提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:以下本章里有大量作者自己的口水话和心里对白,请谨慎观看,若有不适,后果自负!
一、很简单的BP神经网络例题——公路运量预测
这部分学习内容以及代码参考(抄袭)了教材《matlab在数学建模中的应用》(第二版 主编:卓金武),加入了大量我自己的思考内容。若侵删。这本书是从教研室的80年代大书柜里面找出来的,应该是师姐姐姐姐或者师哥哥哥哥留下的。
1.1.题目描述
题目描述如下所示:

使用神经网络工具箱,解题matlab代码如下所示:
clc;
close all;
clear all;
%数据
sqrs=[20.55,22.44,25.37,27.13,29.45,30.10,30.96,34.06,36.42,38.09,39.13,39.99...
41.93,44.59,47.30,52.89,55.73,56.76,59.17,60.63];%人数
sqjdcs=[0.6,0.75,0.85,0.9,1.05,1.35,1.45,1.6,1.7,1.85,2.15,2.2,2.25,2.35,2.5,2.6...
2.7,2.85,2.95,3.1];%机动车数
sqglmj=[0.09,0.11,0.11,0.14,0.20,0.23,0.23,0.32,0.32,0.34,0.36,0.36,0.38,0.49...
0.56,0.59,0.59,0.67,0.69,0.79];%公路面积
glkyl=[5126,6217,7730,9145,10460,11387,12353,15750,18304,19836,21024,19490,20433....
22598,25107,33442,36836,40548,42927,43462];%公路客运量
glhyl=[1237,1379,1385,1399,1663,1714,1834,4322,8132,8936,11099,11203,10524,11115....
13320,16762,18673,20724,20803,21804];%公路货运量
%输入数据矩阵 3*20
p=[sqrs;sqjdcs;sqglmj];
%目标数据矩阵 2*20
t=[glkyl;glhyl];
%归一化
[pn,input_str]=mapminmax(p);
[tn,output_str]=mapminmax(t);
%建立BP神经网络
net=newff(pn,tn,[3 7 2],{'purelin','logsig','purelin'});
net.trainParam.show=10;%每十次显示一次结果
net.trainParam.lr=0.05;%设置学习率
net.trainParam.epochs=5000;%最大训练次数为5000
net.trainParam.goal=0.65*10^(-3);%目标误差
net.divideFcn=''; %所有样本用以训练
net=train(net,pn,tn);%开始训练
%仿真
an=sim(net,pn);%使用训练好的网络进行仿真
a=mapminmax('reverse',an,output_str);%对数据反归一化,恢复原貌
%画图
x=1990:2009;
newk=a(1,:);%网络输出客运量
newh=a(2,:);%网络输出货运量
figure(2);
%公路客运量对比图
subplot(2,1,1);
plot(x,newk,'r-o',x,glkyl,'b--+');
legend('网络输出客运量','实际客运量');
xlabel('年份');ylabel('客运量/万吨');
title('客运量对比图')
%公路货运量对比图
subplot(2,1,2);
plot(x,newh,'r-o',x,glhyl,'b--+');
legend('网络输出货运量','实际货运量');
xlabel('年份');ylabel('货运量/万吨');
title('货运量对比图')
%使用网络进行预测
pnew=[73.39,75.55
3.9635 4.0975
0.9880,1.0268];
pnewn=mapminmax('apply',pnew,input_str);%
anewn=sim(net,pnewn);
anew=mapminmax('reverse',anewn,output_str);
1.2.题目分析
本题中,给出了三个自变量:人数(sqrs),机动车数量(sqjdcs),公路面积(sqglmj);同时给出了两个因变量:公路客运量(glkyl),公路货运量(glhyl).
在大数据的情况下,会不会存在一种规律,也就是三个自变量取不同的值,那么因变量就会给出对应的值?BP神经网络的作用就是来干这个的。
1.3.代码分析
以前,我可能是个调参侠,现在,一定要细枝末节的问题弄明白。
1.3.1 数据输入
输入数据这个比较简单,没有什么太难理解的地方。就是每次输数据的时候有点累(不过肯定有那种比较简单的方法,比如直接从EXCEL里面导入的方法,只是我还没学到)
一般来说,输入矩阵一般是行向量(至少在这本书里是这样);自变量一般都全部需要放到一起,也就是叠罗汉叠在一起嘛(就比如把三个1×20的行向量叠成3×20的矩阵)。p=[sqrs;sqjdcs;sqglmj];里面打这个;相当于就是换行到下一行的意思了哈(在我心里是这样的)。
同理,目标矩阵也是一样的做法。把二个1×20的行向量叠成2×20的矩阵
1.3.2 归一化
老实说,好久没看深度学习里面的基础内容,现在第一眼看到归一化我真忘了咋操作的了。。这就赶紧复习一下什么是归一化,顺便做几个小实验。
归一化定义:把一系列数据压到【0,1】或者【-1,1】
归一化的好处:消除量纲的影响,同时消除奇异样本的影响,方便计算!(奇异样本就是一些很有个性的数据,它比大家大很多或者又小很多)
啥时候用归一化?:在网上查找资料后得到,一般存在奇异样本的时候,就需要归一化,否则可以不需要(奇异数据可能导致模型一直无法拟合)
matlab如何归一化?在题中,使用了mapminmax函数解决的
使用mapminmax函数进行归一化,把数据压至【-1,1】
正好来做个实验吧,就以本题为例了。
mapminmax介绍:对矩阵每一行进行归一化
mapminmax调用格式:[pn,input_str]=mapminmax(p);,这只是其中一种调用格式,也是本题的调用格式,其他调用格式也懒得写了,到时直接百度即可。其中p是输入的矩阵,pn是归一化后的矩阵,input_str包含了一大堆数据中的信息(包括最大值最小值那些),一时半会我也讲不清楚,就做实验的时候截个图看看就懂了。
实验:对本题中的人数数据(行向量)进行归一化
sqrs=[20.55,22.44,25.37,27.13,29.45,30.10,30.96,34.06,36.42,38.09,39.13,39.99...
41.93,44.59,47.30,52.89,55.73,56.76,59.17,60.63];%人数
[pn,input_str]=mapminmax(sqrs);
归一化后结果:
从数据中我们可以看出,20.55和60.63分别是最小和最大的数据,他们充当了【-1,1】里面排头兵的作用。
那我们再看看input_str:
包含了很多有趣的信息
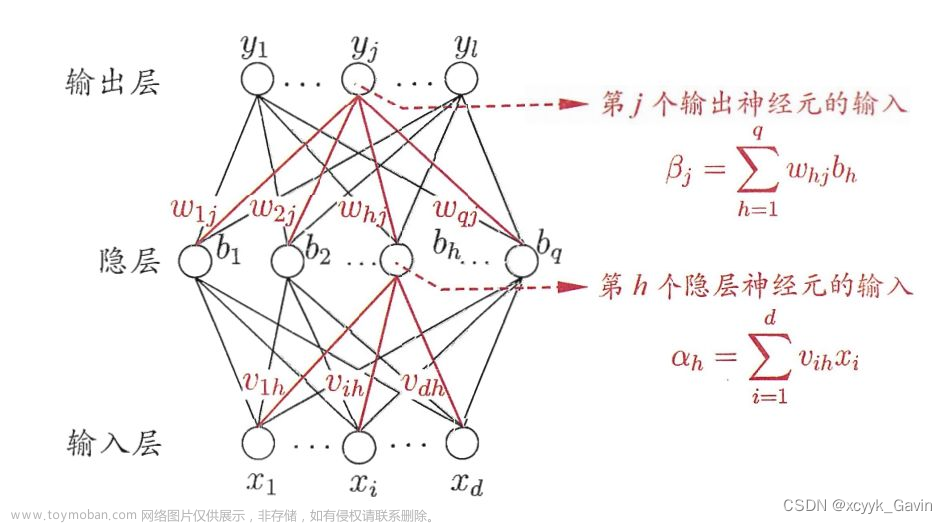
1.3.3 构建BP神经网络
这里差不多是算整个代码里的重头戏了,里面也有很多细节和问题。
%建立BP神经网络
net=newff(pn,tn,[3 7 2],{'purelin','logsig','purelin'});
net.trainParam.show=10;%每十次显示一次结果
net.trainParam.lr=0.05;%设置学习率
net.trainParam.epochs=5000;%最大训练次数为5000
net.trainParam.goal=0.65*10^(-3);%目标误差
net.divideFcn=''; %所有样本用以训练
net=train(net,pn,tn);%开始训练
%仿真
an=sim(net,pn);%使用训练好的网络进行仿真
a=mapminmax('reverse',an,output_str);%对数据反归一化,恢复原貌
其实一行一行看,也没啥问题,关键是,这些数值为啥要设成这样?只有慢慢分析了
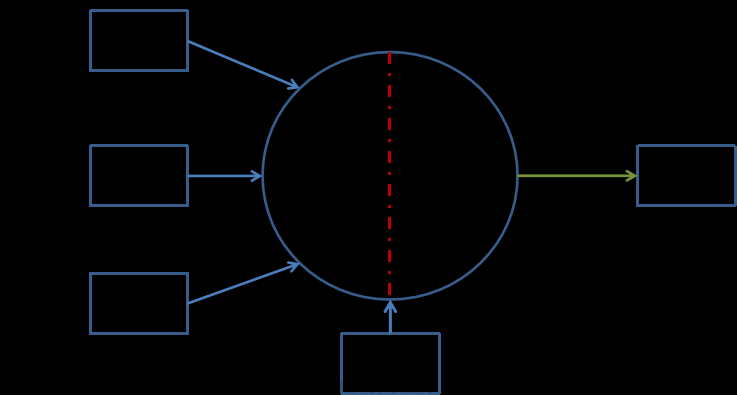
首先,newff()用来搭建BP神经网络函数。这里的pn指的输入数据,相当于深度学习里的样本(具体名字我搞忘了,西瓜书里有写);tn是输出数据,相当于深度学习里的标签;net是构建出的网络,和python里是不是有异曲同工之妙?;【3,7,2】是隐藏层的层数和神经元个数,这里表示有三层,每层分别有3,7,2个神经元。后面这个{‘purelin’,‘logsig’,‘purelin’}表示的是每层隐藏层的激活函数,purelin是线性函数,logsig就是sigmoid函数。这里我们把图花一下,看看长啥样?:
purelin画图代码:
x=[-10:10];
y=purelin(x);
plot(x,y,'b-o')
title('线性激活函数图')

logsig画图代码:
x=[-10:10];
y=logsig(x);
plot(x,y,'r-o')
title('logsig激活函数图')

那么问题来了:隐藏层为什么是这么多层?每一层为什么是这么个数量的神经元?每一层用的激活函数为什么是这个?
其实我也不太清楚,但是在这道题中我大概能理解它为什么。(练多了就知道了)
net.trainParam是神经网络工具箱里用来设置训练参数的。后面的仿真相当于是测试集,还有反归一化也要弄懂。仿真的作用就是通过数据层面把网络的性能能力展示出来。
1.3.4 画图
这里画图画的是仿真的数据,以及真实数据的对比
具体内容没啥难度,熟练了就行。
其中有个语法提一下
newk=a(1,:);%网络输出客运量
newh=a(2,:);%网络输出货运量
这里的意思是分别取矩阵a第一行或者第二行的数据。如果是a(:,1),就是取矩阵a第一列的信息。
最后得到的对比图:
可以看出,实际数据和预测数据还是有一定偏差的。
1.3.5 使用网络进行预测
仿真是拿存在的数据进行的,而预测则是拿不存在的数据进行
%使用网络进行预测
pnew=[73.39,75.55
3.9635 4.0975
0.9880,1.0268];
pnewn=mapminmax('apply',pnew,input_str);%
anewn=sim(net,pnewn);
anew=mapminmax('reverse',anewn,output_str);
这里用到了mapminmax的另外一种调用格式。'apply’表示使用之前的参数input_str.
1.3.6 神经网络工具箱
程序运行完毕后还会弹出神经网络工具箱的界面:
这个参数具体含义改天来介绍吧 今天写累了
二、练习题——使用BP神经网络预测美国人口
2.1.问题简介
可以参考我上一篇博客
2.2实现代码
代码如下(示例):
clc;
close all;
clear all;
%数据
p=[1790:10:1980];
t=[301,320,352,371,390.5,412.8,432,400,358,364,380,430,438,447,...
444,450,547,667,818,981];
%归一化
[pn,input_str]=mapminmax(p);
[tn,output_str]=mapminmax(t);
%建立BP神经网络
net=newff(pn,tn,[1 3 1],{'purelin','logsig','purelin'});
net.trainParam.show=10;%每十次显示一次结果
net.trainParam.lr=0.01;%设置学习率
net.trainParam.epochs=5000;%最大训练次数为5000
net.trainParam.goal=0.65*10^(-3);%目标误差
net.divideFcn=''; %让程序继续运行
net=train(net,pn,tn);%开始训练
%仿真
an=sim(net,pn);%使用训练好的网络进行仿真
a=mapminmax('reverse',an,output_str);%对数据反归一化,恢复原貌
%画图
x=1790:10:1980;
figure(2);
subplot(2,1,1);
plot(x,a,'r-o',x,t,'b--+');
legend('拟合','实际 ');
xlabel('年');ylabel('人数');
title('对比图')
%预测
pnew=[1990 2000 2010 2020 2030];
pnewn=mapminmax('apply',pnew,input_str);%
anewn=sim(net,pnewn);
anew=mapminmax('reverse',anewn,output_str);
x=1990:10:2030;
subplot(2,1,2);
plot(x,anew,'r-o');
xlabel('年');ylabel('人数');
实现结果如图:文章来源:https://www.toymoban.com/news/detail-489312.html
 文章来源地址https://www.toymoban.com/news/detail-489312.html
文章来源地址https://www.toymoban.com/news/detail-489312.html
到了这里,关于【数学建模】matlab| BP神经网络入门学习的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!