问题 1:Hadoop是什么?
答案:Hadoop是一个开源的分布式计算框架,用于处理大规模数据集的存储和处理。它基于Google的MapReduce和Google文件系统(GFS)的思想,旨在解决大数据量的处理和分析问题。
问题 2:Hadoop的核心组件有哪些?
答案:Hadoop的核心组件包括以下几个:
Hadoop分布式文件系统(HDFS):用于存储数据的分布式文件系统。
MapReduce:一种分布式计算模型,用于处理和分析大规模数据集。
YARN(Yet Another Resource Negotiator):用于资源管理和作业调度的集群管理器。
Hadoop Common:提供Hadoop其他组件所需的库和工具。
问题 3:Hadoop的优势是什么?
答案:Hadoop具有以下几个优势:
可扩展性:Hadoop可以在集群中添加更多的计算和存储节点,以处理大规模数据集。
容错性:Hadoop可以自动处理节点故障,并在失败时重新分配任务。
成本效益:Hadoop可以在廉价的商用硬件上构建,相比传统的大数据解决方案更经济实惠。
处理多种数据类型:Hadoop能够处理结构化数据和非结构化数据,如文本、图像、日志等。
并行处理:Hadoop的MapReduce模型允许并行处理数据,提高处理速度。
问题 4:Hadoop的工作原理是什么?
答案:Hadoop的工作原理可以简单概括为以下几个步骤:
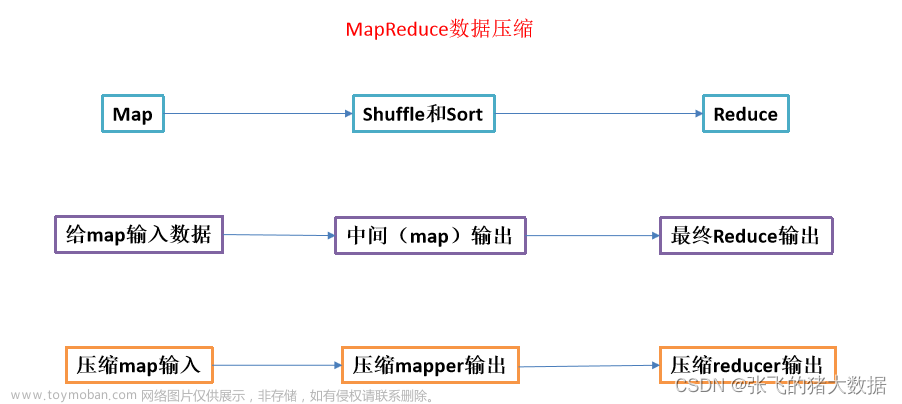
数据切片:输入数据被切分成多个块,并在集群中的不同节点上进行存储。
Map阶段:每个节点上的Map任务对切片数据进行处理和转换,生成键值对作为中间结果。
Shuffle和Sort阶段:中间结果被重新分区和排序,以便相同键的数据可以被发送到同一个Reduce任务。
Reduce阶段:Reduce任务对中间结果进行进一步的处理和聚合,生成最终的结果集。
问题 5:Hadoop适用于哪些场景?
答案:Hadoop适用于以下场景:
大数据分析:Hadoop能够高效处理大规模数据集的计算和分析任务。
日志处理:Hadoop可以处理大量的日志数据,如服务器日志、网络日志等。
推荐系统:Hadoop可以支持构建大规模的推荐系统,处理用户行为和偏好数据。
数据仓库:Hadoop可以作为一个低成本的数据存储和处理平台,用于构建数据仓库和数据湖。
问题 6:Hadoop的生态系统有哪些重要组件?
答案:Hadoop的生态系统包含了众多重要组件,其中一些包括:
Apache Hive:用于提供类似SQL的查询和分析的数据仓库工具。
Apache Pig:一种用于编写MapReduce任务的高级脚本语言。
Apache HBase:一种分布式的、面向列的NoSQL数据库。
Apache Spark:用于大规模数据处理和实时数据分析的快速计算引擎。
Apache Kafka:一种分布式的流处理平台,用于高吞吐量的数据流处理。
问题 7:Hadoop的安装和配置过程是怎样的?
答案:Hadoop的安装和配置过程可以分为以下几个步骤:
下载Hadoop发行版,并解压到适当的目录。
配置Hadoop环境变量,如JAVA_HOME和HADOOP_HOME。
配置Hadoop的核心组件,如HDFS和YARN。
根据需求修改Hadoop的配置文件,如hadoop-env.sh、core-site.xml、hdfs-site.xml等。
格式化HDFS文件系统,以准备启动Hadoop集群。
启动Hadoop集群,并验证安装是否成功。
问题 8:Hadoop的容错机制是如何工作的?
答案:Hadoop的容错机制包括以下几个方面:
数据备份:HDFS将数据划分成块,并在集群中的多个节点上进行备份,以防止数据丢失。
自动故障转移:当一个节点发生故障时,Hadoop可以自动将任务重新分配给其他可用的节点,以确保作业的完成。
任务健康检查:Hadoop会定期检查任务的进度和状态,如果任务超时或失败,会重新分配或重新执行任务。
问题 9:Hadoop的调优技巧有哪些?
答案:Hadoop的性能调优技巧包括以下几个方面:
适当的硬件配置:选择合适的硬件配置,包括计算节点和存储节点的数量和规格。
数据划分和压缩:合理划分数据块,并使用压缩算法减少存储和传输的数据量。
并行度设置:根据集群的规模和任务的需求,调整MapReduce任务的并行度参数。
资源管理和调度:优化YARN的资源管理配置,确保任务能够充分利用集群资源。
数据本地性:尽可能将任务调度到数据所在的节点上,减少数据传输的开销。
问题 10:Hadoop 3与Hadoop 2相比有哪些新特性?
答案:Hadoop 3相对于Hadoop 2引入了一些新特性,包括:文章来源:https://www.toymoban.com/news/detail-489078.html
Hadoop YARN的改进:引入了YARN容器的资源隔离和跨队列调度,提高了集群资源的利用率和任务调度的灵活性。
Hadoop分布式文件系统(HDFS)的改进:引入了Erasure Coding技术,减少了数据的冗余存储空间。
Hadoop 3支持更高级的编程模型,如容器调度、服务化框架等。
改进了Hadoop的性能和可靠性,包括任务执行器的改进、多命名空间的支持等。文章来源地址https://www.toymoban.com/news/detail-489078.html
到了这里,关于Hadoop面试题十道的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!