💘When Segment Anything Model Meets Stable Diffusion 💘
Encountering each other was not easy, like two ships passing in the night.
一是分割,一是扩散, 虚实相遇,展现技艺, 惊艳瞬间,于图像中留存。
分割模型准确标注像素, 各类物体,赋予其定位,
扩散模型再赋自然细节, 恰似画家,笔划流转。
于静态画面中变幻衍生, 动态图像中亦趣味无穷,
深度学习算法,为其带来新趣, 创造更多可能,亦更增益饱满。🍓🍓
【应用体验中心:https://aistudio.baidu.com/aistudio/projectdetail/6300584?contributionType=1】
| 💐 初识 💐 | ❣️ 相遇 ❣️ | 💘 相知 💘 |
|---|---|---|
 |
 |
 |
 |
 |
 |
❣️‼️ 相遇之美,犹如一场奇妙的奇迹,让我们慢慢品味并渐渐珍惜。每次想起这个美好的瞬间,我们心中都荡漾着无限的喜悦。在那一瞬间,时空都仿佛静止了下来,所有的细节都变得那么清晰而美好。相遇时的那份欢喜,仿佛让世界都变得更加美好、正义与和平,我们因此更加珍视和感恩这个难得的缘分。❣️‼️
🧡ིྀ SAM与SD的初识 🧡ིྀ
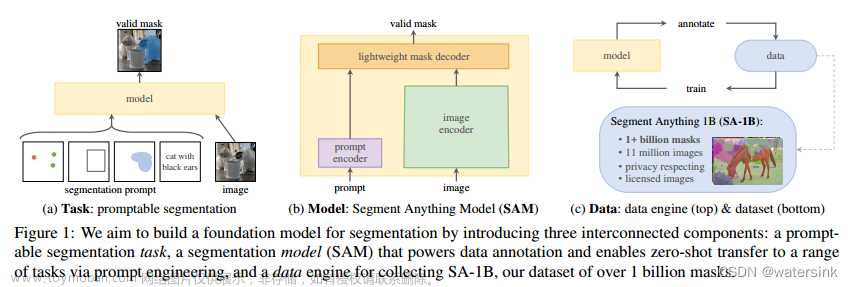
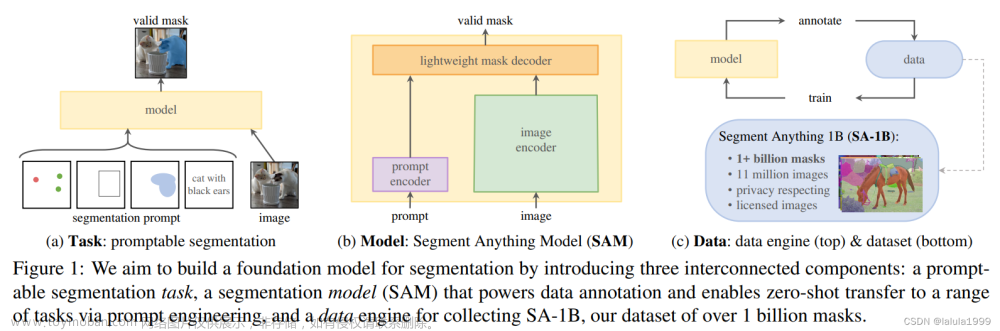
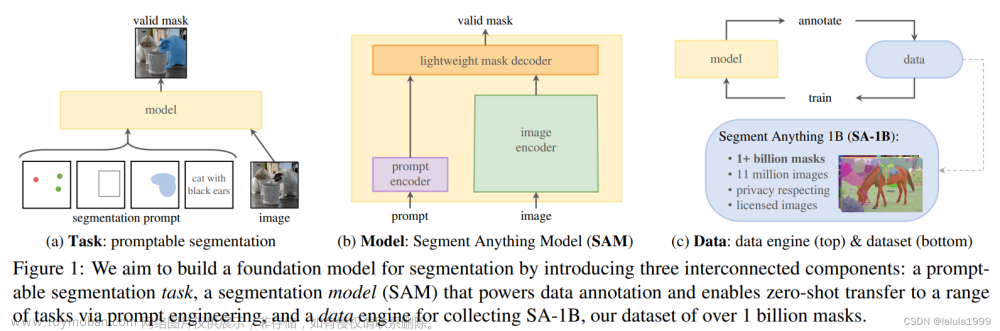
 Segment Anything Model(SAM)
Segment Anything Model(SAM)
🌸 Meta AI在四月发布了一个视觉分割领域的基础模型,叫做Segment Anything Model,简称SAM。这个模型主要是使用提示工程来训练一个根据提示进行分割的预训练大模型,该模型具有在下游分割任务应用的潜力,并且可以与其他视觉任务组合形成其他视觉任务的新解决方案。
【论文阅读传送门】

🌸 任务:
在自然语言处理和最近的计算机视觉领域,基础模型是一个有希望的发展,可以通过“提示”技术为新的数据集和任务实现零样本学习和少样本学习。受此工作激发,作者提出了可提示的分割任务,其目的是给定任何分割提示返回一个有效的分割掩码。一个提示简单地指定在图像中要分割的内容,一个提示可以包括识别对象的空间或文本信息。有效输出掩码的要求意味着即使一个提示是模棱两可的,可能指多个对象,输出应至少是这些对象之一的合理掩码。作者将可提示的分割任务用作预训练目标和通过提示工程解决一般下游分割任务。
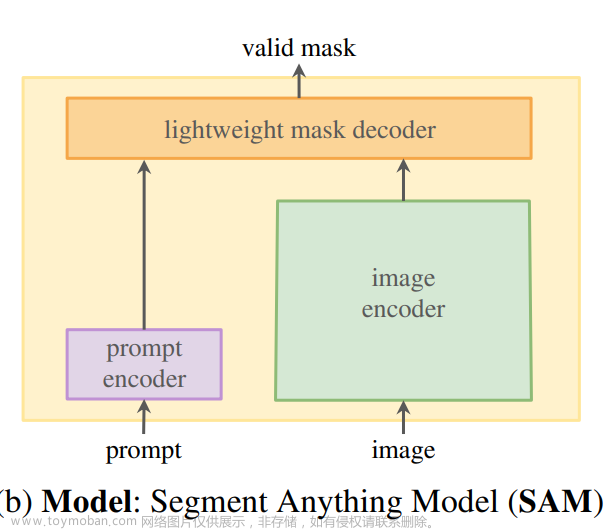
🌸 模型:
可提示的分割任务和实用目标对模型架构提出了约束。特别是,该模型必须支持灵活的提示,需要在摊销实时内计算掩码以允许交互使用,并且必须考虑歧义。一个简单的设计满足所有三个约束:一个强大的图像编码器计算图像嵌入、一个提示编码器嵌入提示、然后两个信息源在一个轻量级的掩码解码器中组合,该解码器预测分割掩码。作者将此模型称为SAM。通过将SAM分离为图像编码器和快速提示编码器/掩码解码器,可以对不同的提示重用相同的图像嵌入。给定图像嵌入,提示编码器和掩码解码器从提示中预测掩码,在网页浏览器中约为50毫秒。作者关注点、框和掩码提示,并且也提出了基于自由文本提示的初步结果。为了使SAM考虑歧义,作者设计它来为单个提示预测多个掩码,允许SAM自然地处理歧义。
🌸 数据引擎:
为了实现对新的数据分布的强大泛化,作者发现有必要在超出任何现有分割数据集的大型且多样的掩码集上训练SAM。虽然基础模型的典型方法是在线获得数据,但掩码并非自然丰富,因此我们需要另一种策略。作者的解决方案是构建一个“数据引擎”,即作者与模型内循环数据集注释共同开发我们的模型。作者的数据引擎有三个阶段:辅助手动、半自动和全自动。在第一阶段,SAM协助注释者注释掩码,类似于经典的交互分割设置。在第二阶段,SAM可以通过提示它可能的对象位置自动生成部分对象的掩码,注释者则注释剩余对象,有助于增加掩码的多样性。在最后阶段,作者使用前景点的规则网格提示SAM,平均产生每幅图像带有约100个高质量掩码。

🌸 数据集:
作者最终的数据集SA-1B包括1100万张获得许可和保护隐私的图像,一共的标注超过10亿个掩码。SA-1B使用作者的数据引擎的最后阶段完全自动收集,其掩码数量是任何现有分割数据集的400倍,而且正如作者广泛验证的那样,这些掩码具有高质量和多样性。除了用于训练SAM以使其健壮和通用外,作者希望SA-1B成为研究者构建新基础模型的有价值资源。
🌸 人工智能公平性:
作者研究并报告使用SA-1B和SAM可能出现的公平性担忧和偏见。SA-1B中的图像跨越地理上和经济上不同的国家,作者发现SAM在不同人群之间的性能相似。总的来说,作者希望这将使他们的工作对真实世界的用例更加公平。
🌸 实验:
作者广泛评估SAM。首先,使用23个新的多样化分割数据集,作者发现SAM从单个前景点产生高质量掩码,其质量通常仅略低于手动注释的真实标注。其次,作者发现在零样本迁移下使用提示工程在各种下游任务上获得持续强劲的定量和定性结果,包括边缘检测、目标提议生成、实例分割以及文本到掩码预测的初步探索。这些结果表明,SAM可以直接与提示工程配合使用来解决各种任务,这些任务涉及SAM训练数据之外的对象和图像分布。
Stable Diffusion(SD)
🌸 Stable Diffusion是一个文本到图像的潜在扩散模型,由CompVis、Stability AI和LAION的研究人员和工程师创建。它使用来自LAION-5B数据库子集的512x512图像进行训练。使用这个模型,可以生成包括人脸在内的任何图像,因为有开源的预训练模型,所以我们也可以在自己的机器上运行它。
🌸 论文地址
【论文阅读传送门】

🌸 论文贡献
* Diffusion model相比GAN可以取得更好的图片生成效果,然而该模型是一种自回归模型,需要反复迭代计算,因此训练和推理代价都很高。论文提出一种在潜在表示空间(latent space)上进行diffusion过程的方法,从而能够大大减少计算复杂度,同时也能达到十分不错的图片生成效果。
* 相比于其它空间压缩方法,论文提出的方法可以生成更细致的图像,并且在高分辨率图片生成任务(如风景图生成,百万像素图像)上表现得也很好。
* 论文将该模型在无条件图片生成(unconditional image synthesis), 图片修复(inpainting),图片超分(super-resolution)任务上进行了实验,都取得了不错的效果。
* 论文还提出了cross-attention的方法来实现多模态训练,使得条件图片生成任务也可以实现。论文中提到的条件图片生成任务包括类别条件图片生成(class-condition), 文图生成(text-to-image), 布局条件图片生成(layout-to-image)。这也为日后Stable Diffusion的开发奠定了基础。
💛ྀི SAM与SD的相遇 💛ྀི
Segment Anything Model与Stable Diffusion的相遇不是意外。🌈
🍒 ControlNet 是一种通过添加额外条件来控制扩散模型的神经网络结构。ControlNet with Stable Diffusion预训练模型
除文本提示外,ControlNet还需要一个控制图作为控制条件。每个预训练模型使用不同的控制方法进行训练,其中每种方法对应一种不同的控制图。例如,Canny to Image要求控制图像是Canny边缘检测的输出图像,而Pose to Image要求控制图是OpenPose骨骼姿态检测图像。而Segment Anything Model与Stable Diffusion的相遇则是Segment to Image要求控制图是分割图像。【源码参考自PaddleNLP中的ppdiffusers】
ControlNet with Stable Diffusion尝试
# 安装paddlenlp和ppdiffusers依赖
!pip install "paddlenlp>=2.5.2" "ppdiffusers>=0.11.1" safetensors --user
Canny to Image–采用Canny边缘检测图片作为控制条件
!python gradio_canny2image.py

Semantic Segmentation to Image–采用ADE20K分割协议的图片作为控制条件
!python gradio_seg2image_segmenter.py

Segment Anything Model与Stable Diffusion撞了个满怀。🌈
🍒 通过Segment Anything Model强大的图像分割能力,我们可以很好的得到分割后的像素图。然后由ControlNet with Stable Diffusion将控制图为不同语义的分割图和文本(prompt)作为控制条件来完成Segment to Image任务。这样Segment Anything Model通过ControlNet与Stable Diffusion撞了个满怀。【源码参考自PaddleSeg中的sam】
Segment Anything Model初尝试
# 安装依赖
!pip install ftfy regex
!pip install -r requirements.txt --user
# 下载样例图片
!mkdir ~/examples
%cd ~/examples
!wget https://paddleseg.bj.bcebos.com/dygraph/demo/cityscapes_demo.png
# 下载分词表
%cd ~
!wget https://bj.bcebos.com/paddleseg/dygraph/bpe_vocab_16e6/bpe_simple_vocab_16e6.txt.gz
# 运行脚本
n
# 运行脚本
!python scripts/text_to_sam_clip.py --model-type vit_h
可以去应用中心体验此项目:
💗 SAM与SD的相知 💗
☀️ 精美作品
| 💐 初识 💐 | ❣️ 相遇 ❣️ | 💘 相知 💘 |
|---|---|---|
 |
 |
 |
🌙 优秀作品
| 💐 不是意外 💐 | ❣️ 初次相识 ❣️ | 💘 撞了满怀 💘 |
|---|---|---|
| Text | Text | Text |
💌 SAM与SD的守护 💌
 Segment Anything Model与Stable Diffusion的守护需要你们,欢迎各位小伙伴来投稿,每周都将会精选出优秀的作品,展示与本页面和应用的首页。(作品可以提交至评论区下方,包括初识、相遇与相知对应的图像,以及调参过程中设置的Prompt、add_prompt以及navigate_prompt。)
Segment Anything Model与Stable Diffusion的守护需要你们,欢迎各位小伙伴来投稿,每周都将会精选出优秀的作品,展示与本页面和应用的首页。(作品可以提交至评论区下方,包括初识、相遇与相知对应的图像,以及调参过程中设置的Prompt、add_prompt以及navigate_prompt。)
文章来源:https://www.toymoban.com/news/detail-488163.html
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.文章来源地址https://www.toymoban.com/news/detail-488163.html
到了这里,关于When Segment Anything Model Meets Stable Diffusion的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!