一、引言
有个数据镜像系统每天0点会进行批量处理生成日表,随着数据量不断增大,处理时间从之前的一个小时,目前每天需要接近两小时,一旦继续延迟会影响BI、库存等很多任务。领导让博主进行优化提速。
博主从GC收集器、可数循环的安全点放置、CPU与线程搭配等多个方向进行分析实践。
二、提速方向
首先看一下代码
List<A> as = mapper.get(queryDTO, i);
if (CollectionUtils.isEmpty(as )) {
break;
}
/**------------**/
CountDownLatch latch;
if (as .size() < paramConfig.getInsertBatchQuantity()) {
latch = new CountDownLatch(1);
} else if (as .size() % paramConfig.getInsertBatchQuantity() == 0) {
latch = new CountDownLatch(assetCollects.size() / paramConfig.getInsertBatchQuantity());
} else {
latch = new CountDownLatch(as .size() / paramConfig.getInsertBatchQuantity() + 1);
}
Lists.partition(as , paramConfig.getInsertBatchQuantity()).forEach(a -> {
Runnable runnable = () -> {
try {
log.info("线程" + Thread.currentThread().getName() + "开始执行");
mapper.batchSave(a, tableName);
log.info("线程" + Thread.currentThread().getName() + "执行完成");
} catch (Exception e) {
log.error("数据镜像执行异常", e);
}
finally {
latch.countDown();
}
};
dbInsertExecutorService.execute(runnable);
});
latch.await();就是查数据再并发插入日表,原来的并发是根据查询数量/插入数量得出的,插入时需要使用同步器CountDownLatch等待插入都完成。
1、GC
一开始不想动代码,试着从数据查询语句和gc看看能不能加速,查询的sql也不复杂没什么好说的。
收集频率在60左右,minor gc在30ms左右,major gc在200ms左右,其实也能理解,毕竟数据在不断存取,很快就会失去引用链,所以回收密集也很正常。

那么有没有可能减少gc stop the world 的时间呢,看一下jvm的配置
javaagent:/app/skywalking/agent/skywalking-agent.jar -jar -Djava.security.egd=file:/dev/./urandom -server -Xms3998m -Xmx3998m -XX:MetaspaceSize=200m -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=3 -XX:GCLogFileS
ize=10m -Xmn1999m -Xloggc:/dev/shm/gc_%p.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:SurvivorRatio=8 -XX:-UseAdaptiveSizePolicy -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/app/logs/ /app/code/app.jar
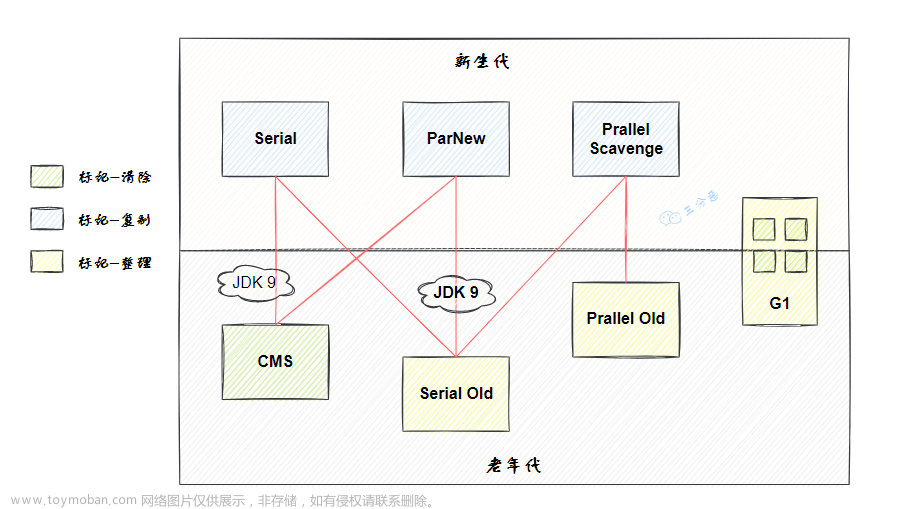
垃圾收集器没有特殊设置,那就是jdk8默认的UseParallelGC,这对收集器在收集过程中是需要stop the world的,目前能进行并发收集的用的比较多的是CMS、G1,分别是通过增量更新和原始快照的方式解决三色图标记问题,从而实现并发收集。
和运维部门协调修改jvm配置,使用G1看看处理提速情况,结果卡在了第一步,运维说所有系统jvm配置在生成发布镜像的时候都是拉取同一个Linux挂载路径下的文件,改动会影响其他系统,博主对于K8S的配置文件和发布镜像机制不是很了解,没法反驳,之前也有过类似的时候,这就是吃了没文化的亏。之前还有很多其他东西研究,现在有精力研究容器了,博主暗戳戳的买了《深入理解K8S》,准备后面找回所有的场子。
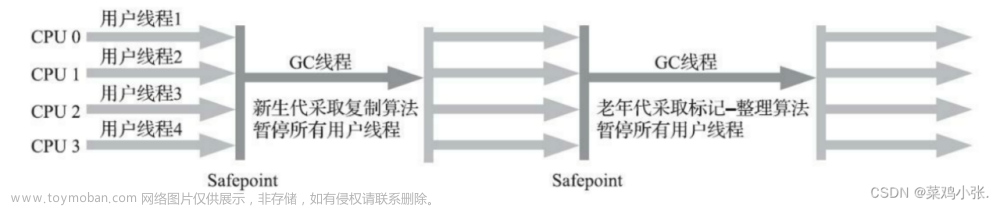
2、安全点
收集器走不通,看看其他方案,在《深入理解java虚拟机》中,作者提到过在可数循环当中jvm不会插入安全点,如果循环体执行的又是比较耗时的操作,就会导致gc收集的过程中需要等待线程进入安全点过久

那么功能符不符合这种情况呢 ,可以看出循环切分是可数循环,而循环体是开启一个线程插入数据库,那么网络io+数据库io也算是比普通的代码计算久的,那就改写一下试试看,但是最终结果提速只有几十秒,这个也被pass。
3、CPU&线程
以前的开发人员是使用线程池开启多线程,然后又使用了同步器阻塞这个过程,为什么不去掉同步器呢,如果是害怕队列中的数据可能因为宕机之类的原因丢掉,那么宕机本来就需要清空表之后重新插入的设计又是为什么呢
这里看一下线程池的配置,用ThreadPoolExecutor生成自定义线程池,按照使用规范设置有界队列,队列数量10个,问题出在拒绝策略,默认的拒绝策略是丢弃并且抛出异常,猜想以前的开发人员对于线程池的拒绝策略不是太了解,没有想过配置其他策略。
new ThreadPoolExecutor(poolProperties.getCorePoolSize(), poolProperties.getMaxPoolSize(),
poolProperties.getKeepAliveSeconds(), TimeUnit.SECONDS, new ArrayBlockingQueue<>(poolProperties.getMaxQueueSize()), factory);
博主把线程池的拒绝策略设置成了主线程执行,这也是博主在开发时常用的,感觉没有哪个业务是能把消息数据丢掉的。
new ThreadPoolExecutor(poolProperties.getCorePoolSize(), poolProperties.getMaxPoolSize(),
poolProperties.getKeepAliveSeconds(), TimeUnit.SECONDS, new ArrayBlockingQueue<>(poolProperties.getMaxQueueSize()), factory, new ThreadPoolExecutor.CallerRunsPolicy());
然后就是把同步器给去掉
// CountDownLatch latch;
// if (as.size() < paramConfig.getInsertBatchQuantity()) {
// latch = new CountDownLatch(1);
// } else if (as.size() % paramConfig.getInsertBatchQuantity() == 0) {
// latch = new CountDownLatch(as.size() / paramConfig.getInsertBatchQuantity());
// } else {
// latch = new CountDownLatch(as.size() / paramConfig.getInsertBatchQuantity() + 1);
// }
Lists.partition(as, paramConfig.getInsertBatchQuantity()).forEach(a-> {
Runnable runnable = () -> {
try {
log.info("线程" + Thread.currentThread().getName() + "开始执行");
assetService.batchSave(a, tableName);
log.info("线程" + Thread.currentThread().getName() + "执行完成");
} catch (Exception e) {
log.error("数据镜像执行异常", e);
}
// finally {
// latch.countDown();
// }
};
dbInsertExecutorService.execute(runnable);
});
// latch.await();线程池调整到了15个,结果速度反而还降了一些,思考了一下,这种属于io密集型(网络io+数据库io),线程没有什么计算,所以cpu只是进行了一个切分提交,然后就是等待io了,上下文切换再加上数据库主键自增锁可能反而是耗时的。
把线程和队列都调到了6,速度上来了,测试环境提升百分之十几
测试环境优化之前耗时

优化之后

再看一下线上
线上优化之前

线上优化之后

可以看出线上提速在百分之五十几文章来源:https://www.toymoban.com/news/detail-489232.html
三、总结
为了进行优化提速,博主从gc收集器->可数循环的安全点问题->线程池调整,多维度分析,希望同学们更多的看到其中的原理,比如安全点问题在一些高精度ms级别提速优化的可能性,收集器涉及的jvm知识可以用于许多优化和排查问题,建议大家看看《深入理解java虚拟机》,会有很多收获。文章来源地址https://www.toymoban.com/news/detail-489232.html
到了这里,关于数据批处理加速(GC收集器->安全点->线程池)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!