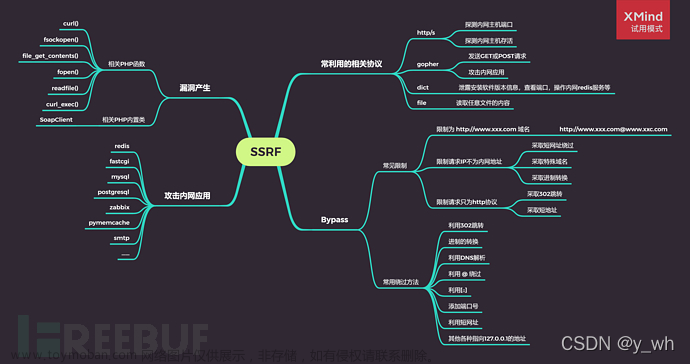
一、SSRF漏洞基础
1、漏洞原理与防御方法
1) 漏洞原理
SSRF的形成大多是由于服务端提供了从其他服务器应用获取数据的功能,并且没有对目标地址做过滤与限制。例如,黑客操作服务端从指定URL地址获取网页文本内容,加载指定地址的图片等,利用的是服务端的请求伪造。
2)防御方法
-
过滤返回信息,验证远程服务器对请求的响应是比较容易的方法。如果web应用是去获取某一种类型的文件。那么在把返回结果展示给用户之前先验证返回的信息是否符合标准。
-
统一错误信息,避免用户可以根据错误信息来判断远端服务器的端口状态。
-
限制请求的端口为http常用的端口,比如,80,443,8080,8090。
-
黑名单内网ip。避免应用被用来获取内网数据,攻击内网。
-
禁用不需要的协议。仅仅允许http和https请求。可以防止类似于file:///,gopher://,ftp:// 等引起的问题。
2、引发函数与漏洞场景
1)常见的引发SSRF的函数
- curl(): 用于执行指定的CURL会话,支持的协议比较多,常用于SSRF的协议经过测试都支持,如dict,ghoper,file。
- file_get_contengt(): 把文件写入字符串,当把url是内网文件的时候,会先去把这个文件的内容读出来再写入,导致了文件读取
- fopen(): 打开一个文件
- readline():打开一个文件,并按行读取内容
2)常见的漏洞场景
- 社交分享功能:获取超链接的标题等内容进行显示
- 转码服务:通过URL地址把原地址的网页内容调优使其适合手机屏幕浏览
- 在线翻译:给网址翻译对应网页的内容
- 图片加载/下载:例如富文本编辑器中的点击下载图片到本地;通过URL地址加载或下载图片
- 图片/文章收藏功能:主要其会取URL地址中title以及文本的内容作为显示以求一个好的用具体验
- 网站采集,网站抓取的地方:一些网站会针对你输入的url进行一些信息采集工作
- 从远程服务器请求资源(upload from url 如discuz!;import & expost rss feed 如web blog;使用了xml引擎对象的地方 如wordpress xmlrpc.php)
- …
3、常见的利用场景
0) 前置知识:常用协议
| 伪协议 | allow_url_fopen | allow_url_incude | 其他说明 |
|---|---|---|---|
| php://input | on/off | on | 在POST请求中访问POST的data部分,在enctype="multipart/form-data" 的时候php://input 是无效的。 |
| php://filter | on/off | on/off | 常用与读取源码,读取内容经过Base64编码输出 |
| file:// | on/off | on/off | 读取本地文件 |
| data:// | on | on | 自PHP>=5.2.0起,可以使用data://数据流封装器,以传递相应格式的数据。通常可以用来执行PHP代码。 |
| http:// & https:// | on | on/off | 发起http或者https请求 |
| gopher:// | on/off | on/off | 使用TCP的70端口,www之前的主流协议,支持发出GET、POST请求。使用要求为 PHP > v5.3, Java JDK < v1.7 |
| dict:// | on/off | on/off |
1)读取本地文件
读取本地文件,常用的方法就是使用file://,php://等伪协议进行读取。下面是两个读取本地文件的示例:
?file=file:///etc/passwd
?file=php://filter/read=convert.base64-encode/resource=C://windows/win.ini
2)内网IP、端口探测
在SSRF漏洞中,dict协议与http协议可以用来探测内网主机存活与端口开放情况。
eg: ?url=dict://127.0.0.1:8000
这种情况,我们就可以通过bursuite的intruder的暴力破解模块,来进行测试,通过响应结果的长度或者响应时间来判断。
3)攻击内网web程序
攻击内网web程序,通常用gopher协议进行,当然也可以使用http或者https协议,但是http协议通常只能对内网应用发起GET型的请求,应用面比较局限。
4)攻击内网可未授权利用的应用
常见的利用方法就是攻击内网的redis、postgrasql、MongoDB、Fast-CGI等。
4、常见的防御绕过方法
1)DNS重绑定
原理:攻击者控制了或者拥有一台DNS服务器,将一个子域绑定到了两个不同的IP,IP地址再不断轮换,目标服务器在检测URL和访问URL时指向的IP地址不同,导致白名单检测被绕过。
2)IP地址转换
常用的方法就是将IP地址转换为不同的进制,例如192.168.0.1:
8进制格式:0300.0250.0.1
16进制格式:0xC0.0xA8.0.1
10进制整数格式:3232235521
16进制整数格式:0xC0A80001
3)利用xip.io
xip.io这是个特别的 域名,是别人搭好的网站,具体信息可以访问来查看,他会把如下的域名解析到特定的地址,其实和dns解析绕过一个道理:
http://10.0.0.1.xip.io = 10.0.0.1
www.10.0.0.1.xip.io= 10.0.0.1
http://mysite.10.0.0.1.xip.io = 10.0.0.1
foo.http://bar.10.0.0.1.xip.io = 10.0.0.1
10.0.0.1.xip.name resolves to 10.0.0.1
www.10.0.0.2.xip.name resolves to 10.0.0.2
foo.10.0.0.3.xip.name resolves to 10.0.0.3
bar.baz.10.0.0.4.xip.name resolves to 10.0.0.4
4)其他绕过方法
利用"句号”绕过:比如127。0。0。1会被解析成127.0.0.1
利用nclosed alphanumerics绕过:比如 ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ >>> http://example.com
利用短网址绕过:例如https://dwz.lc/2fGYWaE >>>> https://www.baidu.com
利用302跳转。
....
二、SSRF-labs分析利用
1、file_get_content()
先看代码:
if(isset($_POST['read'])){
$file=trim($_POST['file']);
echo htmlentities(file_get_contents($file));
}
很简单的逻辑,这里就是通过file参数获取了文件名,然后未经过任何处理,就交给你file_get_content()函数进行读取,导致了SSRF漏洞的产生。
这里如果我们将$file参数传入的值设置为远程或者内网中其他的资源的值也是可以访问的,并且如果使用PHP伪协议的话,就还能读取本地文件,或者其他的操作。
简单利用: 读取本地文件
1)使用file协议读取hosts文件:

2)使用php:/filter协议读取win.ini文件

2、DNS_spoofing.php
还是先分析源码:
if(isset($_POST['read'])){
$file=strtolower($_POST['file']); //获取file参数并转换为小写
if(strstr($file, 'localhost') == false && preg_match('/(^https*:\/\/[^:\/]+)/', $file)==true){ //如果localhost不存在于$file,并且是以http开头
$host=parse_url($file,PHP_URL_HOST); //后去URL解析后的host,比如 http://127.0.0.1/index ——》127.0.0.1
if(filter_var($host, FILTER_VALIDATE_IP)) { //检测IP是否为私有IP,如果是继续检测。
if(filter_var($host, FILTER_VALIDATE_IP, FILTER_FLAG_IPV4 | FILTER_FLAG_NO_PRIV_RANGE | FILTER_FLAG_NO_RES_RANGE)== false) {
echo '<table width="50%" cellspacing="0" cellpadding="0" class="tb1" style="opacity: 0.6;">
<tr><td align=center style="padding: 10px;" >
The provided IP is from Private range and hence not allowed
</td></tr></table>
<table width="50%" cellspacing="0" cellpadding="0" class="tb1" style="margin:10px 2px 10px;opacity: 0.6;" >';
}else {
echo '<textarea rows=20 cols=60>'.file_get_contents($file)."</textarea>";
}
}else{
echo '<textarea rows=20 cols=60>'.file_get_contents($file)."</textarea>";
}
}elseif(strstr(strtolower($file), 'localhost') == true && preg_match('/(^https*:\/\/[^:\/]+)/', $file)==true){ //如果URL包含localhost,弹出错误
echo '
<table width="30%" cellspacing="0" cellpadding="0" class="tb1" style="opacity: 0.6;"><tr><td align=center style="padding: 10px;" >
Tyring to access Localhost o_0 ?
</td></tr></table>
<table width="50%" cellspacing="0" cellpadding="0" class="tb1" style="margin:10px 2px 10px;opacity: 0.6;" >';
} else {
echo '<textarea rows=20 cols=60>'.file_get_contents($file)."</textarea>";
}
}
从上面的代码中我们能够指导,题目对127、192、10、172等私有IP地址做了过滤和检测,并且检测了localhost。所以需要想办法绕过检测。
这里由于对IP地址的检测较为严格,并且file_get_content()也只能是被常规的URL地址,所以进行进制编码、短地址绕过、等方法都不可行。但是可以发现,如果我们在不适用http协议的情况下,程序就能直接通过file_get_content()访问我们的UR链接,所以这里我们就可以继续使用伪协议来进行利用。

三、CTF例题分析
1、例题一
先看看源代码:
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
$x=parse_url($url);
if($x['scheme']==='http'||$x['scheme']==='https'){ //以http或者https协议开头的允许访问
if(!preg_match('/localhost|127.0.0/')){ //设置黑名单,不允许URl带localhost和127.0.0
$ch=curl_init($url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($ch); //curl函数获取内容
curl_close($ch);
echo ($result);
}else{
die('hacker');
}
}else{
die('hacker');
}
?>
可以看到,这里采用了IP地址黑名单的方式,并且只允许我们使用http或者https协议。
对于IP地址黑名单,绕过方法还是多种多样的,可以考虑使用IP地址进制转换或者断地址绕过等方式。
绕过利用:
进制转换绕过:
十六进制:?url=http://0x7F.0.0.1/xxx.php
八进制: ?url=http://0177.0.0.1/xxx.php
.....
特殊省略绕过:
?url=http://0/flag.php
2、例题二
源码:
<?php
if (isset($_POST['url'])) {
$url = $_POST['url'];
//连接必须以http或者https开头
if (preg_match('/^http[s]?:\/\/([(\w|\d)+\.]+[\/]?)*/', $url, $matches)) {
//获取文件内容,对URL未经过滤,说明存在SSRF漏洞
$content = file_get_contents($_POST['url']);
$filename = str_replace('/', '', $matches[1]);
//将文件名设置为$md5($filename).IP,这里并不会加上文件名
$filename = './chuoybinu/' . md5($filename) . $matches[1];
//将文件写入"//chuoybinu/md5($filename)”文件中
file_put_contents($filename, $content);
//获取图片信息,并检测文件格式是否是图片
$image = getimagesize($filename);
$image_type = $image[2];
//如果是图片,将URL使用img标签跳转,否则使用a标签设置链接
if(in_array($image_type, array(IMAGETYPE_GIF, IMAGETYPE_JPEG, IMAGETYPE_PNG, IMAGETYPE_BMP))) {
echo '<img src="' . $url . '">';
} else {
echo '<a href="' . $url . '">' . $url . '</a>';
}
//或者是以file://开头,并且获取URL中的文件内容
} else if (preg_match('/^file:\/\/([\/\w\d\.]+)/', $url)) {
$content = file_get_contents($url);
readfile($file);
$filename = './chuoybinu/' . md5(time());
file_put_contents($filename, $content);
if (strpos($url, '_')) {
echo '<p>Flag is not such easy to get!(:◎)≡</p>';
} else {
echo '<a href="' . $filename . '">' . $filename . '</a>';
}
} else {
echo '<p>Protocol Not Supported!(:◎)≡</p>';
}
} else {
?>
可以看到,这里允许使用了http[s]或者file协议读取文件,并且文件的URL做任何过滤,导致了SSRF漏洞的产生。
同时由于获取的文件内容会保存到本地的./chuoybinu目录下,但是我们仔细分析,发现在使用http协议的情况下,文件保存后,只会保存为` m d 5 ( md5( md5(filename).IP的形式,并不会保存文件后缀,所以想要通过远程读取文件getshell的方法并不行,但是还是可以利用http协议来进行内网端口探测等基本的漏洞利用。
所以要读取系统文件等,还是需要使用file协议进行读取。
漏洞利用:
读取本地文件:

可以看到,文件读取后,被保存到了./chuoybinu/2afeb826cb4bf4c88119ab3d37c0f278文件中,我们访问之后,就能看到正常的hosts文件内容了:文章来源:https://www.toymoban.com/news/detail-488799.html
 文章来源地址https://www.toymoban.com/news/detail-488799.html
文章来源地址https://www.toymoban.com/news/detail-488799.html
四、参考资料
- SSRF总结
- PHP伪协议总结
- SSRF的利用方式
- SSRF 常见绕过思路
- 长亭—利用SSRF来拓展攻击面
到了这里,关于PHP代码审计8—SSRF 漏洞的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!