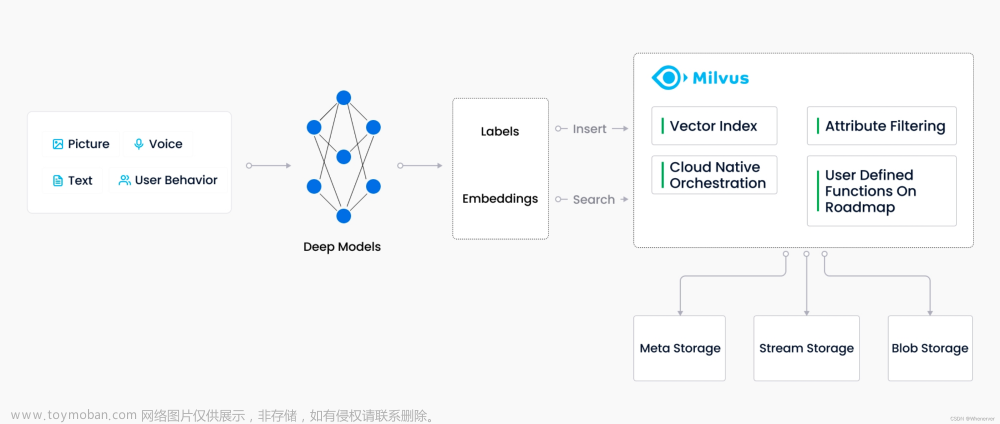
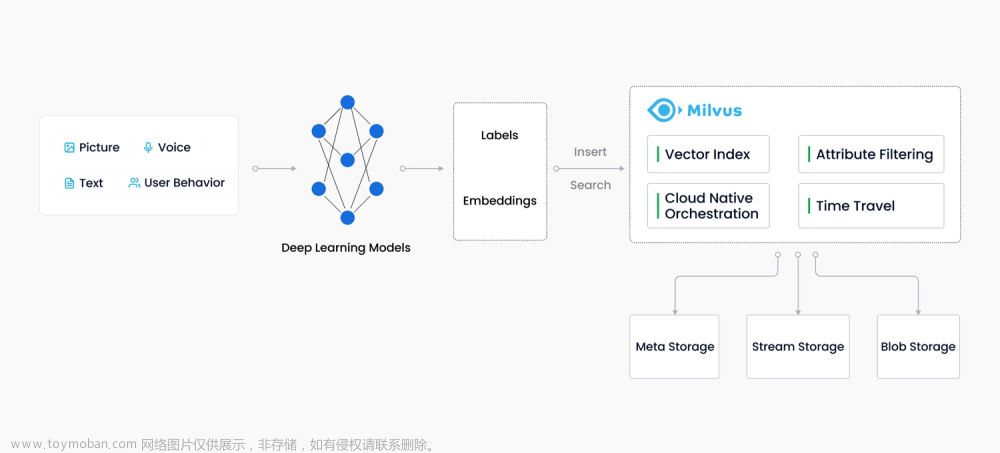
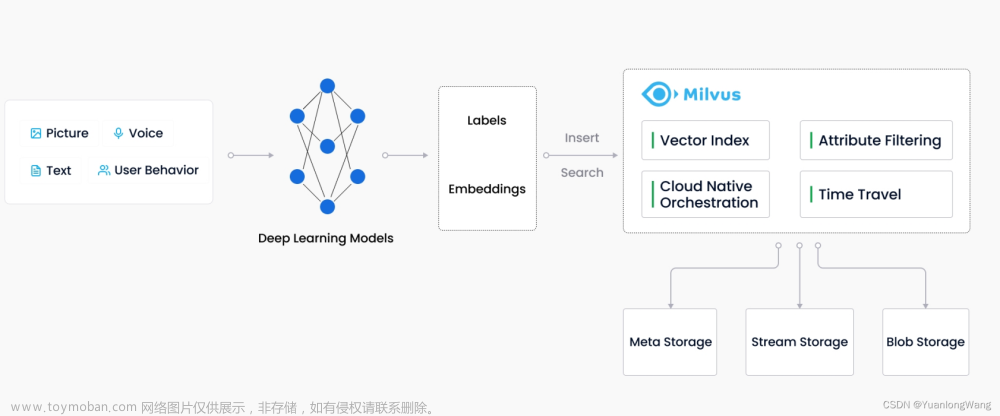
向量数据库

代理
proxy对外的代理(入口)
协调器
总控制 root coord
query coord 查询协调器
data coord 插入协调器
index coord 索引协调器
2.3把 datacoord和indexcoord 合并
任务包括集群拓扑管理、负载平衡、时间戳生成、数据声明和数据管理
Coordinator HA高可用
1打开配置项 queryCoord.enableActiveStandby=true
2部署时启动两个 QueryCoord 节点,两者会按照启动先后顺序成为主备节点,当主节点不可用时,备用节点会成为新的 coordinator,这大大增强了系统的可用性。
执行节点
query node 查询执行
data node 插入执行
index node 索引执行
高可用易拓展
各个节点都是独立的解耦非常好,比如如果查询够不上了就多个部署个查询节点
第三方对接
etcd(存储元信息(比如集合名称)和服务发现)
kafka/pulsar 数据日志部分,(类似于管道)通过订阅来走数据插入的。(保证流通) 2.3 正在基于NATS做自己的消息队列(正在实验阶段)
minio/s3 对象存储(数据落地的地方)
注意这仨都很重要 建议单独做集群或者备份处理
跟关系型数据库的比对
Milvus向量数据库 关系型数据库
Collection 表
Entity 行
Field 表字段
集合Collection
集合(类似关系型数据库的表)
1)创建必须包含一个主键(INT64或String类型,自动生成的目前不是唯一的,最好自己指定)和矢量字段
2)创建可以指定分片(Shards)数量(默认是2),为了多节点并行插入
3)可以动态设置数据过期时间,我的理解是数据删除的时候不是真的删了,等到刷新时间才删除。(目前只有python支持)默认是0
4)可以查看是否存在集合,查看集合详细信息,查看所有集合
5)可以删除集合,集合里的数据也都不可逆的删除
6)取别名,删除别名
7)可以将集合加载到缓存,加快查询速度和吞吐量都增加了(内存注意占90%以下)
8)加载到缓存的,查询后,可以释放掉。空出资源。
分区Partition
分区: Milvus 支持将收集数据划分为物理存储上的多个部分。这个过程称为分区,每个分区可以包含多个段。
可以做到:
1:指定集合,创建分区 ,如果不指定 默认_default分区
2:1)集合里是否有指定分区。2)可以查询某个集合里所有的分区
3:可以删掉某个分区。删除分区后会不可逆的删除分区的数据。
4:可以将某个分区加载到缓存里。相比集合加载到分区,减少内存的使用。(加载多副本可以让空闲的查询节点利用上。目前加载成多副本,只有python支持)
5:加载到缓存的,查询后,可以释放掉。空出资源。
注意: 分区的意义在于通过划定分区减少数据读取,而分片的意义在于多台机器上并行写入操作。
Segment
分段:通过合并数据自动创建的数据文件。一个 collection 可以包含多个 segment。一个 segment 可以包含多个 entity。在搜索中,
Milvus 会搜索每个 segment,并返回合并后的结果。
Sharding
分片:Shard 是指将数据写入操作分散到不同节点上,使 Milvus 能充分利用集群的并行计算能力进行写入。默认情况下,单个 Collection 包含 2 个分片(Shard)。目前 Milvus 采用基于主键哈希的分片方式,未来将支持随机分片、自定义分片等更加灵活的分片方式。
数据管理
目前已经有了VARCHAR标量数据。(里面可以存储图片名称之类的)可以查询和索引
插入:
插入的时候可以指定Partition分区,插入到指定分区。
插入的时候组织的是一列一列的数据不是一行一行的。
批量插入:
json格式:{
“rows”:[
{“book_id”: 101, “word_count”: 13, “book_intro”: [1.1, 1.2]},
{“book_id”: 102, “word_count”: 25, “book_intro”: [2.1, 2.2]},
{“book_id”: 103, “word_count”: 7, “book_intro”: [3.1, 3.2]},
{“book_id”: 104, “word_count”: 12, “book_intro”: [4.1, 4.2]},
{“book_id”: 105, “word_count”: 34, “book_intro”: [5.1, 5.2]}
]
}
1)rows的名字不能改
2)book_intro是有要求的 请看官网
1)json文件批量插入,减少了Milvus客户端、代理、Pulsar和数据节点之间的网络传输
2)如果是新版本 要把文件存储到milvus.yml里面配置的minio.bucketName
3)只支持一个文件
4)由于批量插入是异步的,可以查看批量插入的状态
5)可以查看所有插入任务的列表
6)MilvusDM:批量插入的工具
删除:
通过主键删除,删除后如果consistency level(数据一致性)比Strong低是可以被立即被查询和恢复的,但超出指定时间外就不可以了。
删除频繁会影响性能的。
删除只能用主键当条件并用in(主键 in [0,1] 删除主键是0和1的数据 ),不能用其他字段。
压缩数据:
默认是压缩的,可以配置,当配置不压缩,也可以手动压缩
Milvus在common.retensionDuration中指定的范围内保留数据操作日志不被压缩。可以保留时间内查询的准确性。(不压缩查的准,压缩数据小,所以按实际情况指定时间范围内不压缩,范围外压缩)
压缩是异步的很耗时
可以查看压缩状态
索引 index
向量索引,查询索引相似的,如果不建立索引,就是暴力查询。
默认情况下 数据少于1024不能被建立索引。想要更改milvus.yaml里rootCoord.minSegmentSizeToEnableIndex的配置
如果是标量索引不用索引构建参数,默认类型是字典树
建立索引需要指定算法
索引可建立,可删除,一个向量字段只能有一个向量。
IndexType:索引类型
for floating point vectors:
HNSW:(2.3说RHNSW也删掉了不知道是不是一个)
不差钱,性能高,精准度高,内存高。
适用:同时要求性能和精准度,如果大数据量需要不差钱。
FLAT:
不压缩向量(唯一可以保证精确搜索结果的索引),性能稍低,精准度最高,内存占用仅次于HNSW。
适用:要求精准度,对性能要求低,且数据集相对较小。(不建议大数据量,因为当查询一个 它会把所有数据拿出来一个一个对比。)(百万规模)可以用作别的结果对错的标杆。
IVF_FLAT :
和FLAT的区别,类似调表的索引,设置nlist将向量数据划分多少组,然后比较目标输入向量与每个聚类中心之间的距离, 查询的时候设置nprobe 比如设置3 就找离搜索向量最的近3个组里的数据挨个去对比。
特点 相对来说节省资源,对精准度有一定损失 但不大
推荐参数设置
nlist:4 × sqrt(n) n是一段数据有多少个实体,datacoord.segment.maxSize( 默认512 MB )除以每个实体的大小就可以获得多少个实体。
nprobe:根据实际情况做调节。
IVF_SQ8:
有数据压缩(内存节省70–75%),资源受限的时候可以用IVF_SQ8代替IVF_FLAT,精度减少了
IVF_PQ:
把高维数据变成多个低维数据,进一步节省资源可以用IVF_PQ,精度更小
ANNOY:(低纬度向量)树形索引…官网上有介绍但没说啥适用范围啥的。网上视频介绍都把它放过了没介绍它。就先这样。以后遇到了在补充(2.3版本已经删掉了)
DISKANN:
磁盘索引,内存消耗最小的。需要很高性能的SSD。需要自己编译
也不是完全不用内存。是你全部用内存的1/6算。
要求 :
Ubuntu 18.04.6以上版本
float向量,至少32维以上
L2或者IP来测量向量之间的距离
下面是两个GPU索引
GPU_IVF_FLAT* (GPU_IVF_FLAT)
GPU_IVF_PQ*> (GPU_IVF_PQ)
上面索引资源节省从上到下是一步一步 越来越节省的。
For binary vectors:
BIN_FLAT
BIN_IVF_FLAT
(这俩跟上面FLAT,IVF_FLAT )类似只不过是二进制的。
距离计算公式
浮点型向量主要使用以下距离计算公式:
欧氏距离 (L2): 主要运用于计算机视觉领域。
内积 (IP): 主要运用于自然语言处理(NLP)领域。
余弦(COSINE),如果做了标准化 ip很cosine是一样的。如果没做用cosine处理nlp领域
二值型向量主要使用以下距离计算公式:
汉明距离 (Hamming): 主要运用于自然语言处理(NLP)领域。
杰卡德距离 (Jaccard): 主要运用于化学分子式检索领域。
谷本距离 (Tanimoto): 主要运用于化学分子式检索领域。
超结构 (Superstructure): 主要运用于检索化学分子式的相似超结构。
子结构 (Substructure): 主要运用于检索化学分子式的相似子结构。
查询
search :先要加载集合到缓存–>然后在查询–>最后清理掉集合缓存。比较好理解 用法参考官网。
查询的结果是最相似的,应该是相似度由高到低有顺序的。
Hybrid Search:标量矢量混合搜寻。跟search一样只是多出了个表达式比如 字段值>100当条件。
query:标量查询条件可以查出向量的意思 感觉没啥用。
时间点的查询:可以查询历史默认432,000s内的可以查询。其他的被压缩了。common.retensionDuration可以配置这个保留时间。
管理指南
由于我只会docker,所以都是基于docker的管理处理
1下载milvus.yaml里面都是各个节点的配置,根据情况修改
2下载milvus-cluster-docker-compose.yml
3把compose文件里每个节点都添加volumes,然后把milvus.yaml映射到下载的milvus.yaml
4然后启动docker-compose,这样就启动了
milvus.yaml的详解我会在部署测试的时候把每个参数写上说明。后续把文件贴上来用作更新
部署到云
AWS,GCP,Azure。官网提供的,目前用不上,暂时先放着。如有有对应,补充。
添加和缩放节点
注意能够动态的 是无状态节点:数据节点,查询节点,索引节点,代理。协调器是主备
监视器和报警
Prometheus和Grafana
RBAC权限
目前只有java和python支持
角色分配可用集合或者分区–>给用户属于某个角色(这样用户就拥有权限了)
这些操作都是可以删除和解绑的(不可逆)。
安全
说白了就是如何用户验证
1启动用户验证milvus.yaml里common.security.authorizationEnabled 设置为 true
2当链接集合的时候需要配置用户名密码(关于长度之类的有要求,详细看文档)。
默认情况下,根用户(用户名:root,密码:Milvus)与每个Milvus实例一起创建。建议您在首次启动Milvus时密码。根用户可用于创建新用户以进行身份验证访问。
Encryption in Transit传输层加密 TLS (Transport Layer Security)
1创建证书
2在milvus.yaml里配置
1)tlsEnabled为true,
2)tls:
serverPemPath: configs/cert/server.pem
serverKeyPath: configs/cert/server.key
caPemPath: configs/cert/ca.pem
(设置生成的证书)=
3)链接的时候带上相应的证书
分单项认证和双向认证,所要的证书不同。
管理工具
Milvus_CLI:交互式命令行,基于python
MilvusDM :数据迁移,只支持1.x(可以不考虑)
Attu:服务可视化,Zilliz.一个开源项目. 文档最多比较官方
Milvus sizing tool:容量评估
注意
建议部署用Kubernetes(k8s)
Milvus 2.2.0以上搜索速度有显著提高。
你下载的版本和代码里引入的版本必须一致
关于不停机滚动升级:只有通过 helm 部署的 Milvus 集群支持滚动升级,Operator 部署暂不支持。
插入不占用cpu,但耗资源。比如有kafka,流传输什么的。
Milvus float只保留7位小数。多了会删掉。
ttl时间:可以把过期数据做一个自动删除
2.3
开始支持arm64版服务器
支持英伟达GPU,正在做升腾GPU适配。
GPU查询速度快3到10倍
不要使用时间旅行功能,
停止了CentOS 支持文章来源:https://www.toymoban.com/news/detail-489281.html
支持了CDC
通常用于主动/备用数据同步、增量数据备份和数据迁移等场景。 https://github.com/zilliztech/milvus-cdc.文章来源地址https://www.toymoban.com/news/detail-489281.html
到了这里,关于milvus文档的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!