一官方网址
1夜莺github网址:https://github.com/ccfos/nightingale

2这Flashcat官网:https://flashcat.cloud/

相关包下载可以在github的Releases里面下载也可以在Flashcat官网下载
夜莺的定位:定位类似于grafana。grafana更擅长看图,夜莺更擅长告警规则的管理(主打的多个团队权限的管理,项目的协同等等)
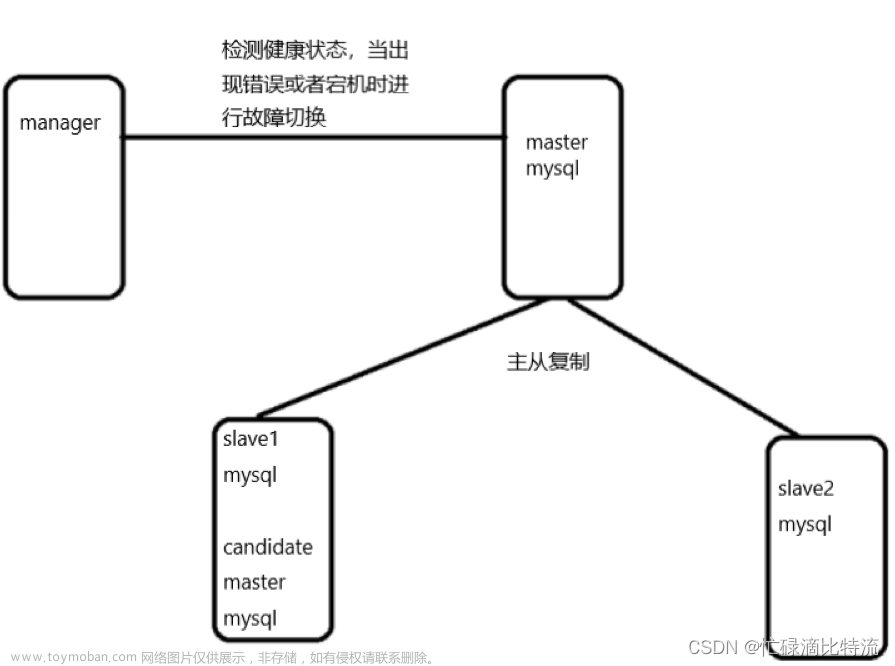
二夜莺V6架构
(一)中心汇聚式部署方案

-
Mysql:所有配置信息以及告警事件都存在mysql中,也可以用PG数据库
(prometheus的告警事件存在内存里面,重启之后可能历史告警没有了), - Redis:V6版本主要存验证信息(jwt token)一些机器的元信息(对象列表里面的那些信息)

3. 时序库:时序库除了 Prometheus,还可以使用 VictoriaMetrics、M3DB 等
4. LB:前面建议有个LB,一般是nginx做七层代理就可以,n9e是http的
5. n9e:v5版本是webapi和server两个模块,v6是合成一个,多个n9e搭多个实例就可以组成一个集群,分担告警处理,查询的压力。
n9e在通过promql查数据把请求proxy給时序库或者在配置大盘或告警写到mysql的逻辑中n9e是无状态的。不过n9e作为告警引擎的时候是有状态的,不过他会自动处理这个状态,比如lb后端有三个n9e,他们每个人处理100条告警规则的逻辑,当一个n9e挂掉了,它处理的100条告警规则运算逻辑会分配给另外两台(所以是可以直接扩容的)。
6. 数据流:categraf采集监控数据以及元数据(cpu架构,cpu,内存使用等),上报到LB,LB转发给n9e,n9e会把metadata的信息写到redis,还会从监控数据中提取ident的标签,如果是categraf采集的或者grafana agent采集的,服务器的标识是agent hostname,就会识别成一个机器,然后重命名成ident写到mysql里面target那个表里面去。
7. 接入其他的数据库:直接在页面上配datasource就可以了
8. 瓶颈:目前看瓶颈是在时序库,目前看性能最好的是vm数据库,具体看告警能承担多少量收到机器配置,网络带宽,io,数据查询频率等等。所以最好是做灰度自己测。
(二)边缘下沉式混杂部署方案

- 服务端部署同上
- 各个机房如果和中心网络链路不好,则把时序库、pushgw、alert下沉部署。categraf只把heartbeat继续发送到中心去,把metrics推到本地的时序数据库,n9e去查这部分数据就去机房本地的时序库去查,有可能会查询比较慢,不过数据丢失是不会有的,因为整个数据采集转发存储都是在机房内完成的。
并且中间需要通过n9e-pushgw模块,才能从数据中提取到ident机器信息写到target的表,就不会在对象列表看到这台机器,不过没有n9e-pushgw这个模块不影响告警和看图,不过会影响告警自愈(告警自愈依赖于对象列表的业务组来做权限的控制)。n9e-alert去做告警判断。 - 如果有部分categraf不能连通中心的lb,只需要在能连通中心lb的categraf机器上做一个nginx代理,让heartbeat地址写到nginx上,nginx代理中心端的n9e即可。
- 如果单独有个k8s集群,里面部署了promtheus做监控,如果这个机房到中心网络也不好,就会在prometheus边上部署n9e-alert,n9e-alert就会从mysql里面同步告警规则,去prometheus里面查询数据做告警判断。
三 二进制部署
步骤命令搬运自官网,其他部署方式也可见官网
https://flashcat.cloud/docs/content/flashcat-monitor/nightingale/install/first/
(一)部署数据库
- 夜莺安装依赖 mysql、redis,这两个组件都是开源软件
# install mysql
yum -y install mariadb*
systemctl enable mariadb
systemctl restart mariadb
mysql -e "SET PASSWORD FOR 'root'@'localhost' = PASSWORD('1234');"
# install redis
yum install -y redis
systemctl enable redis
systemctl restart redis
- 配置数据源(时序库)以VictoriaMetrics为例
下载地址:https://github.com/VictoriaMetrics/VictoriaMetrics/releases
单机版端口8428,每秒钟监控的数据点数小于100w,用单机的vm就足够了
带cluster的包是集群的,enterprise是企业版,类似选择 victoria-metrics-linux-amd64-v1.90.0.tar.gz是社区的单机版
#解压缩只有二进制的文件,是通过参数来调整配置,而没有配置文件.可以用systemctl管理
nohup ./victoria-metrics-prod &
特别注意VictoriaMetrics的单机和集群版在n9e的配置中url写法不同,见后面的n9e部署
(二)部署n9e
- 在官网把包下载下来,解压,配置,启动服务
mkdir -p /opt/n9e && cd /opt/n9e
# 去 https://github.com/ccfos/nightingale/releases 找最新版本的包,文档里的包地址可能已经不是最新的了
tarball=n9e-v6.0.0-ga.4.0.1-linux-amd64.tar.gz
urlpath=https://download.flashcat.cloud/${tarball}
wget $urlpath || exit 1
tar zxvf ${tarball}
#进入解压目录 导入n9e数据库文件
mysql -uroot -p1234 < n9e.sql
- 配置,启动服务
#可以进入解压目录下的etc/config.toml,修改服务默认端口以及数据库的连接地址配置(特别注意VictoriaMetrics的单机和集群版配置url写法不同)
[[Pushgw.Writers]]
#集群版VictoriaMetrics配置
# Url = "http://127.0.0.1:8480/insert/0/prometheus/api/v1/write"
#单机版ictoriaMetrics配置
# Url = "http://127.0.0.1:9090/api/v1/write"
#注意一定要修改配置文件中的HTTP各个部分的BasciAuth
#启动服务
nohup ./n9e &> n9e.log &
# check logs tail ./n9e.log
#如果启动成功,n9e 默认会监听在 17000 端口。上面使用 nohup 简单演示,生产环境建议用 systemd 托管
- 夜莺服务端部署好之后,浏览器访问 17000(默认用户是 root,密码是 root.2020) 就可以体验相关功能了,然后修改默认密码
- 添加数据源,添加完数据源有数据推上来,就可以做查询和告警了


(三)部署categraf
- 去官网下载categraf的压缩包,解压
- 修改categraf配置
#在目标机器部署,只需要 categraf 二进制、以及 conf 目录,
#conf 下有一个主配置文件:config.toml,定义机器名、全局采集频率、全局附加标签、remote write backend地址等;另外就是各种采集插件的配置目录,以input.打头,如果某个采集器 xx 不想启用,把 input.xx 改个其他前缀(或者删除这个目录),比如 bak.input.xx,categraf 就会忽略这个采集器。
vim config.toml
#修改n9e的地址,通过这个地址来推数据
[[writers]]
url = "http://127.0.0.1:17000/prometheus/v1/write"
#修改heartbeat为true,里面的地址改成n9e的地址,通过这个地址来心跳
[heartbeat]
enable = true
# report os version cpu.util mem.util metadata
url = "http://127.0.0.1:17000/v1/n9e/heartbeat"
-
配置数据源文章来源:https://www.toymoban.com/news/detail-487884.html
-
启动categraf,启动成功之后文章来源地址https://www.toymoban.com/news/detail-487884.html
#启动前测试
./categraf --test --debug
#启动categraf.可以用nohup,不过最好可以用systemctl 托管
nohup ./categraf &
#启动成功之后,在web页面里面的对象列表可以看到这台机器(因为上面的heartbeat的配置,heartbeat的配置会上报redis,然后从redis里面读的)
- 配置完categraf数据采集之后,能查到数据即正常

四n9e配置文件config.toml
[Global]
RunMode = "release"
[Log]
#Output 改成file日志就会输出到Dir对应的目录中,需要配置日志切割,按照KeepHours的时间进行切割,KeepHours= 4就是保存4个小时的日志。或者按照大小来切分,RotateNum = 3 和RotateSize = 256 就是每个日志大小256m,保存3个
# log write dir
Dir = "logs"
# log level: DEBUG INFO WARNING ERROR
Level = "DEBUG"
# stdout, stderr, file
Output = "stdout"
# # rotate by time
# KeepHours= 4
# # rotate by size
# RotateNum = 3
# # unit: MB
# RotateSize = 256
[HTTP]
# http listening address
Host = "0.0.0.0"
# http listening port
Port = 17000
# https cert file path
CertFile = ""
# https key file path
KeyFile = ""
# whether print access log
PrintAccessLog = false
# whether enable pprof
PProf = false
# expose prometheus /metrics?
ExposeMetrics = true
# http graceful shutdown timeout, unit: s
ShutdownTimeout = 30
# max content length: 64M
MaxContentLength = 67108864
# http server read timeout, unit: s
ReadTimeout = 20
# http server write timeout, unit: s
WriteTimeout = 40
# http server idle timeout, unit: s
IdleTimeout = 120
下面这些BasicAuth接口的认证信息注意改一下
[HTTP.Pushgw]
Enable = true
# [HTTP.Pushgw.BasicAuth]
# user001 = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
[HTTP.Alert]
Enable = true
[HTTP.Alert.BasicAuth]
user001 = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
[HTTP.Heartbeat]
Enable = true
# [HTTP.Heartbeat.BasicAuth]
# user001 = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
[HTTP.Service]
Enable = true
[HTTP.Service.BasicAuth]
user001 = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
[HTTP.JWTAuth]
# signing key 注意改一下
SigningKey = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# unit: min
AccessExpired = 1500
# unit: min
RefreshExpired = 10080
RedisKeyPrefix = "/jwt/"
[HTTP.ProxyAuth]
# if proxy auth enabled, jwt auth is disabled
Enable = false
# username key in http proxy header
HeaderUserNameKey = "X-User-Name"
DefaultRoles = ["Standard"]
[DB]
# postgres: host=%s port=%s user=%s dbname=%s password=%s sslmode=%s
# 下面是mysql的dsn。上面是postgres的dsn写法
DSN="root:1234@tcp(127.0.0.1:3306)/n9e_v6?charset=utf8mb4&parseTime=True&loc=Local&allowNativePasswords=true"
# enable debug mode or not
Debug = false
# mysql postgres
DBType = "mysql"
# unit: s
MaxLifetime = 7200
# max open connections
MaxOpenConns = 150
# max idle connections
MaxIdleConns = 50
# table prefix
TablePrefix = ""
# enable auto migrate or not
# EnableAutoMigrate = false
[Redis]
# address, ip:port or ip1:port,ip2:port for cluster and sentinel(SentinelAddrs) ga3可以支持集群版
Address = "127.0.0.1:6379"
# Username = ""
# Password = ""
# DB = 0
# UseTLS = false
# TLSMinVersion = "1.2"
# standalone cluster sentinel
RedisType = "standalone"
# Mastername for sentinel type
# MasterName = "mymaster"
# SentinelUsername = ""
# SentinelPassword = ""
[Alert]
[Alert.Heartbeat]
# auto detect if blank,为空会自动探测
IP = ""
# unit ms 告警引擎的心跳时间,默认1000ms。多个n9e分摊告警的匹配,对全量的告警引擎中心端的心跳机制
Interval = 1000
ClusterName = "default"
# [Alert.Alerting]
# NotifyConcurrency = 10
[Center]
MetricsYamlFile = "./etc/metrics.yaml"
I18NHeaderKey = "X-Language"
[Center.AnonymousAccess]
#是不是可以匿名访问时序数据的接口,可以匿名访问告警事件的详情页面,为了安全性可以改成false
PromQuerier = true
AlertDetail = true
[Pushgw]
# use target labels in database instead of in series
LabelRewrite = true
# # default busigroup key name
# BusiGroupLabelKey = "busigroup"
# ForceUseServerTS = false
# [Pushgw.DebugSample]
# ident = "xx"
# __name__ = "xx"
# [Pushgw.WriterOpt]
# # Writer Options
# QueueCount = 1000
# QueueMaxSize = 1000000
# QueuePopSize = 1000
# # ident or metric
# ShardingKey = "ident"
[[Pushgw.Writers]]
# Url = "http://127.0.0.1:8480/insert/0/prometheus/api/v1/write"
Url = "http://127.0.0.1:9090/api/v1/write"
# Basic auth username
BasicAuthUser = ""
# Basic auth password
BasicAuthPass = ""
# timeout settings, unit: ms
Headers = ["X-From", "n9e"]
Timeout = 10000
DialTimeout = 3000
TLSHandshakeTimeout = 30000
ExpectContinueTimeout = 1000
IdleConnTimeout = 90000
# time duration, unit: ms
KeepAlive = 30000
MaxConnsPerHost = 0
MaxIdleConns = 100
MaxIdleConnsPerHost = 100
## Optional TLS Config
# UseTLS = false
# TLSCA = "/etc/n9e/ca.pem"
# TLSCert = "/etc/n9e/cert.pem"
# TLSKey = "/etc/n9e/key.pem"
# InsecureSkipVerify = false
# [[Writers.WriteRelabels]]
# Action = "replace"
# SourceLabels = ["__address__"]
# Regex = "([^:]+)(?::\\d+)?"
# Replacement = "$1:80"
# TargetLabel = "__address__"
到了这里,关于夜莺n9e监控V6架构以及部署(Nightingale)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!