目录
相关知识
并发操作可能产生的数据不一致性
MySQL的事务隔离级别
示例
第一关:并发控制与事务的隔离级别
编程要求
测试说明
代码如下
第二关:读脏
任务描述
相关知识
读脏
读脏产生的原因
编程要求
代码如下:
第三关:不可重复读
任务描述
相关知识
不可重复读
产生不可重复读的原因
编程要求
代码如下
第四关:幻读
任务描述
相关知识
幻读(phantom read)
产生幻读的原因
编程要求
测试说明
代码如下:
第五关:主动加锁保证可重复读
任务描述
相关知识
MySQL对共享锁与锁的支持
编程要求
代码如下:
第六关:可串行化
相关知识
可串行化
编程要求
代码如下
主要知识点
相关知识
并发操作可能产生的数据不一致性; MySQL的事务隔离级别; 隔离级别,一致性和并发度的关系。
并发操作可能产生的数据不一致性
数据库是共享资源,允许多个用户同时访问同一数据库,特别是在互联网应用成为主流的当下,高可用性、高并发是所有应用追求的目标。但并发操作不加控制,便会产生数据的不一致性。 并发操作可能带来的数据不一致性包括:
- 丢失修改(lost update)
- 读脏数据(dirty read)
- 不可重复读(non-repeatable read)
- 幻读(phantom read)
为解决上述不一致性问题,DBMS设计了专门的并发控制子系统,采用封锁机制进行并发控制,以保证事务的隔离性和一致性(事务是并发控制的基本单位)。
但事务的隔离程度越高,固然一致性--或者説数据的正确性越有保障,但并发度就会越低。很多时候,需要在一致性和并发度间进行取舍,从而就生产了事务的隔离级别的概念。 隔离级别越高,一致性程度越高,并发度越低。反之,隔离级别越低,并发度越高,但代价是会出现某些数据不一致现象。
MySQL的事务隔离级别
在前述的几类不一致性中,只有丢失修改是不能容忍的,所有的商用DBMS,其事务管理和并发控制子系统都不会允许这种情形发生。所以,事务隔离级别的最低限度是容忍“读脏”。在追求高并发的场景中,除“丢失修改”外,其它不一致性都是可以容忍的。
不同的DBMS,其事务的隔离级别划分是不同的。 MySQL的事务隔离级别从低到高分以下四级:
- 读未提交(READ UNCOMMITTED)
- 读已提交(READ COMMITTED)
- 可重复读(REPEATABLE READ)
- 可串行化(SERIALIZABLE)
低隔离级别可以支持更高的并发处理,同时占用的系统资源更少,但可能产生数据不一致的情形也更多一些。 MySQL 事务隔离级别及其可能产生的问题如下表所示:
| 隔离级别 | 读脏 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ UNCOMMITTED | √ | √ | √ |
| READ COMMITTED | × | √ | √ |
| REPEATABLE READ | × | × | √ |
| SERIALIZABLE | × | × | × |
上表说明,最低的隔离级别不能避免读脏、不可重复读和幻读,而最高的隔离级别,可保证多个并发事务的任何调度,都不会产生数据的不一致性,但其代价是并发度最低。
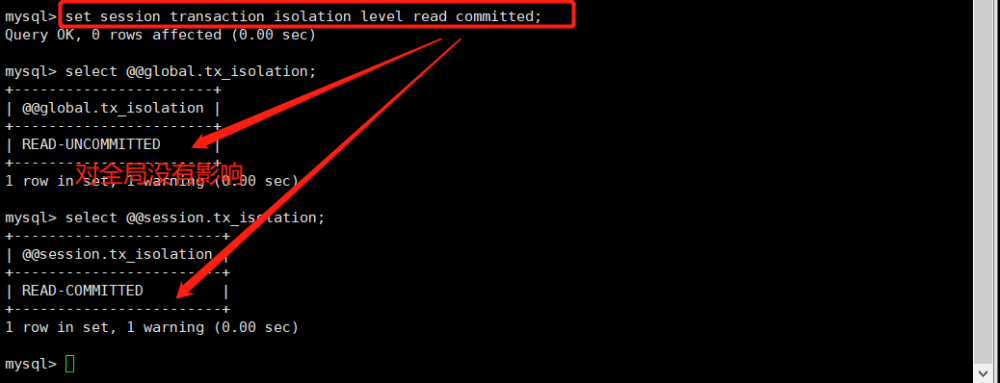
查询事务的隔离级别 可用以下语句查询MySQL的事务隔离级别: select @@GLOBAL.transaction_isolation, @@transaction_isolation; 其中,@@GLOBAL.transaction_isolation全局变量,@@transaction_isolation为本会话期内的变量。通常通过重设该变量的值以改变隔离级别。 上述两个变量的缺省值均为:REPEATABLE-READ,即可重复读。 説明:MySQL8的事务隔离级别变量名与之前的版本是不同的,请不要参考旧版本的说明文档。
设置事务的隔离级别 以下语句设置事务的隔离级别为可读未提交(read uncommitted): set session transaction isolation level read uncommitted; 如需设置为其它级别,只需替换最后的隔离级别即可。 不同的事务隔离级别意味着不同的封锁协议,程序员只需设置事务的隔离级别即可,其它的交给DBMS并发子系统处理。 不过,MySQL也有lock tables和unlock tables语句,可以直接锁表,另外,MySQL还支持在select语句中使用for share或for update短语主动申请S锁或X锁(只到事务结束才释放)。这样,即使在隔离级别为read uncommitted的情形下,仍有机会保证可重复读,相关内容请参阅MySQL官方文档。
示例
在数据库testdb1中建下表,并插入一条数据:
CREATE TABLE `dept` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(20) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;insert into dept(name) values("行政部");
同时开启两个事务,并按下表所示的调度执行:
| 时刻 | 事务1 | 事务2 |
|---|---|---|
| 1 | begin; | |
| 2 | begin; | |
| 3 | select name from dept; | |
| 4 | insert into dept(name) values('研发部'); | |
| 5 | commit; | |
| 6 | select name from dept; | |
| 7 | commit; |
请大家先思考一下,事务1两次查询的结果分别是什么? 正确答案是: 事务1两次查询的结果都一样:
| name |
|---|
| 行政部 |
虽然事务1第二次查询时,事务2已提交,但事务1和2都采用了较高级别的事务隔离机制:REPEATABLE-READ(缺省的事务隔离级别)。事务1的两次读结果保持了一致,事务2对事务1没有影响。
两个事务同时开启,并发执行,其调度顺序具有一定的随机性,每次执行的结果都是不确定的,这取决于很多因素。如果你想演示上述确定的调度顺序,需要在事务中适当的地方加上延时语句,比如长循环,作无竟义的连接操作等,当然,更好的方法是直接采用MySQL的sleep()函数,它使得事务暂时休眠指定时间(单位是秒)。上述两个事务可以分别改造如下: 事务1:
use testdb1;begin;select * from dept;set @n = sleep(5);select * from dept;commit;
事务2:
use testdb1;begin;set @n = sleep(1);insert into dept(name) values("研发部");commit;
事务1在作完第1次查询后,等待了5秒,这个时间足够轮到事务2完成插入并提交,然后事务1再次查询,此时,事务2早已提交。
你还可以尝试在适当的地方添上显示时间(select now();)的语句,验证两个事务的读写语句执行的时间;
为使两个事务并发执行,可以在诸如navicat软件中打开两个会话,将两段代码分别粘贴到两个会话,快速点击两个会话的运行按钮让这两个事务并发执行,便可以观察到前面的执行结果。
上述方法将在接下来的实验中被多次使用,但这里要申明的是:这仅仅是为了构造两个事务并发执行时,我们所期望的代码执行顺序,在真实的事务中,不会使用类似语句。接下来要介绍的,才是体验多个事务并发执行时,不同的调度可能会得出不同结果 的最好方式。但这种方法没办法评测。
第一关:并发控制与事务的隔离级别
编程要求
在右侧代码文件编辑器里根据提示补充适当的代码,将事务的隔离级别设置为read uncommitted; 并以rollback语句结束事务。
需要补充代码的地方都在以#开头的注释行的下一行。
请不要在代码文件第7行之前插入其它无关语句(包括空白行),以免不能通过测试。
测试说明
平台会在代码文件的第7行插入insert语句(所以,即使代码文件中现有的insert语句被删除,仍能确保至少有一条insert语句参与测试),然后运行代码文件,当在所有测试集上运行结果均与预期结果完全一致时,即可通关。
代码如下
-- 请不要在本代码文件中添加空行!!!
use testdb1;
# 设置事务的隔离级别为 read uncommitted
set session transaction isolation level read uncommitted;
-- 开启事务
start transaction;
insert into dept(name) values('运维部');
# 回滚事务:
rollback;
/* 结束 */mysql中设置事务set session transaction isolation level 事务等级;
第二关:读脏
任务描述
本关任务: 选择合适的事务隔离级别,构造两个事务并发执行时,发生“读脏”现象。
相关知识
读脏及其产生的原因
读脏
读脏(dirty read),或者又叫脏读,是指一个事务(t1)读取到另一个事务(t2)修改后的数据,后来事务t2又撤销了本次修改(即事务t2以roll back结束),数据恢复原值。这样,事务t1读到的数据就与数据库里的实际数据不一致,这样的数据被称为“脏”数据,意即不正确的数据。
读脏产生的原因
显然,产生读脏的原因,是事务t1读取数据时,修改该数据的事务t2还没有结束(commit或roll back,统称uncommitted),且t1读取的时间点又恰在t2修改该数据之后。
根据上一关介绍的基本知识,只有一种隔离级别可能会产生读脏。
编程要求
有表ticket记录了航班余票数,其结构如下表所示:
| 列 | 类型 | 说明 |
|---|---|---|
| flight_no | char(6) | primary key |
| tickets | int | 余票数 |
现有两个涉及该表的并发事务t1和t2,分别定义在t1.sql和t2.sql代码文件中,请在两个代码文件适当的地方补充代码,构造“读脏”现象。t1是读脏的那个事务,而t2是那个修改数据后又撤销的事务。
需要补充代码的位置均在以#开头的注释行的下一行。必要时,请复习第1关介绍的相关内容。
代码文件编辑器里看到的是t1.sql,请将鼠标移至“代码文件”右侧的三角符号,从下拉列表中切换代码文件(可在t1.sql和t2.sql间随意切换)。确认两个文件都正确后,再点击评测按钮。
测试说明
平台会让两个事务并发执行,如果在所有的测试用例下,两个事务并发执行的结果都与预期结果完全一致,即可通关。
代码如下:
t1.sql
-- 事务1:
use testdb1;
## 请设置适当的事务隔离级别
set session transaction isolation level READ UNCOMMITTED;
start transaction;
-- 时刻2 - 事务1读航班余票,发生在事务2修改之后
## 添加等待代码,确保读脏
set @n=sleep(2);
select tickets from ticket where flight_no = 'CA8213';
commit;
t2.sql
-- 事务2
use testdb1;
## 请设置适当的事务隔离级别
set session transaction isolation level read uncommitted;
start transaction;
-- 时刻1 - 事务2修改航班余票
update ticket set tickets = tickets - 1 where flight_no = 'CA8213';
-- 时刻3 - 事务2 取消本次修改
## 请添加代码,使事务1在事务2撤销前读脏;
set @n=sleep(4);
rollback;第三关:不可重复读
任务描述
本关任务: 选择合适的事务隔离级别,构造两个事务并发执行时,发生“不可重复读”现象。
相关知识
不可重复读及其产生的原因
不可重复读
不可重复读(unrepeatable read),是指一个事务(t1)读取到某数据后,另一个事务(t2)修改了该,事务t1并未修改该数据,但当t1再次读取该数据时,发现两次读取的结果不一样。
产生不可重复读的原因
显然,不可重复读产生的原因,是事务t1的两次读取之间,有另一个事务修改了t1读取的数据。
根据第一关介绍的基本知识,有两种隔离级别都有可能发生不可重复读。
编程要求
有表ticket记录了航班余票数,其结构如下表所示:
| 列 | 类型 | 说明 |
|---|---|---|
| flight_no | char(6) | primary key |
| tickets | int | 余票数 |
现有两个涉及该表的并发事务t1和t2,分别定义在t1.sql和t2.sql代码文件中,请在两个代码文件适当的地方补充代码,构造“不可重复读”现象。t2是发生不可重复读的那个事务,t1在t2的两次连续读之间修改了数据。
由于两个事务均有读和写操作,且并发执行,其输出顺序具有不确定性,为评测方便,所有的读(select)操作的结果,均被写入到一个名为result的表中,写入时记下了事务编号、读取的时间和读到的结果。请不要修改这些语句,否则会影响评测结果。
需要补充代码的位置均在以#开头的注释行的下一行。必要时,请复习第1关介绍的相关内容。
代码文件编辑器里看到的是t1.sql,请将鼠标移至“代码文件”右侧的三角符号,从下拉列表中切换代码文件(可在t1.sql和t2.sql间随意切换)。确认两个文件都正确后,再点击评测按钮。
测试说明
平台会让两个事务并发执行,如果在所有的测试用例下,两个事务并发执行的结果都与预期结果完全一致,即可通关。
代码如下
t1.sql
-- 事务1:
## 请设置适当的事务隔离级别
set session transaction isolation level REPEATABLE READ;
-- 开启事务
start transaction;
-- 时刻1 - 事务1读航班余票:
insert into result
select now(),1 t, tickets from ticket where flight_no = 'CZ5525';
## 添加等待代码,确保事务2的第一次读取在事务1修改前发生
set @n = sleep(3);
-- 时刻3 - 事务1修改余票,并立即读取:
update ticket set tickets = tickets - 1 where flight_no = 'CZ5525';
insert into result
select now(),1 t, tickets from ticket where flight_no = 'CZ5525';
## 添加代码,使事务2 的第2次读取在事务1修改之后,提交之前发生
set @n = sleep(5);
commit;
-- 时刻6 - 事务1在t2也提交后读取余票
## 添加代码,确保事务1在事务2提交后读取
set @n = sleep(5);
insert into result
select now(), 1 t, tickets from ticket where flight_no = 'CZ5525';t2.sql
-- 事务2
## 请设置适当的事务隔离级别以构造不可重复读
set session transaction isolation level READ UNCOMMITTED;
start transaction;
-- 时刻2 - 事务2在事务1读取余票之后也读取余票
## 添加代码,确保事务2的第1次读发生在事务1读之后,修改之前
set @n = sleep(1);
insert into result
select now(),2 t, tickets from ticket where flight_no = 'CZ5525';
-- 时刻4 - 事务2在事务1修改余票但未提交前再次读取余票,事务2的两次读取结果应该不同
## 添加代码,确保事务2的读取时机
set @n = sleep(5);
insert into result
select now(), 2 t, tickets from ticket where flight_no = 'CZ5525';
-- 事务2立即修改余票
update ticket set tickets = tickets - 1 where flight_no = 'CZ5525';
-- 时刻5 - 事务2 读取余票(自己修改但未交的结果):
set @n = sleep(2);
insert into result
select now(), 2 t, tickets from ticket where flight_no = 'CZ5525';
commit;第四关:幻读
任务描述
本关任务: 在repeatable read事务隔离级别,构造两个事务并发执行时,发生“幻读”现象。
相关知识
幻读及其产生的原因
幻读(phantom read)
幻读定义其实是有些争议的,在某些文献中,幻读被归为不可重复读(unrepeatable read)中的一类,而另一些则把它与不可重复读区分开来:幻读是指一个事务(t1)读取到某数据后,另一个事务(t2)作了insert或delete操作,事务t1再次读取该数据时,魔幻般地发现数据变多了或者变少了(记录数量不一致);而不可重复读限指事务t2作了update操作,致使t1的两次读操作读到的结果(数据的值)不一致。
产生幻读的原因
显然,幻读产生的原因,是事务t1的两次读取之间,有另一个事务insert或delete了t1读取的数据集。
根据第一关介绍的基本知识,除了最高级别serializable(可串行化)以外的任何隔离级别,都有可能发生幻读。
编程要求
在低隔离级别,复现幻读是很容易的。本关要求大家在较高隔离级别,即仅次于serializable的repeatable read隔离级别下重现“幻读”现象,这样,可更好地体验不可重复读与幻读的区别。
设有表ticket记录了航班余票数,其结构如下表所示:
| 列 | 类型 | 说明 |
|---|---|---|
| flight_no | char(6) | primary key |
| aircraft | char(10) | 执飞机型 |
| tickets | int | 余票数 |
现有两个涉及该表的并发事务t1和t2,分别定义在t1.sql和t2.sql代码文件中。t2.sql的代码如下:
-- 事务2(采用默认的事务隔离级别- repeatable read):use testdb1;start transaction;set @n = sleep(1);insert into ticket values('MU5111','A330-200',311);commit;
请在代码文件t1.sql适当的地方补充代码,要求如下:
- 两次查询余票超过300张的航班信息(第2次查询已替你写好);
- 在第1次查询之后,事务t2插入了一条航班信息并提交(t2.sql已替你写好);
- 第2次查询的记录数增多,发生“幻读”。
- 不得修改t1的事务隔离级别(保持默认的repeatable read)
测试说明
平台会让两个事务并发执行,如果在所有的测试用例下,两个事务并发执行的结果都与预期结果完全一致,即可通关。
代码如下:
-- 事务1(采用默认的事务隔离级别- repeatable read):
use testdb1;
select @@transaction_isolation;
start transaction;
## 第1次查询余票超过300张的航班信息
select * from ticket where tickets > 300;
set @n = sleep(1);
-- 修改航班MU5111的执飞机型为A330-300:
update ticket set aircraft = 'A330-300' where flight_no = 'MU5111';
-- 第2次查询余票超过300张的航班信息
select * from ticket where tickets > 300;
commit;第五关:主动加锁保证可重复读
任务描述
本关任务: 在事务隔离级别较低的read uncommitted情形下,通过主动加锁,保证事务的一致性
相关知识
共享锁与写锁
MySQL对共享锁与锁的支持
通过设置不同的隔离级别,以实现不同的一致性与并发度的需求是较通常的作法。但MySQL也提供了主动加锁的机制,使得在较低的隔离级别下,通过加锁,以实现更高级别的一致性。
MySQL的select语句支持for share和for update短语,分别表示对表加共享(Share)锁和写(write)锁,共享锁也叫读锁,写锁又叫排它锁。 下面这条语句,会对表t1加共享锁: select * from t1 for share; 如果select语句涉及多张表,还可分别对不同的表加不同的锁,比如: select * from t1,t2 for share of t1 for update of t2;
加锁短语总是select语句的最后一个短语(复杂的select语句可能有where,group by, having, order by等短语);
不管share还是update锁,都是在事务结束时才释放。
当然,锁行为会降低并发度。
编程要求
有表ticket记录了航班余票数,其结构如下表所示:
| 列 | 类型 | 说明 |
|---|---|---|
| flight_no | char(6) | primary key |
| tickets | int | 余票数 |
现有两个涉及该表的并发事务t1和t2,分别定义在t1.sql和t2.sql代码文件中,请在两个代码文件适当的地方补充代码,实现:
- 两个事务的隔离级别都设置成read uncommitted;
- 事务t1连续查询两次航班MU2455的余票;
- 事务t2在t1的两次查询之间试图进行一次出票操作:将航班MU2455的余票减去1张。
- 保证事务t1的两次读结果是一样的(可重复读)
- 事务t1结束后,在等待t2正常提交(commit)后,再查询一次全部航班的余票,MU2455的余票应该减少1张。
代码文件编辑器里看到的是t1.sql,请将鼠标移至“代码文件”右侧的三角符号,从下拉列表中切换代码文件(可在t1.sql和t2.sql间随意切换)。确认两个文件都正确后,再点击评测按钮
代码如下:
t1.sql
-- 事务1:
use testdb1;
set session transaction isolation level read uncommitted;
start transaction;
# 第1次查询航班'MU2455'的余票
select tickets from ticket where flight_no='MU2455' for share;
set @n = sleep(5);
# 第2次查询航班'MU2455'的余票
select tickets from ticket where flight_no='MU2455' ;
commit;
-- 第3次查询所有航班的余票,发生在事务2提交后
set @n = sleep(1);
select * from ticket;t2.sql
-- 事务2:
use testdb1;
set session transaction isolation level read uncommitted;
start transaction;
set @n = sleep(1);
# 在事务1的第1,2次查询之间,试图出票1张(航班MU2455):
update ticket set tickets=tickets-1 where flight_no='MU2455';
commit;
第六关:可串行化
任务描述
本关任务: 选择除serializable(可串行化)以外的任何隔离级别,保证两个事务并发执行的结果是可串行化的。
相关知识
可串行化
可串行化
多个事务并发执行是正确的,当且仅当其结果与按某一次序串行地执行这些事务时的结果相同。两个事务t1,t2并发执行,如果结果与t1→t2串行执行的结果相同,或者与t2→t1串行执行的结果相同,都是正确的(可串行化的)。
如果将事务的隔离级别设置为serializable,则这些事务并发执行,无论怎么调度都会是可串行化的。但这种隔离级别会大大降低并发度,在实践中极小使用。MySQL默认的隔离级别为repeatable read,有的DBMS默认为read committed。
编程要求
有表ticket记录了航班余票数,其结构如下表所示:
| 列 | 类型 | 说明 |
|---|---|---|
| flight_no | char(6) | primary key |
| tickets | int | 余票数 |
现有两个涉及该表的并发事务t1和t2,分别定义在t1.sql和t2.sql代码文件中。事务t1两次查询航班MU2455的余票,事务t2修改航班MU2455的余票(减1)。请对两个代码文件进行修改,使得两个事务并发执行的结果与t2→t1串行执行的结果相同。 除两个事务的select和update语句不可修改外(修改它们会影响输出),你可以修改、添加代码。但不得将事务的隔离级别设置为serializable,你可以保持默认隔离级别,或设置成其它隔离级别。
代码文件编辑器里看到的是t1.sql,请将鼠标移至“代码文件”右侧的三角符号,从下拉列表中切换代码文件(可在t1.sql和t2.sql间随意切换)。确认两个文件都正确后,再点击评测按钮。
代码如下
t1.sql
-- 事务1:
use testdb1;
start transaction;
set @n = sleep(2);
select tickets from ticket where flight_no = 'MU2455';
select tickets from ticket where flight_no = 'MU2455';
commit;t2.sql
use testdb1;
start transaction;
set @n = sleep(1);
update ticket set tickets = tickets - 1 where flight_no = 'MU2455';
commit;
主要知识点
- READ UNCOMMITTED(读未提交)
在这个隔离级别下,一个事务可以读取到另一个事务尚未提交的数据。这种隔离级别最容易导致脏读(Dirty Read)问题,即读取到了尚未提交的、可能被回滚的数据。
举例说明:事务A正在执行一个更新操作,但是还没有提交,此时事务B读取了这个未提交的数据,然后事务A回滚了这个更新操作,导致事务B读取到了一个不存在的数据。
- READ COMMITTED(读已提交)
在这个隔离级别下,一个事务只能读取到已经提交的数据,不会读取到其他事务尚未提交的数据。这种隔离级别可以避免脏读问题,但是可能会导致不可重复读(Non-Repeatable Read)问题。
举例说明:事务A正在执行一个更新操作,但是还没有提交,此时事务B读取了这个表中的数据,然后事务A提交了这个更新操作,导致事务B读取到了一个和之前不同的数据。
- REPEATABLE READ(可重复读)
在这个隔离级别下,一个事务在开始时会创建一个快照,所有的查询都只能读取到这个快照中存在的数据,而不能读取到其他事务中已经提交的数据。这种隔离级别可以避免脏读和不可重复读问题,但是可能会导致幻读(Phantom Read)问题。
举例说明:事务A正在执行一个插入操作,但是还没有提交,此时事务B读取了这个表中的数据,然后事务A提交了这个插入操作,导致事务B读取到了一个新增的数据。文章来源:https://www.toymoban.com/news/detail-488952.html
- SERIALIZABLE(串行化)
在这个隔离级别下,所有的事务都是串行化执行的,即每个事务都必须等待前一个事务执行完成后才能开始执行。这种隔离级别可以避免脏读、不可重复读和幻读等问题,但是会带来更高的性能开销和更长的锁定时间。文章来源地址https://www.toymoban.com/news/detail-488952.html
到了这里,关于MySQL - 并发控制与事务的隔离级别【头歌】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!