大型“指令调优”语言模型在新任务上展现了Zero-shot的卓越能力,但严重依赖于人类编写的指令数据,而这些数据在数量、多样性和创造性方面都是有限的。
斯坦福科研人员引入了self-instruction框架,提高指令遵循能力来自我迭代进化,与InstructGPT的性能相当,相比原始GPT3提升33%!将大模型与指令对齐再也不用人工标注(annotation-free),最后还发布了他们合成的自生成指令数据集,来促进对指令调优的研究。
自我指示self-instruct
self-instruct是一种任务不可知(task-agnostic)的方法,通过自己生成指令数据(指令、输入和输出样本)并使用它进行引导来提高语言模型的指令遵循能力。
自动指示执行的流程:
首先准备好一个小的任务种子集(每个任务的一条指令和一个输入-输出实例)作为任务池开始,从任务池中抽取随机任务用于提示语言模型LM(例如GPT3)生成新的指令和实例,再过滤低质量或类似的生成,合格的就添加回任务池。
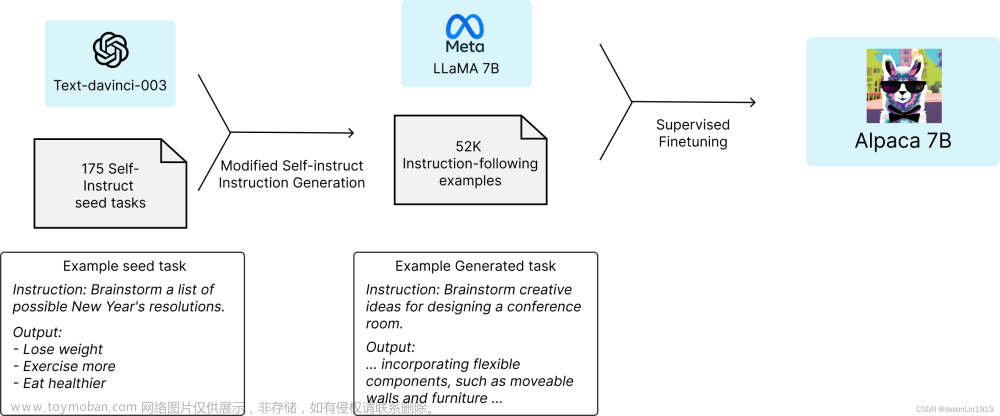
羊驼Alpaca模型
指令遵循语言模型叫Alpaca羊驼,是在近期Meta开源的LLaMA 7B模型上进行微调的。语料使用的是text-davinci-003生成的52K指令。stanford_alpaca在GitHub开源,地址见文末。
整体流程图:
训练过程中,使用了完全分片数据并行(Fully Sharded Data Parallel) 和混合精度(mixed precision) 等训练等技术,硬件方面:在8个80GB A100上对7B LLaMA模型进行微调3个小时,成本竟然不到100美元!但效果惊人,与InstructGPT_001的性能相当。
数据集合评估方法
52k数据集分布:
模型评估
采用四级评级系统,用于分类模型输出的质量,定义如下:
A: 回答是有效和令人满意的
B:响应是可以接受的,但有一些小错误或缺陷可以改进
C:响应是相关的,并响应指令,但它在内容中有重大错误。
D:响应不相关或无效,包括重复输入,完全不相关的输出等。
首发原文链接:文章来源:https://www.toymoban.com/news/detail-487947.html
自驱力超强的羊驼?斯坦福Alpaca媲美text-davinci-003,成本不到600美元!文章来源地址https://www.toymoban.com/news/detail-487947.html
到了这里,关于自驱力超强的羊驼?斯坦福微调LLaMa的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!