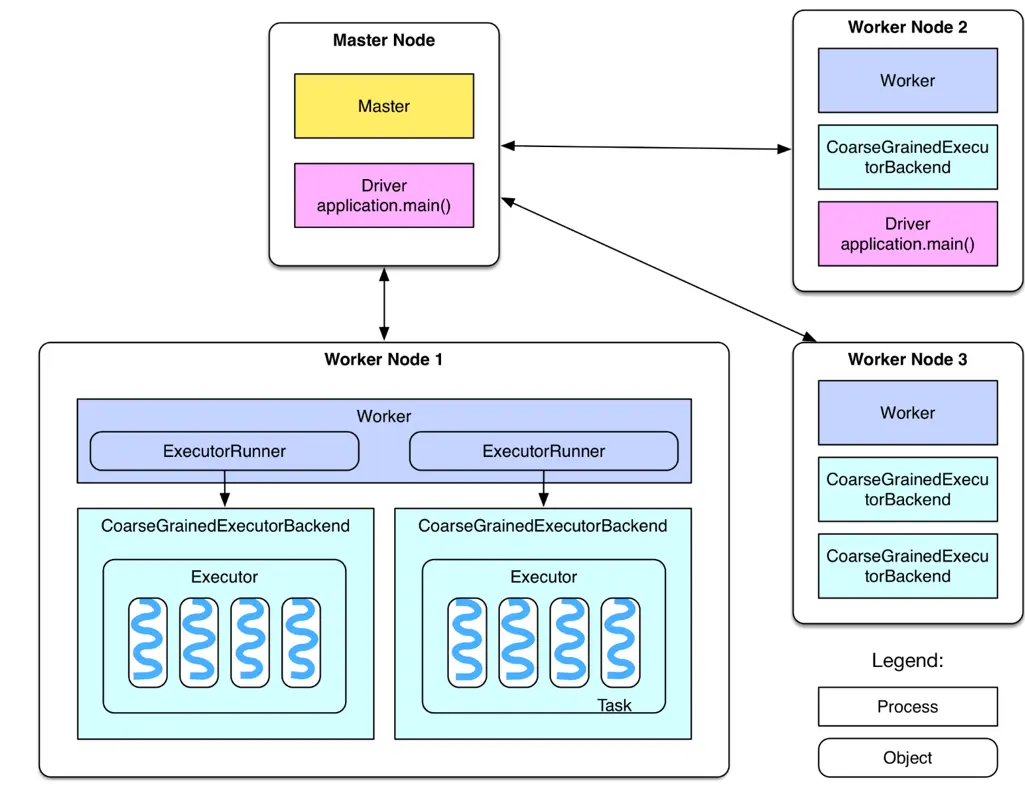
云计算中的大数据处理:尝试HDFS和MapReduce的应用
一、前言
在实验开始之前我们需要在虚拟机里面启动HDFS,进入到Hadoop安装目录里面的sbin目录里面执行start-all.sh命令即可启动成功,然后使用jps查看全部节点是否已经启动了,在昨天的做题的时候我在最开始上传文件到hdfs 的时候报错:could only be written to 0 of the 1 minReplication nodes,there are 0 datanode(s) running这个错误说明datanode没有启动成功,我们可以首先尝试停止hadoop,然后再启动。
如果还是没有解决,那就格式化一下 ,然后记得在出现Re-format filesystem in Storage Directory root= /usr/local/servers/hadoop/tmp/nndata; location= null ? (Y or N)的时候输入N,不然你的clusterID就会发生变化,就无法启动了,如果你不小心输入成了Y,那么你需要去到./hadoop/tmp目录中,修改dndata和nndata两个目录中的VERSION文件中的clusterID一样,将nndata中的clusterID值替换掉到dndata中的clusterID值,然后再重新启动一下Hadoop就能成功解决了。
二、第一题
在Hadoop分布式文件系统上,分别采用命令方式和java API方式实现文件上传、下载,目录的创建、删除、重命名及目录文件信息的查看。编写程序完成java API操作。
1、命令方式
-
文件上传:

-
文件下载:

-
目录的创建:

-
目录的删除:

-
目录的重命名:

-
目录文件信息查看:

命令行的方式很简单,在这里就不做过多的示范,直接粘贴图片。
如果有不懂的操作可以去我的大数据学习专栏里面看一下,里面有详细步骤。
2、java API方式
下面是我编写的简单实现的java程序代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.IOException;
public class HadoopFileSystemExample {
private static final String HDFS_URI = "hdfs://localhost:9000";
private static final String FILE_PATH = "/path/to/local/file.txt";
private static final String HDFS_PATH = "/path/in/hdfs/file.txt";
private static final String DIRECTORY_PATH = "/path/in/hdfs/directory";
public static void main(String[] args) {
try {
// 创建Hadoop配置对象
Configuration conf = new Configuration();
// 设置Hadoop文件系统URI
conf.set("fs.defaultFS", HDFS_URI);
// 获取Hadoop文件系统实例
FileSystem fs = FileSystem.get(conf);
// 文件上传
uploadFile(fs);
// 文件下载
downloadFile(fs);
// 创建目录
createDirectory(fs);
// 删除目录
deleteDirectory(fs);
// 重命名文件或目录
rename(fs);
// 查看目录文件信息
listFiles(fs);
// 关闭文件系统
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
private static void uploadFile(FileSystem fs) throws IOException {
// 本地文件路径
Path localPath = new Path(FILE_PATH);
// HDFS文件路径
Path hdfsPath = new Path(HDFS_PATH);
// 上传文件
fs.copyFromLocalFile(localPath, hdfsPath);
System.out.println("文件上传成功!");
}
private static void downloadFile(FileSystem fs) throws IOException {
// HDFS文件路径
Path hdfsPath = new Path(HDFS_PATH);
// 本地文件路径
Path localPath = new Path(FILE_PATH);
// 下载文件
fs.copyToLocalFile(hdfsPath, localPath);
System.out.println("文件下载成功!");
}
private static void createDirectory(FileSystem fs) throws IOException {
// 目录路径
Path directoryPath = new Path(DIRECTORY_PATH);
// 创建目录
fs.mkdirs(directoryPath);
System.out.println("目录创建成功!");
}
private static void deleteDirectory(FileSystem fs) throws IOException {
// 目录路径
Path directoryPath = new Path(DIRECTORY_PATH);
// 删除目录(递归删除)
fs.delete(directoryPath, true);
System.out.println("目录删除成功!");
}
private static void rename(FileSystem fs) throws IOException {
// 原始文件或目录路径
Path oldPath = new Path(HDFS_PATH);
// 新文件或目录路径
Path newPath = new Path("/new/path/in/hdfs/file.txt");
// 重命名文件或目录
fs.rename(oldPath, newPath);
System.out.println("重命名成功!");
}
private static void listFiles(FileSystem fs) throws IOException {
// 目录路径
Path directoryPath = new Path("/path/in/hdfs");
// 获取目录下的文件和子目录信息
FileStatus[] fileStatuses = fs.listStatus(directoryPath);
System.out.println("目录下的文件和子目录信息:");
for (FileStatus fileStatus : fileStatuses) {
System.out.println(fileStatus.getPath());
}
}
}
我们需要在指定目录中建立一个java文件,例如:HadoopFileSystemExample.java,然后将上面代码复制到创建的java文件中,然后在文件所在目录下的终端输入如下命令进行编译java代码:
javac -classpath $(hadoop classpath) HadoopFileSystemExample.java
这将使用Hadoop的类路径编译Java代码,并在同一目录下生成一个.class文件。
然后我们运行Java程序。使用以下命令运行程序:
java -classpath $(hadoop classpath):. HadoopFileSystemExample
这将运行Java程序,并根据代码中的操作与Hadoop分布式文件系统进行交互。
运行结果如下:

三、第二题
利用MapReduce编程框架,统计自己编写的数据采集文件信息,例如商品的销售订单信息,
商品名称 单价 进价
华为手机 4000 3500
Hp电脑 8000 7500
利用MapReduce编程框架编写程序统计每种商品的销售情况,统计出利润最高和销量最好的商品。
这道题目是我研究最久的题目,期间出现了各种问题,不过最后都解决掉了,在这里我把遇到的问题都列举出来,如果你们也遇见了相同的问题可以进行参考一下。
经过多次尝试,我认为将题目给出商品的销售订单信息保存到一个csv文件中更方便我们进行操作。
1、创建CSV文件并将其上传到HDFS
我们在指定目录中创建例如:sales.csv文件,然后我们在题目给出的信息的基础上进行增加数据:
商品名称,单价,进价
华为手机,4000,3500
Hp电脑,8000,7500
小米平板,3000,2800
苹果手机,6000,5500
Hp电脑,8000,7500
戴尔电脑,9000,8500
华为手机,4000,3500
苹果手机,6000,5500
小米平板,3000,2800
华为手机,4000,3500
其中重复行数据代表多次销售记录,然后我们需要统计销售情况最好的前三种商品。
保存退出之后,我们首先使用第一题所用创建目录命令在HDFS上创建一个input目录,然后将sales.csv文件上传到该目录中作为我们后续代码中输入目录。
2、编写利用MapReduce框架的java代码
-
创建一个java项目目录,例如我创建的是
sales -
创建一个继承自
Mapper类的SalesMapper类,用于实现Map阶段的逻辑。在map()方法中,解析CSV文件的每一行数据,提取商品名称、单价和进价,并将商品名称作为输出的键,销售额和利润作为输出的值。import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class SalesMapper extends Mapper<LongWritable, Text, Text, SalesData> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 跳过CSV文件的标题行 if (key.get() == 0 && value.toString().startsWith("商品名称")) { return; } // 解析CSV文件的每一行数据 String[] fields = value.toString().split(","); String productName = fields[0]; int unitPrice = Integer.parseInt(fields[1]); int costPrice = Integer.parseInt(fields[2]); // 计算销售额和利润 int salesAmount = unitPrice; int profit = unitPrice - costPrice; // 将商品名称作为键,销售数据作为值进行输出 context.write(new Text(productName), new SalesData(salesAmount, profit)); } } -
创建一个继承自
Reducer类的SalesReducer类,用于实现Reduce阶段的逻辑。在reduce()方法中,对同一商品的销售数据进行累加,计算出总销售额和总利润,并输出到最终结果。import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.Comparator; import java.util.Map; import java.util.TreeMap; public class SalesReducer extends Reducer<Text, SalesData, Text, Text> { private TreeMap<Integer, String> salesAmountMap; @Override protected void setup(Context context) { salesAmountMap = new TreeMap<>(Comparator.reverseOrder()); } @Override protected void reduce(Text key, Iterable<SalesData> values, Context context) throws IOException, InterruptedException { int totalSalesAmount = 0; int totalProfit = 0; // 对同一商品的销售数据进行累加 for (SalesData data : values) { totalSalesAmount += data.getSalesAmount(); totalProfit += data.getProfit(); } String output = "商品名称: " + key.toString() + "\t销售额: " + totalSalesAmount + "\t利润: " + totalProfit; // 输出每种商品的销售情况 context.write(new Text("每种商品的销售情况:"), new Text(output)); // 将商品销量和商品名称放入 TreeMap salesAmountMap.put(totalSalesAmount, key.toString()); // 保持 TreeMap 中只有前三个商品 if (salesAmountMap.size() > 3) { salesAmountMap.remove(salesAmountMap.lastKey()); } } @Override protected void cleanup(Context context) throws IOException, InterruptedException { // 输出销量最好的前三个商品 context.write(new Text("销量最好的前三个商品:"), new Text()); for (Map.Entry<Integer, String> entry : salesAmountMap.entrySet()) { context.write(new Text(entry.getValue()), new Text("销售额: " + entry.getKey())); } } } -
创建一个自定义的数据类型
SalesData,用于存储销售数据。import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class SalesData implements Writable { private int salesAmount; private int profit; public SalesData() { // 默认构造函数,需要提供无参构造函数 } public SalesData(int salesAmount, int profit) { this.salesAmount = salesAmount; this.profit = profit; } public int getSalesAmount() { return salesAmount; } public int getProfit() { return profit; } @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeInt(salesAmount); dataOutput.writeInt(profit); } @Override public void readFields(DataInput dataInput) throws IOException { salesAmount = dataInput.readInt(); profit = dataInput.readInt(); } @Override public String toString() { return salesAmount + "\t" + profit; } } -
创建一个
SalesDriver类作为程序的入口点,设置MapReduce作业的相关配置。import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class SalesDriver { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInt("maxProfit", 0); conf.setInt("maxSalesAmount", 0); Job job = Job.getInstance(conf, "Sales Statistics"); job.setJarByClass(SalesDriver.class); job.setMapperClass(SalesMapper.class); job.setReducerClass(SalesReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(SalesData.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
3、打包java项目
-
在我们创建的java项目根目录下创建一个名为
src的文件夹。 -
将所有的Java源代码文件(
.java)移动到src文件夹中。 -
在项目根目录中创建一个名为
Manifest.txt的文件,用于指定JAR文件的入口点。 -
在
Manifest.txt文件中,添加以下内容:Main-Class: <Main-Class>将
<Main-Class>替换为包含main方法的主类的完整类名,例如我的是SalesDriver -
回到项目根目录下,使用以下命令编译Java源代码并创建一个临时目录来保存编译后的类文件:
mkdir classes javac -d classes src/*.java如果你在使用编译命令时出现
程序包×××存在的问题,这个时候我们需要将Hadoop相关的jar文件添加到编译路径中才可以解决:javac -classpath /usr/local/servers/hadoop/share/hadoop/common/h adoop-common-3.1.3.jar:/usr/local/servers/hadoop/share/hadoop/mapreduce/hadoop-map reduce-client-core-3.1.3.jar -d classes src/*.java注意上面的命令是一个而不是多个。
-
创建一个空的JAR文件,命名为
SalesAnalysis.jar:jar -cvf SalesAnalysis.jar -C classes/ . -
将编译后的类文件和
Manifest.txt添加到JAR文件中:jar -uf SalesAnalysis.jar -C classes/ . jar -uf SalesAnalysis.jar Manifest.txt
到现在,我们的整个java项目就打包成功了。
4、在Hadoop集群上提交jar文件来运行MapReduce作业
我们将打包好的SalesAnalysis.jar使用如下命令提交到集群上面:
hadoop jar SalesAnalysis.jar SalesDriver /input/sales.csv /output
顺利执行之后终端会打印如下信息:
2023-05-18 16:53:13,372 INFO client.RMProxy: Connecting to ResourceManager at localhost/127.0.0.1:8032
2023-05-18 16:53:14,136 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2023-05-18 16:53:14,175 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1684399551458_0001
2023-05-18 16:53:14,314 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2023-05-18 16:53:14,462 INFO input.FileInputFormat: Total input files to process : 1
2023-05-18 16:53:14,531 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2023-05-18 16:53:14,962 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2023-05-18 16:53:14,985 INFO mapreduce.JobSubmitter: number of splits:1
2023-05-18 16:53:15,152 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2023-05-18 16:53:15,569 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1684399551458_0001
2023-05-18 16:53:15,569 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-05-18 16:53:15,796 INFO conf.Configuration: resource-types.xml not found
2023-05-18 16:53:15,796 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-05-18 16:53:16,273 INFO impl.YarnClientImpl: Submitted application application_1684399551458_0001
2023-05-18 16:53:16,341 INFO mapreduce.Job: The url to track the job: http://panli:8088/proxy/application_1684399551458_0001/
2023-05-18 16:53:16,341 INFO mapreduce.Job: Running job: job_1684399551458_0001
2023-05-18 16:53:27,721 INFO mapreduce.Job: Job job_1684399551458_0001 running in uber mode : false
2023-05-18 16:53:27,736 INFO mapreduce.Job: map 0% reduce 0%
2023-05-18 16:53:34,874 INFO mapreduce.Job: map 100% reduce 0%
2023-05-18 16:53:40,943 INFO mapreduce.Job: map 100% reduce 100%
2023-05-18 16:53:41,965 INFO mapreduce.Job: Job job_1684399551458_0001 completed successfully
2023-05-18 16:53:42,107 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=228
FILE: Number of bytes written=436267
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=365
HDFS: Number of bytes written=540
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=4697
Total time spent by all reduces in occupied slots (ms)=3612
Total time spent by all map tasks (ms)=4697
Total time spent by all reduce tasks (ms)=3612
Total vcore-milliseconds taken by all map tasks=4697
Total vcore-milliseconds taken by all reduce tasks=3612
Total megabyte-milliseconds taken by all map tasks=4809728
Total megabyte-milliseconds taken by all reduce tasks=3698688
Map-Reduce Framework
Map input records=11
Map output records=10
Map output bytes=202
Map output materialized bytes=228
Input split bytes=102
Combine input records=0
Combine output records=0
Reduce input groups=5
Reduce shuffle bytes=228
Reduce input records=10
Reduce output records=9
Spilled Records=20
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=157
CPU time spent (ms)=1840
Physical memory (bytes) snapshot=471650304
Virtual memory (bytes) snapshot=5561098240
Total committed heap usage (bytes)=358612992
Peak Map Physical memory (bytes)=270991360
Peak Map Virtual memory (bytes)=2777264128
Peak Reduce Physical memory (bytes)=200658944
Peak Reduce Virtual memory (bytes)=2783834112
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=263
File Output Format Counters
Bytes Written=540
然后我们查看我们的输出目录:
hdfs dfs -ls /output

红框所示就是我们需要的结果,我们将其下载下来进行查看:
hdfs dfs -get /output/part-r-00000 /root
vim part-r-00000

可以看见运行出我们想要的结果了。
如果你在hadoop jar SalesAnalysis.jar SalesDriver /input/sales.csv /output 这一步的时候运行出来的结果是空白然后查看打印信息发现出现Container [pid=32862,containerID=container_1684223917947_0013_01_000004] is running 506522112B beyond the 'VIRTUAL' memory limit. Current usage: 109.5 MB of 1 GB physical memory used; 2.6 GB of 2.1 GB virtual memory used. Killing container.这是因为容器使用的虚拟内存超出了限制而导致的。我们需要尝试通过命令行方式来增加虚拟内存限制。
我们需要修改yarn-site.xml文件信息,在文件中添加以下配置来增加虚拟内存限制:
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value> <!-- 增加虚拟内存限制的比例 -->
</property>
将上述代码添加到你的yarn-site.xml文件的configuration标签内,然后保存修改。这样,虚拟内存限制将会被调整为物理内存的四倍。请确保在添加新配置时保留文件中的其他配置项不变。
yarn-site.xml文件通常在hadoop安装目录的/etc/hadoop/目录下面,修改保存之后我们不需要重启HDFS,只需重启YARN服务即可让修改生效。
yarn --daemon stop resourcemanager
yarn --daemon start resourcemanager
这将停止和启动YARN的ResourceManager服务。在服务重启之后,新的yarn-site.xml配置将生效。
请注意,如果你使用了集群管理工具(如Ambari或Cloudera Manager),你可能需要使用工具提供的界面或命令来重启YARN服务。具体的重启方法可能因你的环境而有所不同,请根据你的情况进行相应的操作。
需要注意的是,对于某些修改可能需要重启整个Hadoop集群,包括HDFS和YARN服务。但在这种情况下,你通常会收到明确的提示和建议。文章来源:https://www.toymoban.com/news/detail-489119.html
重启之后我们再次执行上述命令就能顺利执行成功了。文章来源地址https://www.toymoban.com/news/detail-489119.html
到了这里,关于云计算中的大数据处理:尝试HDFS和MapReduce的应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!