Kaggle入门赛-手写数字识别所使用的数据集MNIST是计算机视觉上的“Hello world”数据集。这个经典的手写图像数据集一直作为基准分类算法的基础。随着新的机器学习技术的出现,MNIST仍然是研究人员和学习者的可靠资源。
本文所介绍的算法通过使用一个多层感知机来完成手写数字的识别。本文通过数据预处理与可视化、模型搭建与训练、模型结果预测等方面来介绍如何从kaggle下载数据集,并通过处理后的数据集训练模型,再到最后如何将模型预测的结果提交到kaggle。
Digit Recognizer(手写数字识别)比赛网址:https://www.kaggle.com/competitions/digit-recognizer/
1、数据处理与可视化
通过kaggle官网下载手写数据识别的数据集,如下图所示,下载的数据集有三个文件分别为train.csv,test.csv,sample_submission.csv,其中train.csv为训练集包含标签和手写数字图像,test.csv为测试集只包含手写数字图像不包含标签,sample_submission.csv为提交示例。更多详细的内容可查看官方的数据集介绍。

首先导入所使用的相关包。
import pandas as pd
import numpy as np
import torch
import torch.utils.data as data
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torch import nn
%matplotlib inline
导入训练集,并输出训练集前五条数据,可以看出训练集的第一列为标签值,后面783列为28×28图像的像素值的展开后的格式,训练集共有42000条数据。
df = pd.read_csv('train.csv')
print(df.head())
print(df['label'].count())
label pixel0 pixel1 pixel2 pixel3 pixel4 pixel5 pixel6 pixel7 \
0 1 0 0 0 0 0 0 0 0
1 0 0 0 0 0 0 0 0 0
2 1 0 0 0 0 0 0 0 0
3 4 0 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0 0 0
pixel8 ... pixel774 pixel775 pixel776 pixel777 pixel778 pixel779 \
0 0 ... 0 0 0 0 0 0
1 0 ... 0 0 0 0 0 0
2 0 ... 0 0 0 0 0 0
3 0 ... 0 0 0 0 0 0
4 0 ... 0 0 0 0 0 0
pixel780 pixel781 pixel782 pixel783
0 0 0 0 0
1 0 0 0 0
2 0 0 0 0
3 0 0 0 0
4 0 0 0 0
[5 rows x 785 columns]
42000
然后对训练集进行处理,将标签与图像分开。然后将标签与图像的值转为pytorch中的tensor,数据类型为浮点型。由于是分类任务,因此将标签转为one-hot编码。
首先从数据中将标签取出,然后将数据类型转为tensor。
#从数据中将标签取出,然后将数据类型转为tensor
labels=torch.from_numpy(np.array(df['label']))
labels
tensor([1, 0, 1, ..., 7, 6, 9])
然后将标签值转为one-hot编码。torch.sparse实现稀疏张量,然后通过eye函数生成一个10维的单位矩阵,最后通过index_select(input, dim, index)函数生成one-hot编码,该函数在dim维度上将input中索引为index的值保存下来,从而得到labels的one-hot编码。
#转为one-hot
#生成单位矩阵
ones = torch.sparse.torch.eye(10)
print(ones)
#根据指定索引和维度保留单位矩阵中的一条数据即为one-hot编码
label_one_hot=ones.index_select(0,labels)
print(label_one_hot[0],labels[0])
tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]])
tensor([0., 1., 0., 0., 0., 0., 0., 0., 0., 0.]) tensor(1)
将训练集中的图像部分转为tensor的浮点类型
df.pop('label')
#将训练集转为tensor
imgs=torch.from_numpy(np.array(df))
imgs = imgs.to(torch.float32)
定义构建数据集以及训练时所用的一些参数
#相关参数
#训练时的批量大小
train_batch_size=64
#训练轮次
num_epoches=20
#学习率
lr=0.01
通过DataLoader构造一个Pytorch数据迭代器,获得指定batch_size的数据迭代器,便于在训练时取出指定batch_size的训练数据。
#构造一个Pytorch数据迭代器
def load_array(data_arrays,batch_size,is_train=True):
#加星号说明为元组
#TensorDataset 可以用来对 tensor 进行打包
dataset=data.TensorDataset(*data_arrays)
return data.DataLoader(dataset,batch_size,shuffle=is_train)
train_data=load_array((imgs,label_one_hot), batch_size=train_batch_size)
数据可视化,从生成的数据中随机抽取进行可视化并展示标签值。
#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
exaples=enumerate(train_data)
#next() 返回迭代器的下一个项目
batch_idx,(example_img,example_label) = next(exaples)
fig=plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_img[i].reshape(28,28),cmap='gray',interpolation='none')
_,prd=example_label[i].max(0)
plt.title('Ground Truth:{}'.format(prd))
plt.xticks([])
plt.yticks([])

2、模型搭建与训练
将数据处理完成之后,接下来就是定义模型,并使用处理好的数据对模型进行训练的阶段了,在此使用了一个多层感知机网络进行手写数字识别。
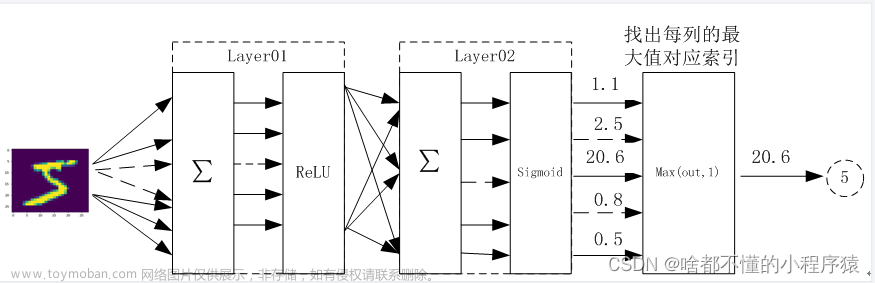
首先搭建用于模型训练的网络模型。在这里使用了一个三层的多层感知机,在每个线性层之后都使用了批量归一化以防止梯度消失的问题,激活函数选用了ReLU激活函数也更好的避免了梯度消失的问题。
class Net(nn.Module):
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(Net,self).__init__()
self.layer1=nn.Sequential(nn.Linear(in_dim,n_hidden_1),nn.BatchNorm1d(n_hidden_1))
self.layer2=nn.Sequential(nn.Linear(n_hidden_1,n_hidden_2),nn.BatchNorm1d(n_hidden_2))
self.layer3=nn.Sequential(nn.Linear(n_hidden_2,out_dim))
def forward(self,x):
x=F.relu(self.layer1(x))
x=F.relu(self.layer2(x))
x=self.layer3(x)
#x=F.softmax(self.layer3(x))
return x
下面就可以实例化我们定义的模型,手写数字图片共有784个像素值,因此输入为784维,两个隐藏层的大小分别问300和100,最后输出层维度为10将数字分为0-9十类。为加快训练速度并在有GPU的条件下,可将模型放到GPU上训练。
#检测是否有可用的设备
device=torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
#实例化网络
model=Net(784,300,100,10)
model.to(device)
Net(
(layer1): Sequential(
(0): Linear(in_features=784, out_features=300, bias=True)
(1): BatchNorm1d(300, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(layer2): Sequential(
(0): Linear(in_features=300, out_features=100, bias=True)
(1): BatchNorm1d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(layer3): Sequential(
(0): Linear(in_features=100, out_features=10, bias=True)
)
)
定义损失函是和优化器,损失函数采用交叉熵损失函数,优化器使用Adam,该优化算法可以动态改变学习率。
#损失函数和优化器
criterion=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters(),lr=lr,betas=(0.9,0.99))
然后就可以训练训练我们的模型了
#训练网络
losses=[]
acces=[]
for epoch in range(num_epoches):
train_loss=0
train_acc=0
model.train()
for img,label in train_data:
#将图片和标签放入GPU设备
img=img.to(device)
label=label.to(device)
#计算结果
out=model(img)
#计算损失
loss=criterion(out,label)
#将梯度清零
optimizer.zero_grad()
#反向传播
loss.backward()
#更新网络参数
optimizer.step()
#记录训练损失
train_loss+=loss.item()
#记录训练准确度
_,pred=out.max(1)
l,pred1=label.max(1)
num_correct=(pred==pred1).sum().item()
acc=num_correct/img.shape[0]
train_acc+=acc
losses.append(train_loss/len(train_data))
acces.append(train_acc/len(train_data))
print('epoch:{},Train Loss:{:.4f},Train Acc:{:.4f}'.format(epoch,train_loss/len(train_data),train_acc/len(train_data)))
epoch:0,Train Loss:0.2226,Train Acc:0.9309
epoch:1,Train Loss:0.1126,Train Acc:0.9655
epoch:2,Train Loss:0.0823,Train Acc:0.9739
epoch:3,Train Loss:0.0623,Train Acc:0.9799
epoch:4,Train Loss:0.0526,Train Acc:0.9829
epoch:5,Train Loss:0.0450,Train Acc:0.9854
epoch:6,Train Loss:0.0378,Train Acc:0.9879
epoch:7,Train Loss:0.0351,Train Acc:0.9889
epoch:8,Train Loss:0.0313,Train Acc:0.9897
epoch:9,Train Loss:0.0254,Train Acc:0.9911
epoch:10,Train Loss:0.0259,Train Acc:0.9912
epoch:11,Train Loss:0.0255,Train Acc:0.9920
epoch:12,Train Loss:0.0242,Train Acc:0.9924
epoch:13,Train Loss:0.0217,Train Acc:0.9935
epoch:14,Train Loss:0.0207,Train Acc:0.9933
epoch:15,Train Loss:0.0218,Train Acc:0.9930
epoch:16,Train Loss:0.0197,Train Acc:0.9942
epoch:17,Train Loss:0.0192,Train Acc:0.9942
epoch:18,Train Loss:0.0180,Train Acc:0.9941
epoch:19,Train Loss:0.0171,Train Acc:0.9943
最终的准确率达到了99%多,看起来结果很不错,但这只是在训练集上的结果,在测试集上就不可能达到这个结果了。
将训练准确度和训练损失数值进行可视化,直观观察训练的结果。
plt.title('train loss and acc')
plt.plot(np.arange(len(losses)),losses)
plt.plot(np.arange(len(losses)), losses, color='red',label='Train Loss')
plt.plot(np.arange(len(losses)),acces, color='green', label='Train Acc')
plt.legend()
<matplotlib.legend.Legend at 0x2ded4f62fc8>

3、模型预测结果
模型训练完成之后,就可以使用训练集中的数据生成最终的结果,然后将结果上传到kaggle就可以看到我们的模型在测试集上到底可以得到多少分数了。
首先我们先处理一下测试集,将数据转为tensor的float32类型。
#读取测试集
df_test = pd.read_csv('test.csv')
test_imgs=torch.from_numpy(np.array(df_test))
test_imgs = test_imgs.to(torch.float32)
test_imgs
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
将测试集放到GPU上,然后传入训练好的模型中得到预测的结果,并转为DataFrame类型便于生成上传到kaggle的结果集。
#test_img=torch.unsqueeze(test_imgs[0],0)
test_imgs=test_imgs.to(device)
_,pre=model(test_imgs).max(1)
res={}
pre = pre.cpu().numpy()
pre_size=pre.shape[0]
num = [i for i in range(1,pre_size+1)]
res_df=pd.DataFrame({
'ImageId':num,
'Label':pre
})
查看结果的前五行。
res_df.head()
| ImageId | Label | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 2 | 0 |
| 2 | 3 | 9 |
| 3 | 4 | 9 |
| 4 | 5 | 3 |
将结果输出到csv文件中。
res_df.to_csv('res.csv',index=False)
最后,将结果上传到kaggle中,就可以查看到模型在测试集上的准确率。

最终使用多层感知机可以达到0.97846的结果,后面会在使用卷积神经网络测试一下可以达到多少准确率,后面在更新。。。
4、代码整合
数据处理、模型搭建、模型训练部分,去掉了数据可视化和训练结果可视化部分。文章来源:https://www.toymoban.com/news/detail-489282.html
import pandas as pd
import numpy as np
import torch
import torch.utils.data as data
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torch import nn
%matplotlib inline
#读取数据
df = pd.read_csv('train.csv')
#从数据中将标签取出,然后将数据类型转为tensor
labels=torch.from_numpy(np.array(df['label']))
#转为one-hot
ones = torch.sparse.torch.eye(10)
label_one_hot=ones.index_select(0,labels)
#将标签给从数据集中删除,得到训练集的输入数据
df.pop('label')
#将训练集转为tensor
imgs=torch.from_numpy(np.array(df))
imgs = imgs.to(torch.float32)
#相关参数
train_batch_size=64
num_epoches=20
lr=0.01
#构造一个Pytorch数据迭代器
def load_array(data_arrays,batch_size,is_train=True):
#加星号说明为元组
#TensorDataset 可以用来对 tensor 进行打包
dataset=data.TensorDataset(*data_arrays)
return data.DataLoader(dataset,batch_size,shuffle=is_train)
train_data=load_array((imgs,label_one_hot), batch_size=train_batch_size)
#模型搭建
class Net(nn.Module):
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(Net,self).__init__()
self.layer1=nn.Sequential(nn.Linear(in_dim,n_hidden_1),nn.BatchNorm1d(n_hidden_1))
self.layer2=nn.Sequential(nn.Linear(n_hidden_1,n_hidden_2),nn.BatchNorm1d(n_hidden_2))
self.layer3=nn.Sequential(nn.Linear(n_hidden_2,out_dim))
def forward(self,x):
x=F.relu(self.layer1(x))
x=F.relu(self.layer2(x))
x=self.layer3(x)
#x=F.softmax(self.layer3(x))
return x
#检测是否有可用的设备
device=torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
#实例化网络
model=Net(784,300,100,10)
model.to(device)
#损失函数和优化器
criterion=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters(),lr=lr,betas=(0.9,0.99))
#训练网络
losses=[]
acces=[]
for epoch in range(num_epoches):
train_loss=0
train_acc=0
model.train()
#动态修改学习率
# if epoch%5==0:
# optimizer.param_groups[0]['lr']*=0.1
for img,label in train_data:
img=img.to(device)
label=label.to(device)
out=model(img)
loss=criterion(out,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss+=loss.item()
_,pred=out.max(1)
l,pred1=label.max(1)
num_correct=(pred==pred1).sum().item()
acc=num_correct/img.shape[0]
train_acc+=acc
losses.append(train_loss/len(train_data))
acces.append(train_acc/len(train_data))
print('epoch:{},Train Loss:{:.4f},Train Acc:{:.4f}'.format(epoch,train_loss/len(train_data),train_acc/len(train_data)))
epoch:0,Train Loss:0.2245,Train Acc:0.9318
epoch:1,Train Loss:0.1169,Train Acc:0.9640
epoch:2,Train Loss:0.0832,Train Acc:0.9728
epoch:3,Train Loss:0.0623,Train Acc:0.9805
epoch:4,Train Loss:0.0499,Train Acc:0.9840
epoch:5,Train Loss:0.0438,Train Acc:0.9859
epoch:6,Train Loss:0.0395,Train Acc:0.9873
epoch:7,Train Loss:0.0314,Train Acc:0.9895
epoch:8,Train Loss:0.0307,Train Acc:0.9899
epoch:9,Train Loss:0.0274,Train Acc:0.9910
epoch:10,Train Loss:0.0259,Train Acc:0.9915
epoch:11,Train Loss:0.0237,Train Acc:0.9919
epoch:12,Train Loss:0.0243,Train Acc:0.9922
epoch:13,Train Loss:0.0226,Train Acc:0.9927
epoch:14,Train Loss:0.0199,Train Acc:0.9937
epoch:15,Train Loss:0.0192,Train Acc:0.9937
epoch:16,Train Loss:0.0194,Train Acc:0.9934
epoch:17,Train Loss:0.0177,Train Acc:0.9944
epoch:18,Train Loss:0.0179,Train Acc:0.9947
epoch:19,Train Loss:0.0177,Train Acc:0.9944
结果预测以及导出为csv文件部分文章来源地址https://www.toymoban.com/news/detail-489282.html
#读取测试集
df_test = pd.read_csv('test.csv')
test_imgs=torch.from_numpy(np.array(df_test))
test_imgs = test_imgs.to(torch.float32)
#测试集预测部分
#传入GPU
test_imgs=test_imgs.to(device)
#计算结果
_,pre=model(test_imgs).max(1)
#将结果转为提交kaggle的格式
res={}
pre = pre.cpu().numpy()
pre_size=pre.shape[0]
num = [i for i in range(1,pre_size+1)]
res_df=pd.DataFrame({
'ImageId':num,
'Label':pre
})
#d导出为CSV文件
res_df.to_csv('res.csv',index=False)
到了这里,关于Kaggle入门赛-Digit Recognizer(手写数字识别)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!