©PaperWeekly 原创 · 作者 | 缥缈孤鸿影

引言
ChatGPT 的横空出世,在整个自然语言处理乃至人工智能领域均掀起波澜。不同于普通的闲聊式机器人和任务型智能客服仅局限于固定场景,ChatGPT 具有相当丰富的知识储备,对于很多冷门的知识,它亦能对答如流,堪称当代“百晓生”。因此,将语言模型与知识结合具有很高的研究价值,更强的知识性也标志着模型更加智能。本文先讲述预训练语言模型与知识的关系,再阐述在对话系统中引入外部知识的原因和做法等方面,对基于知识的对话模型作简单综述。

海纳百川——大语言模型也是知识库
一个知识库通常包含结构化或半结构化数据,例如实体、属性和关系,在人工构造知识库时往往也需要繁琐的工程技术和人工标注。相比之下,语言模型是基于自然语言文本的统计模型,只需投入大量无标签文本语料就可以学习语言的规律和模式,然后利用这些规律和模式来生成文本或者回答关于文本的问题。
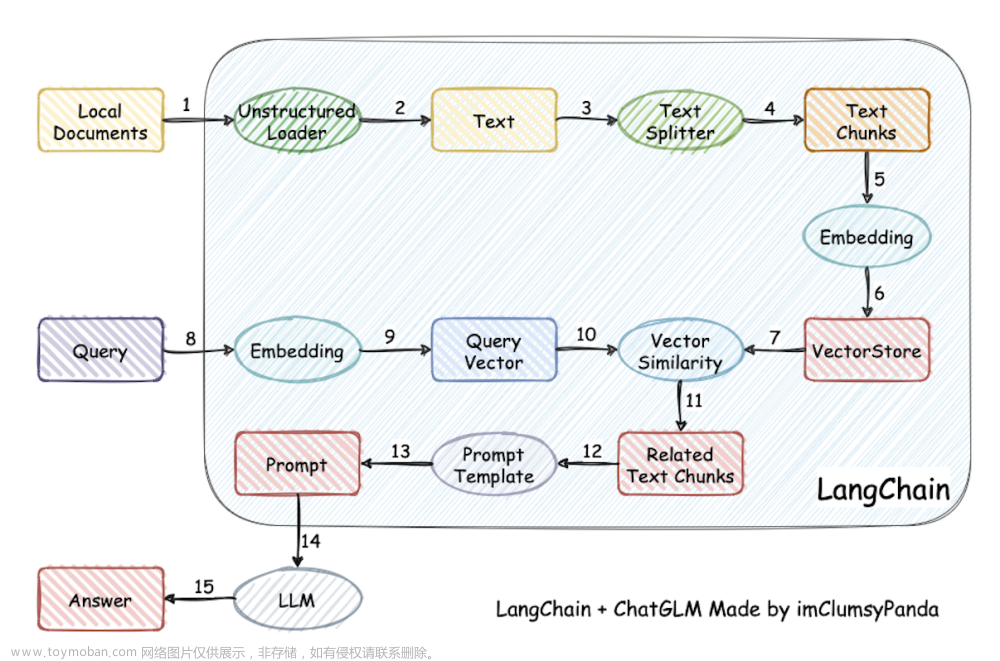
现在百花齐放的大语言模型如 BERT,GPT 等,都是在大量的文本数据上预训练过的,这已成为主流范式。维基百科,Reddit、知乎等论坛,推特、微博等媒体,都提供了海量的文本数据,语言模型把这些文本信息以参数化的形式存储。文章 [1] 以完形填空的形式对语言模型包含的知识进行探索,如下图所示,在实体-属性-关系形式的三元组数据集上验证,得出语言模型学习到并存储了一些事实知识。
尽管语言模型不能像知识库那样提供明确的实体、属性和关系等结构化信息,但它们可以通过学习文本信息来获取知识,比如学习单词之间的语义关系,理解句子的结构和含义,识别实体和事件等。再将这样的知识库应用于下游任务,相比传统方法得到显著提升。

▲ Figure 1: 语言模型中的事实知识在填空任务的表现 [1]
2.1 语言模型学到了哪些知识
语言模型从海量文本语料中学习了大量知识,文章 [1] 指出语言模型除了学习到语言学知识外,还学到了大量世界性知识(或称事实知识)。
语言学知识主要包括单词之间的语义关系(比如词法、词性等),以及句子的结构和语法规则,从而理解自然语言。同图像领域中低层的神经网络通常学习轮廓等低维通用特征一样,Transformer 为基础的大语言模型也是在低层存储这些语言学知识,这也是将预训练模型在下游任务上微调时将 Adapter 等结构加到上层网络的缘故。文章来源:https://www.toymoban.com/news/detail-488654.html
世界性知识就是我们通常认定的一些客观事实,比如实体和事件的识别,语言模型可以学习到如何识别文本中的人名、地名、时间、事件等实体信息;也比如一些抽象的情感特征,文本分类和主题模型等,在新闻摘要、产品评论分类、社交媒体评论分类等任务上均可胜任。文章来源地址https://www.toymoban.com/news/detail-488654.html
到了这里,关于大语言模型也是知识库:基于知识的对话大模型综述的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!