5、遗传算法特点
相对于传统算法而言,遗传算法有以下突出特点:
优点:
1). 可适用于灰箱甚至黑箱问题;
2). 搜索从群体出发,具有潜在的并行性;
3). 搜索使用评价函数(适应度函数)启发,过程简单;
4). 收敛性较强。
5). 具有可扩展性,容易与其他算法(粒子群、模拟退火等)结合。
不足:
1). 算法参数的选择严重影响解的品质,参数的选择大部分是依靠经验;
2). 遗传算法的本质是随机性搜索,不能保证所得解为全局最优解;文章来源:https://www.toymoban.com/news/detail-487784.html
3).在处理具有多个最优解的多峰问题时容易陷入局部最小值而停止搜索,造成早熟问题,无 法达到全局最优。文章来源地址https://www.toymoban.com/news/detail-487784.html
到了这里,关于智能优化算法之遗传算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![[多目标优化算法]1.NSGA-II——非支配排序遗传算法](https://imgs.yssmx.com/Uploads/2024/01/404492-1.png)



