本文首发于微信公众号 CVHub,未经授权不得以任何形式售卖或私自转载到其它平台,违者必究!

Title: LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
Code: https://github.com/zrrskywalker/llama-adapter
PDF: https://arxiv.org/pdf/2303.16199.pdf
导读
Instruction-Following指令跟随方法:是指通过使用高质量的任务指令及其对应的输出,作为一些输入输出对,来进行模型微调,从而增强预训练模型以帮助模型更好地理解用户意图,生成更为准确的回答。
本文主要介绍了一种名为LLaMA-Adapter的轻量级适配方法,可以高效地将LLaMA模型微调为指令跟随模型Instruction-Following。该项目通过使用52k的self-instruction训练数据,冻结LLaMA 7B模型参数,并引入1.2M可学习参数,在8个A100 GPU上的微调时间不到1小时即可将LLaMA调整为良好的指令跟随模型,并且支持多模态(文本与图像)输入。LLaMA-Adapter可以自适应地将新的指令提示注入LLaMA中,同时有效地保留其预训练的知识不被破坏。 通过高效的训练,LLaMA-Adapter可以生成高质量的响应结果,其效果与完全微调7B参数的Alpaca相当。
引言
Alpaca利用大规模语言模型LLMs和self-instruction学习的方法,将LLMs Fine-tune为指令跟随模型。该模型可以理解并回答自然语言中的指令或命令。然而,LLMs完整的Fine-tune计算非常耗时,且不支持多模态,并且不易转移到不同的下游任务。 因此,本文介绍了一种名为LLaMA-Adapter的轻量级适应方法,该方法可以在LLaMA的基础上进行Fine-tune以更高效地将其转换为指令跟随模型,并且可以扩展到多模态输入。这种方法引入了可学习的适应提示,并将它们预置到更高的transformer层的输入文本标记中。通过零初始化的注意力机制和零门控机制,适应性地将新的指令提示注入LLaMA中,同时有效地保留其预训练知识,从而生成高质量的响应。
相比全微调的Alpaca模型,LLaMA-Adapter提高了资源利用率。具体而言:在LLaMA较高的transformer层中,添加一组可学习的适应性提示作为前缀prefix,以注入新的指令到LLaMA中。为了避免在早期训练阶段来自适应提示的噪声,作者修改了插入层的vanilla注意机制,将其作为可学习的门控因子进行零初始化。将门控因子通过零向量初始化,可以保留LLaMA中的原始知识,并在训练期间逐步融入指令信号。这有助于稳定学习过程,并提高最终模型的指令跟随能力。
总的来说,LLaMA-Adapter具有以下四个主要特点:
- 仅更新1.2M个参数。 相比于更新完整的7B参数,本项目在训练过程中冻结了预训练的LLaMA参数,并仅学习和更新顶端的适应性提示层参数(1.2M个参数)。结果表明它具有与7B Alpaca相当的指令跟随能力。
-
仅微调一小时。 由于轻量级参数和零初始化门控机制,
LLaMA-Adapter的收敛成本少于一小时,在8个A100 GPU上快于Alpaca三倍。 -
兼容性和灵活性高。 对于不同的场景或下游任务,只需插入相应的适配器,就可为
LLaMA注入不同的专业知识,所以这种适配器的方法是非常灵活的。因此,只需要为每个不同的下游任务配置一个1.2M的适配器,再共同连接一个7B模型,即可实现不同任务的适配,这种方式是非常灵活的。 -
支持多模态。 除了文本指令外,
LLaMA-Adapter还可以扩展到图像输入进行多模态推理。通过简单地将图像token添加到适应提示层中,LLaMA-Adapter在ScienceQA基准测试中表现出极具竞争力的结果。
方法
Learnable Adaption Prompts
基于 52 K 52K 52K条指令-输出数据和一个预训练的 N N N 层 LLaMA transformer 模型,使用一组可学习的适应性提示进行指令跟随 fine-tuning。作者将每个 transformer 层的适应性提示表示为 P l l = 1 L {P_l}_{l=1}^L Pll=1L,其中 P l ∈ R K × C P_l \in \mathbb{R}^{K\times C} Pl∈RK×C, K K K 表示每个层的提示长度, C C C 等于 LLaMA transformer 的特征维度。这些prompts被插入到 transformer 最上面的 L L L 层中 ( L ≤ N L \leq N L≤N),以更好地调整具有高层语义的语言表示。

如上公式所示, P l ∈ R K × C P_l \in R^{K \times C} Pl∈RK×C 表示第 l l l 层的适应性提示, K K K 表示每个层的提示长度, C C C 等于 LLaMA transformer 的特征维度。 T l T_l Tl 表示第 l l l 层的长度为 M M M 单词token。适应性提示将沿着token维度作为前缀与 T l T_l Tl 进行连接,以此来指导生成上下文响应。
::: block-1
LLaMA-Adapter模型可以通过轻量级的适配器来对预训练的LLaMA语言模型进行fine-tuning,使其适应指令跟随任务。适配器由可学习的提示层组成,并且插入到LLaMA的N个transformer层中的L out层。通过零初始化的注意力和门控机制,适应提示层Adaption Prompt可以逐步学习新的指令提示,而不干扰原有的预训练知识。
:::
Zero-init Attention
LLaMA-Adapter模型框架适配器机制通过在预训练语言模型的基础上,增加用于新任务的小量特定参数,从而提高其在多领域下的表现。其中,作者提出了零初始化注意力机制,避免了在训练初期,随机初始化的适配器带来的干扰,从而损害微调稳定性和有效性。作者提出了一个基于零初始化的注意力机制,并使用QKV机制使用可学习的门控因子自适应地控制注意力机制中适应性提示。在该机制下,作者对注意力得分进行了重组,以便根据门控因子自适应地调节适应性提示的作用,从而逐步将新获得的教学知识注入到LLaMA中。最终,通过线性投影层计算注意层的输出,并将其与预训练能力结合起来,提供高质量的响应能力。
Multi-modal Reasoning
LLaMA-Adapter 不仅限于文本指令,还能够基于其它模态的输入回答问题,这为语言模型增加了丰富的跨模态信息。如下图3所示,我们以 ScienceQA 基准测试为例。给定视觉和文本上下文,以及相应的问题和选项,模型需要进行多模态推理以给出正确的答案。
::: block-1
上图展示了LLaMA-Adapter在处理多模态输入上的框架图,在 ScienceQA 基准测试上,可将LLaMA-Adapter扩展为图像问答模式,在给定的图像视觉上下文中,通过多尺度连接和投影来获取全局图像 token。然后对插入层L的适应提示逐元素加上图像 token。通过这种方式,LLaMA-Adapter 模型在基于多模态输入下实现了有竞争力的生成结果。
:::
作为一个通用框架,LLaMA-Adapter 还可以扩展到视频和音频模态。使用预训练的模态特定编码器,我们可以将不同模态的指令信号集成到适应性提示中,从而进一步最大化 LLaMA 的理解和生成能力。
实验结果
::: block-1





这里将LLaMA-Adapter和一些代表性的指令跟随方法Alphaca进行了比较,并与Alpaca-LoRA和GPT-3进行了全面比较。由于缺乏严格的评估指标,这里只展示某些例子。如上图所示,通过仅微调1.2M个参数,LLaMA-Adapter方法生成了合理的响应,可与全参数微调的Alpaca和大规模的GPT-3相媲美。这充分证明了适配器和零初始化注意机制的有效性。
:::
::: block-1



这里将LLaMA-Adapter与LLaMA-I(即在大规模指令数据上微调的LLaMA-65B)进行了比较。如图所示,LLaMA-Adapter能够完成各种复杂任务,如对话生成、代码生成和问题回答等。另外,LLaMa-Adapter还可以通过结合更大的LLaMA模型、增加训练数据量和扩大可学习参数的规模来进一步提升性能。
:::
::: block-1
在上Table 3中,作者对不同指令跟随方法(Alpaca和Alpaca-LoRA)的可学习参数、存储空间和训练时间进行了比较。LLaMA-Adapter作为一种轻量级的即插即用模块,仅有1.2M的参数、4.9M的存储空间和1小时的训练时间。这使得我们能够在廉价和移动设备上对大规模语言模型LLaMA进行高效微调。
:::
::: block-1
在上Table 2中,作者将LLaMA-Adapter与其它较为流行的视觉问答模型进行了比较,并发现LLaMA-Adapter的单模态变体可以在只有1.2M参数的情况下实现78.31%的准确率。在注入视觉信息之后,LLaMA-Adapter的多模态变体获得了6.88%的准确率提高。与GPT-3相比,LLaMA-Adapter的参数数量较少,但性能仍然表现良好,尤其是在使用视觉信息时。此外,LLaMA-Adapter的多模态变体可以更容易地将视觉信息整合到模型中,从而实现更高的准确性。

上图Figure 4展示了LLaMA-Adapter处理多模态输入时的一些例子,其中视觉信息作为一种context上下文注入到模型中。
:::
::: block-1
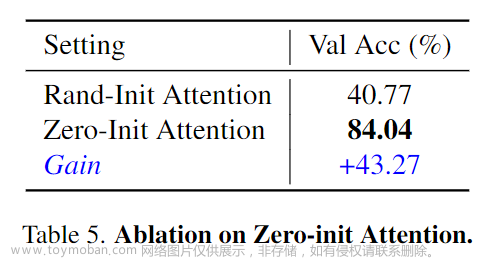

以上分别展示了Adapter中transformer层的数量消融实验(层数越多,可学习参数越大,精度一般越高);Zero-init Attention和随机Rand-init Attention的精度对比(Zero-init attention显著优于Rand-init attention);以及在训练过程中,Zero-init Attention和随机Rand-init Attention的Loss曲线变化
:::
结论
本文介绍了一种名为LLaMA-Adapter的轻量级适配方法,仅引入1.2M可学习参数,微调一小时即可将LLaMA调整为一个支持下游任务的良好模型,同时支持多模态(文本与图像)输入,并有效保留其原有预训练知识不被破坏。对于不同的场景或下游任务,只需在大模型前额外插入相应的适配器Adapter,即可为LLaMA注入不同领域的知识,兼容性与灵活性非常高。 欢迎各位尝试!(另外,LLaMA-Adapter V2版本已出,感兴趣的读者也可尝试)文章来源:https://www.toymoban.com/news/detail-489251.html
即日起,CVHub 正式开通知识星球,首期提供以下服务:文章来源地址https://www.toymoban.com/news/detail-489251.html
- 本星球主打知识问答服务,包括但不仅限于算法原理、项目实战、职业规划、科研思想等。
- 本星球秉持高质量AI技术分享,涵盖:每日优质论文速递,优质论文解读与知识点总结等。
- 本星球力邀各行业AI大佬,提供各行业经验分享,星球内部成员可深度了解各行业学术/产业最新进展。
- 本星球不定期分享学术论文思路,包括但不限于
Challenge分析,创新点挖掘,实验配置,写作经验等。 - 本星球提供大量 AI 岗位就业招聘资源,包括但不限于
CV,NLP,AIGC等;同时不定期分享各类实用工具、干货资料等。
到了这里,关于上海人工智能实验室发布LLaMA-Adapter | 如何1小时训练你的多模态大模型用于下游任务的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!










