本文作者系360奇舞团前端开发工程师
摘要:
本文介绍了如何结合 OpenAI Whisper、FFmpeg 和 TTS(Text-to-Speech)技术,以实现将视频翻译为其他语言并更换声音的过程。我们将探讨如何使用 OpenAI Whisper 进行语音识别和翻译,然后使用 FFmpeg 提取视频音轨和处理视频,最后使用 TTS 技术生成新的语音并替换原视频的音轨。通过这种方式,我们可以为视频添加新的语言版本,同时保持其原始视觉内容。
引言:
现如今,全球范围内的视频内容正在迅速增长,跨语言传播和多语言支持成为了一个重要的需求。但是,手动为视频添加不同语言的字幕或配音可能非常耗时且昂贵。本文将介绍一种利用 OpenAI Whisper、FFmpeg 和 TTS 技术的方法,使我们能够将视频翻译为其他语言并更换声音,以满足多语言需求,同时降低成本和时间。
OpenAI Whisper:是一种强大的语音识别模型,能够将语音转换为文本,并支持多种语言。我们将使用 Whisper 将视频中的原始语音提取为文本,并通过翻译服务将其转换为目标语言的文本。
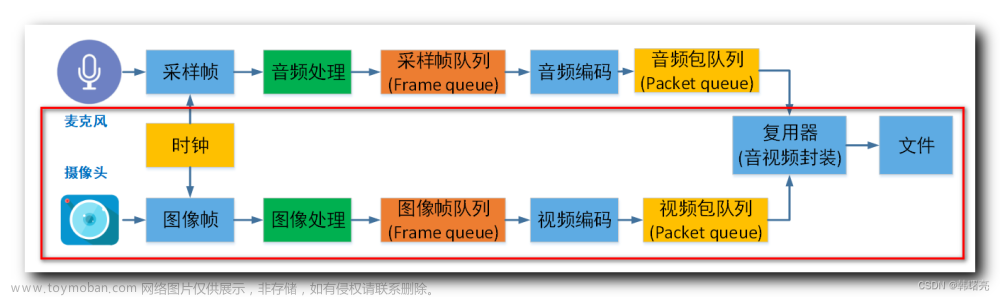
FFmpeg:处理视频和音轨提取接下来,我们使用 FFmpeg 工具处理视频和提取音轨。FFmpeg 是一款功能强大的多媒体处理工具,它支持各种音视频处理操作。我们可以使用 FFmpeg 提取原视频的音轨,以便稍后替换为新生成的语音。
TTS 技术:生成新的语音为了替换原视频的音轨,我们需要生成新的语音。这里我们使用 TTS(Text-to-Speech)技术,将先前翻译得到的目标语言文本转换为对应语言的语音。TTS 技术基于深度学习模型,可以生成自然流畅的语音,使其与原视频的内容相匹配。
结合 Whisper、FFmpeg 和 TTS:实现视频翻译和更换声音最后,我们将 Whisper 生成的目标语言文本与 TTS 生成的新语音结合起来,并使用 FFmpeg 将新语音替换到原视频的音轨中。通过使用 FFmpeg 的音轨替换功能,我们可以确保新语音与视频内容同步,并生成具备目标。
结果展示
原视频:https://caining0.github.io/statichtml.github.io/test.mp4
转换后视频:https://caining0.github.io/statichtml.github.io/output.mp4
前提与依赖
pip3 install openai-whisper
pip3 install ffmpeg-python
brew install ffmpeg
pip3 install TTS//https://github.com/coqui-ai/TTSopenai-whisper用法
命令行用法
以下命令将使用medium模型转录音频文件中的语音:
whisper audio.flac audio.mp3 audio.wav --model medium默认设置(选择模型small)适用于转录英语。要转录包含非英语语音的音频文件,您可以使用以下选项指定语言--language:
whisper japanese.wav --language Japanese添加--task translate会将语音翻译成英文:
whisper japanese.wav --language Japanese --task translate运行以下命令以查看所有可用选项:
whisper --helpPython 用法
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])例子
whisper test.mp4 --language Chinese --task translate[00:00.000 --> 00:03.400] If the Chinese people come to design a new building, it will be like this
[00:03.400 --> 00:06.360] A new building that has been rebuilt by a Chinese city
[00:06.360 --> 00:09.480] This is a real city, maybe it's your hometown
[00:09.480 --> 00:12.640] Let's take a short film with us and show its real face
[00:12.640 --> 00:14.480] The opening is a one-minute long lens
[00:14.480 --> 00:16.520] First, the time has changed, the new season has no shadow
[00:16.520 --> 00:18.680] A sense of depression is born
[00:18.680 --> 00:20.400] We randomly saw the red tail of it
[00:20.400 --> 00:22.120] This is the new building in the hundreds of square kilometers
[00:22.120 --> 00:24.480] The blue protective tent inside the blue sky city in the front
[00:24.480 --> 00:26.080] As in the front of the crystal ball
[00:26.080 --> 00:28.360] The back is a larger environmental structure
[00:28.360 --> 00:29.800] This is the shadow of the new building
[00:29.800 --> 00:30.600] The lens is far away
[00:30.600 --> 00:32.040] We see that there is a bandage
[00:32.040 --> 00:33.560] It is passing through a huge star
[00:33.560 --> 00:35.240] Those are the stars of the stars
[00:35.240 --> 00:37.280] The stars do not affect the shape of the bandage
[00:37.280 --> 00:39.240] This means that their motivation is super
[00:39.240 --> 00:42.040] At this time, the lens enters the blue protective tent inside the first crystal ballTTS
from TTS.api import TTS
model_name = TTS.list_models()[0]
tts = TTS(model_name)
tts.tts_to_file(text="Hello world!", speaker=tts.speakers[0], language=tts.languages[0], file_path="output.wav")
#实践中需要把text更换为whisper提取内容ffmpeg
提取无音频视频
ffmpeg -i /Users/cnn/Downloads/test.mp4 -an -y output_new.mp4去噪
ffmpeg -y -i output_new.wav -af "anlmdn=ns=20" output_clean.wav合并与剪切
ffmpeg -i merge1.wav -i a_p1.wav -filter_complex "[0:0] [1:0] concat=n=2:v=0:a=1 [a]" -map [a] -y merge0.wav其他问题,由于tts生成语音,实际时长与原视频时长不一样,需要动态调整
# 思路为,获取视频时长和原视频时间的比例,并设置,调整语速
ffmpeg -y -i output.wav -filter:a "atempo=0.8" output_new.wav前景
结合 OpenAI Whisper、FFmpeg 和 TTS 技术的跨语言视频翻译与语音本地化应用具有广阔的前景与市场潜力。随着全球化的推进,多语言视频内容需求日益增加,教育、媒体、娱乐和商务等领域都需要提供多语言支持。这种应用可以帮助内容创作者快速将视频本地化,满足全球受众的需求,同时降低成本和时间投入。在教育领域,多语言支持可以促进全球学习交流与合作;媒体和娱乐行业可以通过本地化的视频内容吸引更广泛的受众市场。此外,企业在跨国业务和跨文化交流中也可以利用这种应用进行语音本地化,促进全球团队合作和商务沟通。未来,这种应用有望成为视频内容创作工具与服务的一部分,提供高效、自动化的跨语言翻译和语音本地化功能。总之,这种应用在满足多语言视频需求的同时,为各个行业带来商业机会,并推动全球化交流与合作的发展。
不足
TTS略有杂音,后续优化,或者考虑收费版本,如Polly:https://aws.amazon.com/cn/polly/,
引用
https://github.com/openai/whisper
https://github.com/coqui-ai/TTS
https://ffmpeg.org/
- END -文章来源:https://www.toymoban.com/news/detail-489350.html
关于奇舞团
奇舞团是 360 集团最大的大前端团队,代表集团参与 W3C 和 ECMA 会员(TC39)工作。奇舞团非常重视人才培养,有工程师、讲师、翻译官、业务接口人、团队 Leader 等多种发展方向供员工选择,并辅以提供相应的技术力、专业力、通用力、领导力等培训课程。奇舞团以开放和求贤的心态欢迎各种优秀人才关注和加入奇舞团。
文章来源地址https://www.toymoban.com/news/detail-489350.html
到了这里,关于OpenAI Whisper + FFmpeg + TTS:动态实现跨语言视频音频翻译的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!