Bert和GPT的区别
起源

2018 年,Google 首次推出 BERT(Bidirectional Encoder Representations from Transformers)。该模型是在大量文本语料库上结合无监督和监督学习进行训练的。 BERT 的目标是创建一种语言模型,可以理解句子中单词的上下文和含义,同时考虑到它前后出现的单词。
2018 年,OpenAI 首次推出 GPT(Generative Pre-trained Transformer)。与 BERT 一样,GPT 也是一种大规模预训练语言模型。但是,GPT 是一种生成模型,它能够自行生成文本。 GPT 的目标是创建一种语言模型,该模型可以生成连贯且适当的上下文文本。

区别
BERT和GPT是两种不同的预训练语言模型,它们在原理和应用方面存在一些显著的区别。
目标任务:
-
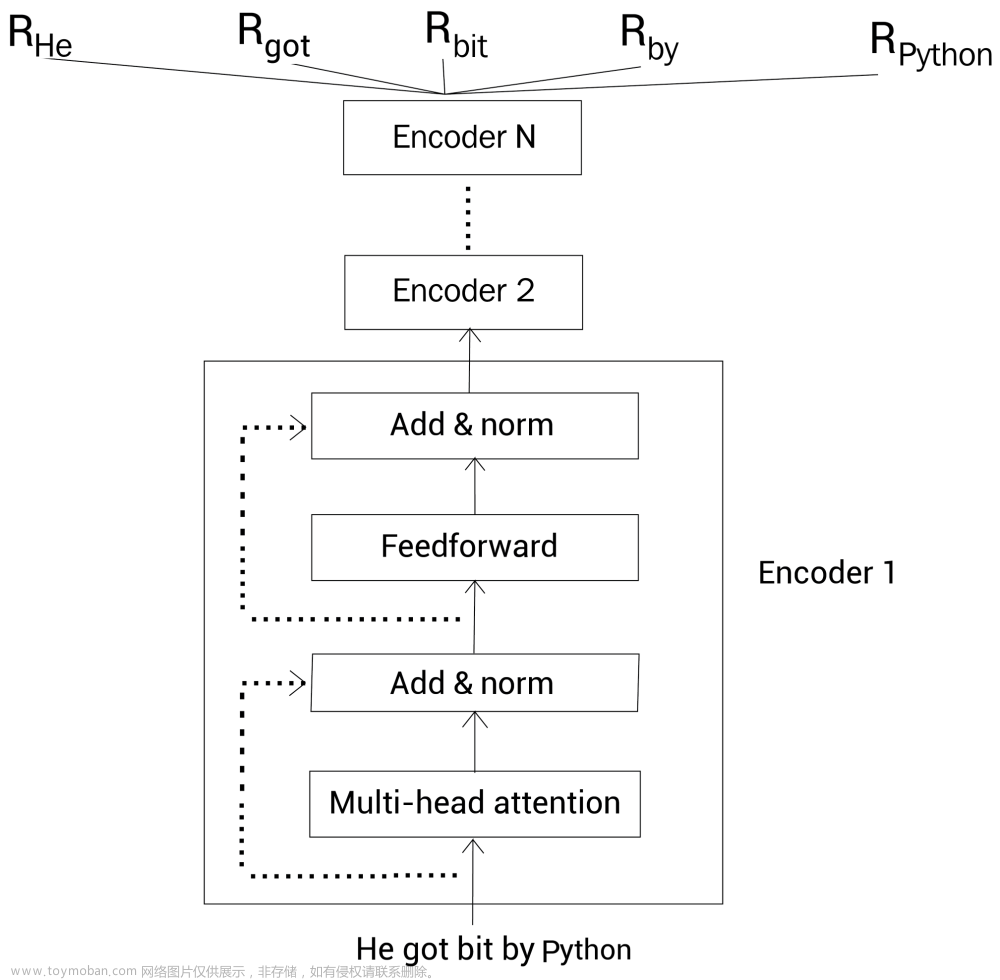
BERT:BERT是一种基于Transformer的预训练模型,它的目标是通过双向语言模型预训练来学习上下文相关的词表示。在预训练过程中,BERT通过掩码语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)任务进行训练。
-
掩码语言模型(Masked Language Model,MLM):在输入序列中,BERT随机掩盖一些词语,然后要求模型预测这些被掩盖的词语。通过这个任务,BERT可以学习到在给定上下文的情况下,预测缺失词语的能力。这使得BERT能够理解词语的语义和上下文信息。具体来说,对于每个输入序列,BERT会随机选择一些词语进行掩码。通常,选择的词语占总词语数量的15%左右。对于被选择的词语,有以下三种方式来处理:
-
80%的情况下,将被选择的词语替换为特殊的掩码标记 [MASK]。例如,将句子 “I love apples” 中的 “apples” 替换为 “[MASK] love [MASK]”。“this movie is great”变为“this movie is [MASK]”;
-
10%的情况下,将被选择的词语随机替换为其他词语。这样模型不仅需要理解上下文,还需要具备词语替换和词义推断的能力。例如,“this movie is great”变为“this movie is drink”
-
10%的情况下,保持被选择的词语不变。这样做是为了让模型学习到如何处理未被掩码的词语。“this movie is great”变为“this movie is great”
-
接下来,BERT将处理过的输入序列输入到模型中,然后使用Transformer的编码器结构进行编码。在编码过程中,模型会同时考虑到被掩码的词语和其它上下文中的信息。最终,模型会生成一组对应被掩码的词语的预测结果。
-
-
下一句预测(Next Sentence Prediction,NSP):在一些自然语言处理任务中,理解句子之间的关系是很重要的。为了让模型学习句子级别的关系,BERT使用了NSP任务。该任务要求模型判断两个句子是否是连续的,即一个句子是否是另一个句子的下一句。通过这个任务,BERT能够学习到句子级别的语义关系和推理能力。显式地建模文本对之间的逻辑关系。具体以下方式来处理:
-
对于每个训练样本,BERT会随机选择两个句子A和B。其中,50%的情况下,句子B是句子A的下一句,而另外50%的情况下,句子B是从语料库中随机选择的其他句子。。
-
为了进行NSP任务,BERT引入了一种特殊的输入编码方式。对于每个输入序列,BERT会将句子A和句子B之间插入一个特殊的分隔标记 [SEP],并在输入的开始处添加一个特殊的句子标记 [CLS]。
[CLS] 句子A [SEP] 句子B [SEP]
-
接下来,BERT将这个编码后的序列输入到模型中,并使用Transformer的编码器结构对其进行编码。编码器会根据上下文信息对句子A和句子B的表示进行学习。
-
在编码过程中,模型会将整个序列作为输入,并在特殊的 [CLS] 标记上进行预测。这个预测任务可以是一个分类任务,用于判断句子A和句子B是否是连续的。通常,模型会使用一个全连接层将 [CLS] 的隐藏状态映射到一个二分类问题上,例如使用sigmoid激活函数来预测两个句子的连续性。
-
-
-
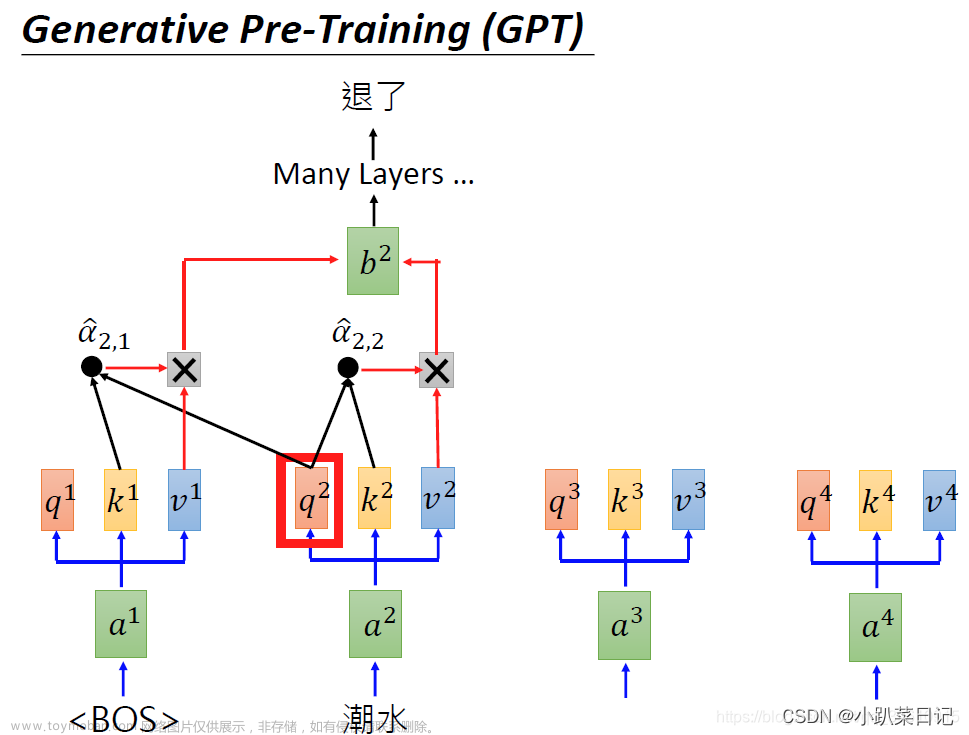
GPT:GPT是一种基于Transformer的生成式预训练模型,其目标是通过自回归语言模型预训练来学习生成连贯文本的能力。GPT采用了自回归语言模型的预训练方式。在预训练过程中,GPT使用大规模的文本数据,并通过自回归的方式逐步生成下一个词语。模型根据已生成的上文预测下一个词语,通过最大似然估计来优化模型参数。这使得GPT能够学习到生成连贯、有逻辑性的文本的能力。GPT实现过程大致如下:
-
GPT将文本数据分割成词语或子词的过程通常是通过分词(tokenization)来实现的。在分词过程中,常用的方法有两种:
- 基于词语的分词(Word-based Tokenization):这种方法将文本划分为独立的词语单元。例如,对于句子"I love natural language processing",基于词语的分词将它划分为[“I”, “love”, “natural”, “language”, “processing”]。
- 基于子词的分词(Subword-based Tokenization):这种方法将文本划分为更小的子词单元。它可以处理词语的内部结构和复杂性,更适用于处理未登录词(out-of-vocabulary)和稀有词(rare words)。例如,对于句子"I love natural language processing",基于子词的分词可以将它划分为[“I”, “love”, “nat”, “ural”, “language”, “pro”, “cess”, “ing”]。
-
无论是基于词语还是基于子词的分词,最终的目标是将文本分割成离散的标记单元,每个标记单元对应一个词语或子词。
-
Embedding词嵌入:将token编码为向量。即每个词语或子词都会被转换为对应的嵌入向量表示嵌入向量是一种连续的实数向量,用于表示词语或子词在语义空间中的位置。常见的方法是使用预训练的词向量模型,如Word2Vec、GloVe或FastText,将词语或子词映射到固定维度的实数向量。
-
Transformer架构:GPT采用了Transformer作为其基础架构。Transformer是一种强大的深度学习模型,其核心机制是自注意力机制。它能够在处理序列数据时捕捉全局依赖关系,同时具有并行计算的能力。
-
自回归语言模型:在预训练过程中,GPT使用自回归语言模型进行训练。具体而言,模型逐步生成下一个词语,以此生成连贯的文本。在生成第i个词语时,模型使用已生成的前i-1个词语作为上文来预测下一个词语。
-
学习预训练参数:在自回归语言模型中,GPT的目标是最大化生成真实训练样本的概率。通过最大似然估计,模型的参数被优化以最大化真实训练样本的生成概率。通过大规模的预训练数据和迭代的优化过程,GPT能够学习到语言的统计规律和结构,从而能够生成连贯、有逻辑性的文本。
-
生成文本:在预训练完成后,GPT可以生成文本。给定一个初始文本或种子句子,模型会逐步生成下一个词语,将其添加到已生成的文本中,然后再用生成的文本作为上文来预测下一个词语。通过重复这个过程,模型可以生成连贯、有逻辑性的文本。
-
训练方式:
BERT:BERT使用了双向语言模型的训练策略。在输入序列中,BERT随机掩盖一些词语,并让模型预测这些被掩盖的词语。这种方式使BERT能够从上下文中学习词语的语义和语境信息。
GPT:GPT使用了自回归语言模型的训练方式。它通过让模型预测当前位置的词语来学习生成文本的能力。在预训练过程中,GPT逐步生成下一个词语,并优化参数以最大化下一个词语的概率。
上下文理解能力:
两种基于Transformer架构的预训练模型,它们在上下文理解能力和应用领域上有所不同。
- BERT:由于BERT采用双向模型,通过预测被掩盖的词语和判断句子之间的关系。它可以从上下文中获取更丰富的信息,并具有较强的上下文理解能力。这使得BERT在词语级别的任务中表现出色,如命名实体识别、问答等。
- GPT:GPT是一个单向模型,它只能依赖已生成的上文来预测下一个词语。在预训练过程中,GPT使用自回归语言模型进行训练,通过逐步生成下一个词语来学习生成连贯的文本。由于单向模型的限制,GPT在生成式任务中表现较好,如对话生成、文本生成等。GPT能够生成具有上下文连贯性和逻辑性的文本,因为它在生成每个词语时都能考虑之前已生成的上文。
下游任务适用性:
- BERT:由于BERT具有强大的上下文理解能力和双向模型的特点,它在各种下游任务中表现优秀,如文本分类、命名实体识别、语义关系判断等。
- GPT:GPT主要用于生成式任务,如对话生成、文本生成和机器翻译等。它能够生成自然流畅的文本,但在一些需要输入-输出对齐的任务中效果较弱。
- 第一阶段,在未标记数据上使用语言建模目标来学习神经网络模型的初始参数
- 第二阶段,预训练的GPT模型是生成式的,而在具体应用中,可以通过微调(fine-tuning)将GPT用于特定的下游任务。在微调阶段,可以添加任务特定的层或结构,并使用有标签的任务数据来进一步调整模型,使其适应特定任务的要求。
总体而言,BERT和GPT在目标任务、训练方式、上下文理解能力和适用性上存在差异。BERT适用于各种下游任务,而GPT主要用于生成式任务。选择哪种模型取决于具体的任务需求和应用场景。
代码
Bert实现代码。在这里使用动手学深度学习提供的代码讲解
import torch
from torch import nn
from d2l import torch as d2l
#@save
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""获取输入序列的词元及其片段索引"""
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0和1分别标记片段A和B
segments = [0] * (len(tokens_a) + 2)
if tokens_b is not None:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments
#@save
class BERTEncoder(nn.Module):
"""BERT编码器"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
self.segment_embedding = nn.Embedding(2, num_hiddens)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(f"{i}", d2l.EncoderBlock(
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
# 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数
self.pos_embedding = nn.Parameter(torch.randn(1, max_len,
num_hiddens))
def forward(self, tokens, segments, valid_lens):
# 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens)
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X = X + self.pos_embedding.data[:, :X.shape[1], :]
for blk in self.blks:
X = blk(X, valid_lens)
return X
#@save
class MaskLM(nn.Module):
"""BERT的掩蔽语言模型任务"""
def __init__(self, vocab_size, num_hiddens, num_inputs=768, **kwargs):
super(MaskLM, self).__init__(**kwargs)
self.mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.LayerNorm(num_hiddens),
nn.Linear(num_hiddens, vocab_size))
def forward(self, X, pred_positions):
num_pred_positions = pred_positions.shape[1]
pred_positions = pred_positions.reshape(-1)
batch_size = X.shape[0]
batch_idx = torch.arange(0, batch_size)
# 假设batch_size=2,num_pred_positions=3
# 那么batch_idx是np.array([0,0,0,1,1,1])
batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions)
masked_X = X[batch_idx, pred_positions]
masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))
mlm_Y_hat = self.mlp(masked_X)
return mlm_Y_hat
#@save
class NextSentencePred(nn.Module):
"""BERT的下一句预测任务"""
def __init__(self, num_inputs, **kwargs):
super(NextSentencePred, self).__init__(**kwargs)
self.output = nn.Linear(num_inputs, 2)
def forward(self, X):
# X的形状:(batchsize,num_hiddens)
return self.output(X)
#@save
class BERTModel(nn.Module):
"""BERT模型"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
hid_in_features=768, mlm_in_features=768,
nsp_in_features=768):
super(BERTModel, self).__init__()
self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, num_layers,
dropout, max_len=max_len, key_size=key_size,
query_size=query_size, value_size=value_size)
self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens),
nn.Tanh())
self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features)
self.nsp = NextSentencePred(nsp_in_features)
def forward(self, tokens, segments, valid_lens=None,
pred_positions=None):
encoded_X = self.encoder(tokens, segments, valid_lens)
if pred_positions is not None:
mlm_Y_hat = self.mlm(encoded_X, pred_positions)
else:
mlm_Y_hat = None
# 用于下一句预测的多层感知机分类器的隐藏层,0是“<cls>”标记的索引
nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))
return encoded_X, mlm_Y_hat, nsp_Y_hat
GPT代码
GPT = Multi-Head Attention + Feed forward + LN层 + 残差
由于Decoder具备文本生成能力,故作为侧重生成式任务的GPT选择了Transformer Decoder部分作为核心架构。
但只保留了多头注意力层Multi-Head Attention层和前馈神经网络Feed forward层,最后再加上求和与归一化的前置LN层 + 残差。
此处以GPT2作为代码解释
import torch
import torch.nn as nn
from transformers import GPT2Model, GPT2Tokenizer
class GPT2(nn.Module):
def __init__(self, num_layers, d_model, num_heads, d_ff, vocab_size, max_sequence_length):
super(GPT2, self).__init__()
self.tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
self.embedding = nn.Embedding(vocab_size, d_model)
self.transformer = GPT2Model(
num_layers=num_layers,
d_model=d_model,
nhead=num_heads,
dim_feedforward=d_ff,
max_position_embeddings=max_sequence_length
)
self.fc = nn.Linear(d_model, vocab_size)
def forward(self, inputs):
embedded = self.embedding(inputs)
outputs = self.transformer(embedded)
logits = self.fc(outputs.last_hidden_state)
return logits
# GPT-2 hyperparameters
num_layers = 12
d_model = 768
num_heads = 12
d_ff = 3072
vocab_size = 50257
max_sequence_length = 1024
# Create GPT-2 model instance
model = GPT2(num_layers, d_model, num_heads, d_ff, vocab_size, max_sequence_length)
# Example input
input_ids = torch.tensor([[31, 51, 99, 18, 42, 62]]) # Input token IDs
# Forward pass
logits = model(input_ids)
上述代码是一个简化的实现示例,使用了PyTorch和Hugging Face的transformers库。GPT-2模型使用了GPT-2的预训练权重,其中的GPT2Model是GPT-2的主体Transformer模型,GPT2Tokenizer用于将文本转换为模型所需的输入。
 文章来源:https://www.toymoban.com/news/detail-488973.html
文章来源:https://www.toymoban.com/news/detail-488973.html
未完待续!文章来源地址https://www.toymoban.com/news/detail-488973.html
到了这里,关于自学大语言模型之Bert和GPT的区别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![大语言模型的预训练[2]:GPT、GPT2、GPT3、GPT3.5、GPT4相关理论知识和模型实现、模型应用以及各个版本之间的区别详解](https://imgs.yssmx.com/Uploads/2024/02/587446-1.png)