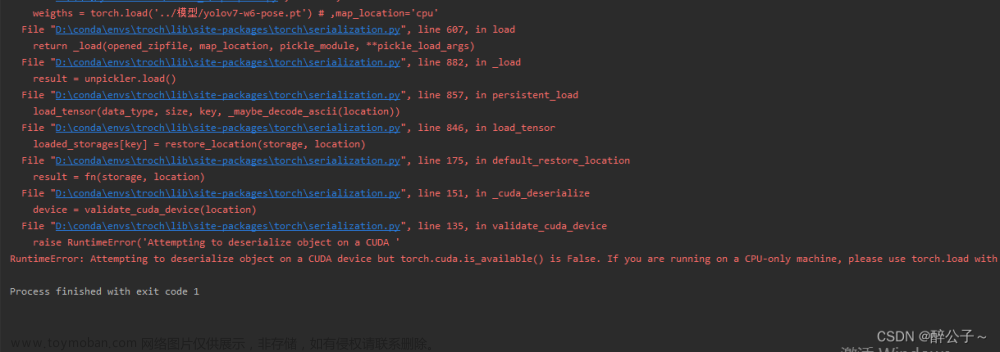
问题描述
已经安装CUDA与Pytorch。但执行如下Python脚本,输出结果为False:
import torch print(torch.cuda.is_available())出现这个问题的原因很多,很多文章的分析并不全面。博主遇到这个问题时,也是不断整合网络上零零散散的信息,浪费了不少功夫,因此写下了本文。如果你也遇到了这个问题,本文致力于帮助你通过这一篇文章解决这一问题。如果本篇文章对你有帮助,希望能点赞鼓励一下。
注意,本文解决的问题是,import torch不报错,但Pytorch与cuda没有正确匹配上。如果你的import torch报错,说明你没有正确安装Pytorch,请参考这一链接,安装合适的Pytorch版本。
为了方便说明,本文以CUDA 10.2与PyTorch 1.11.0(GPU版本)为例。
总览:导致问题的原因
导致这一问题的原因主要分为如下四个方面,在这里先作总结,具体方法在之后展开。有经验的同学可以直接根据本节进行快速排查,以提高效率。
- CUDA版本与驱动程序不兼容:CUDA版本需与GPU驱动程序兼容。
- CUDA库的路径设置存在问题:如果CUDA库路径未正确配置,PyTorch将无法找到CUDA库文件。
- PyTorch版本与CUDA版本不匹配:安装的PyTorch版本需与CUDA版本匹配。
- 编译问题:如果使用预编译的PyTorch二进制文件,可能存在与CUDA版本不匹配的问题。
- 冲突:可能存在其他软件包或库与PyTorch或CUDA发生冲突。
绝大多数的问题都可以通过前三步解决。
请按照1-5的顺序排查,直至问题解决。
可能1:CUDA版本与驱动程序不兼容
驱动程序与CUDA的兼容,指的是GPU驱动程序与安装的CUDA版本相匹配,并且能够正确地与CUDA库进行通信和协作。可以按照如下步骤排查二者是否兼容:
1. 查看CUDA版本。
在终端输入如下指令:

或者:
cat /usr/local/cuda/version.txt

例如,我的CUDA版本是10.2。
2. 查看GPU驱动程序版本。
在终端输入如下指令:
nvidia-smi

找到第一行的Driver Version,例如我的是440.44。
3. 检查二者是否兼容。
驱动程序与CUDA的兼容性是非常重要的,因为PyTorch和其他基于CUDA的库需要与GPU驱动程序进行交互才能正确运行。如果驱动程序与CUDA不兼容,可能会导致无法正常使用CUDA功能或出现错误。
检查上述二者的版本,确保二者是匹配的。例如,CUDA 10.2对应的推荐驱动程序版本为NVIDIA驱动程序版本440.33或更高版本,我的版本是440.44,因此兼容。
CUDA版本与GPU驱动的兼容性表格(Linux请参照第一二列,Windows请参照第一三列)如下,请根据自己的版本自行比对:
注:引用自此链接。
4. 更新驱动程序或更改CUDA版本。
若二者不匹配,可以选择更新驱动程序或更改CUDA版本。
可以通过访问NVIDIA官方网站下载并安装适当的驱动程序版本。在安装新的驱动程序之前,请确保先卸载旧的驱动程序,并按照安装指南进行正确的安装,这里不做展开。如对CUDA版本无特殊要求,建议优先选择更改安装的CUDA版本。
可能2:CUDA库的路径设置存在问题
简单来说,如果CUDA库路径未正确配置,PyTorch将无法找到CUDA库文件。在这种情况下,即便CUDA与Pytorch的安装都是正确的,也会导致错误。
请按照如下步骤,将CUDA路径添加到Linux系统的环境变量中(Windows平台下的操作与之类似,这里以Linux为例,供参考):
- 在终端输入如下指令:
vim ~/.bashrc
即使用vim文本编辑器打开~/.bashrc文件。也可以选择通过其他的文本编辑器打开。
- 以vim为例,按下字母i,进入编辑模式,在文件的末尾添加以下行:
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
其中,/usr/local/cuda为CUDA的安装路径。如果你的CUDA的安装路径不是/usr/local/cuda,请填你的实际路径。
该操作会将CUDA的bin目录添加到PATH环境变量中,以便系统可以找到CUDA可执行文件,同时将CUDA的lib64目录添加到LD_LIBRARY_PATH环境变量中,以便系统可以找到CUDA库文件。
- 按下ESC,然后输入:wq,之后按下回车,保存~/.bashrc文件。
- 在终端窗口中,运行以下命令以使环境变量更改生效:
source ~/.bashrc
该命令会重新加载.bashrc文件,使添加的环境变量生效。
- 检查CUDA路径是否成功添加到环境变量中。
在终端窗口中,运行以下命令:
echo $PATH
echo $LD_LIBRARY_PATH
上述命令将显示环境变量的当前值。检查输出中是否包含CUDA的路径(/usr/local/cuda/bin和/usr/local/cuda/lib64),以确保添加成功。
如果输出中不包含CUDA的路径,或包含多个CUDA路径,请继续参考如下步骤操作。
- 排查环境变量问题。
如果环境变量的当前值不正确,那么这个问题可能是由其他配置文件或环境变量引起的。除了~/.bashrc文件之外,还可能存在其他配置文件,这些文件也可能包含CUDA库路径的设置。打开这些文件并查找类似PATH、LD_LIBRARY_PATH的设置行,以确定是否在其他文件中设置了/usr/local/cuda路径。
- 检查其他环境变量。
除了LD_LIBRARY_PATH环境变量之外,还可能存在其他与CUDA相关的环境变量设置,这些设置可能导致/usr/local/cuda/lib64路径被添加到LD_LIBRARY_PATH中。运行如下指令检查是否存在其他环境变量与CUDA相关:
env | grep CUDA
如果有的话,可能是由于执行过其他的CUDA相关的操作引起的,可以参照下一条将其清除。
- 清除旧的环境变量。
如果曾经安装过其他版本的CUDA或执行过其他与CUDA相关的操作,旧的环境变量设置可能仍然存在于系统中。可以手动清除这些环境变量,然后重新设置正确的CUDA库路径。
首先,运行如下指令:
env
这将列出所有当前的环境变量。在输出中查找与CUDA或旧版本相关的环境变量设置,使用unset命令来删除指定的环境变量。例如,假设存在名为OLD_CUDA_PATH的环境变量,可以运行以下命令删除它:
unset OLD_CUDA_PATH
对每个需要删除的环境变量重复此步骤。注意,除非确定环境变量存在问题,否则不要轻易删除环境变量。
- 重新加载配置文件。
运行指令:
source ~/.bashrc
注意,如果此时报错:/bin/lesspipe: 1: /bin/lesspipe: basename: not found,可能是由于删除了PATH环境变量,请参考此链接。
- 再次检查环境变量。
运行env命令再次检查环境变量,确保旧的环境变量已成功删除。
可能3:PyTorch版本与CUDA版本不匹配
有些同学可能直接通过下面的指令安装Pytorch:
pip install pytorch
conda install pytorch
这些指令都是不合适的,可能导致安装的PyTorch版本与CUDA版本不匹配。也有些同学访问Pytorch官网,看到安装指令之后直接复制粘贴,而没有进一步检查Pytorch与CUDA的匹配性。

更加推荐的安装方式是,访问Previous PyTorch Versions | PyTorch,找到与CUDA版本相符的Pytorch版本,再复制安装。

可能4:编译问题
我没有遇到过这种情况,我也不推荐使用源代码编译PyTorch。如果排查到这一步依旧没有解决问题,建议首先更换Pytorch版本尝试(例如由conda安装改为pip安装)。如果依旧无法解决,再参照使用源代码编译PyTorch的相关文章。
可能5:软件包或库冲突
为了避免这种情况,建议新建一个conda环境,在新的conda环境下安装Pytorch。
写在最后
上面五点是博主根据个人经验与网上的相关文章总结的,如果有补充,欢迎同学们在评论区讨论。文章来源:https://www.toymoban.com/news/detail-489859.html
如果这篇文章帮助到了你,希望能点赞或评论支持一下,大家的鼓励是我持续创作的最大动力。文章来源地址https://www.toymoban.com/news/detail-489859.html
到了这里,关于【一文解决】已安装CUDA与Pytorch但torch.cuda.is_available()为False的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!