文生图
1. 正反向Prompt
使用文字Prompt,正向和反向词的添加来生成图片,通过对应参数调节和添加更多的Prompt来让AI更清晰的感知我们想要的场景图片、添加更多的Prompt之间使用英文,分隔。 提示词使用英文,完全不需要语法

这里有个通用的正反向咒语,在生成图片时可以使用的到,为了使我们生成的土图片更加的生动,人物场景更加的清晰,更符合我们描述的样子
参考
- 正向
(masterpiece:1,2),best quality,masterpiece,highres,original,extremely detailed wallpaper,perfect lighting,(extremely detremely detailed CG:1.2),drawing,paintbrush,
- 反向
NSFW,(worst quality:2),(low quality:2),(normal quality:2),lowres,normal quality,((monochrome)),((grayscale)),skin spots,acnes,skin blemishes,age spot,(ugly:1.331),(duplicate:1.331),(morbid:1.21),(mutilated:1.21),(tranny:1.331),mutated hands,(poorly drawn hands:1.5),blurry,(bad anatomy:1.21),(bad proportions:1.331),extra limbs,(disfigured:1.331),(missing arms:1.331),(extra legs:1.331),(fused fingers:1.61051),(too many dingers:1.61051),(unclear eyes:1.331),lowers,bad hands,missing fingers,extra digit,bad hands,missing fingers,(((extra arms and legs)))
这里有几个网站比较不错,我直接帖在下面
- openart.ai 进入网站主页点discovery里面有对应图片生成时的Prompt和参数,很多基于SD官方模型和欧美主流模型生成的作品
- arthub.ai 记录了更多的二次元和亚洲审美的内容网站,里面具体都类似
- ai.dawnmark.cn 这个是对于自己想要的Prompt词的傻瓜操作的网站,直接点击,在上面复制下来就是对应的。
生成Prompt词对应的步骤
- 人物及主体特征(服饰穿搭,发饰发色,五官,面部,肢体动作)
- 场景特征(室内、室外,大场景 city、street,小细节)
- 内容型的提示词(画质,best quality, ultra detailed, masterpiece, hires, 8k, extremely detailed CG unity 8k wallpaper, 画风 比如二次元 anime, game cg,插画 painting,illustration,偏真实系画风 Photorealistic,realistic 更依赖真实系训练的模型))
Prompt关键词对应
如果想突出什么东西 就可以在Prompt关键词加上 () 每加一层括号对应权重就 × 1.1倍
- 括号加数字
(white flower:1.5), 权重为之前的1.5倍(增强)
(white flower:0.8), 权重为之前的0.8倍(减弱) - 套括号
圆括号 (((white flower))), 每一层额外×1.1倍
大括号 {{{white flower}}}, 每套一层额外×1.05倍
方括号 [[[white flower]]], 每套一层额外×0.9倍
避免个别词条Prompt权重过高过低,最好控制在 1±0.5左右,过高容易扭曲画面,推荐增加更多的词条来画作
提示词的权重分配

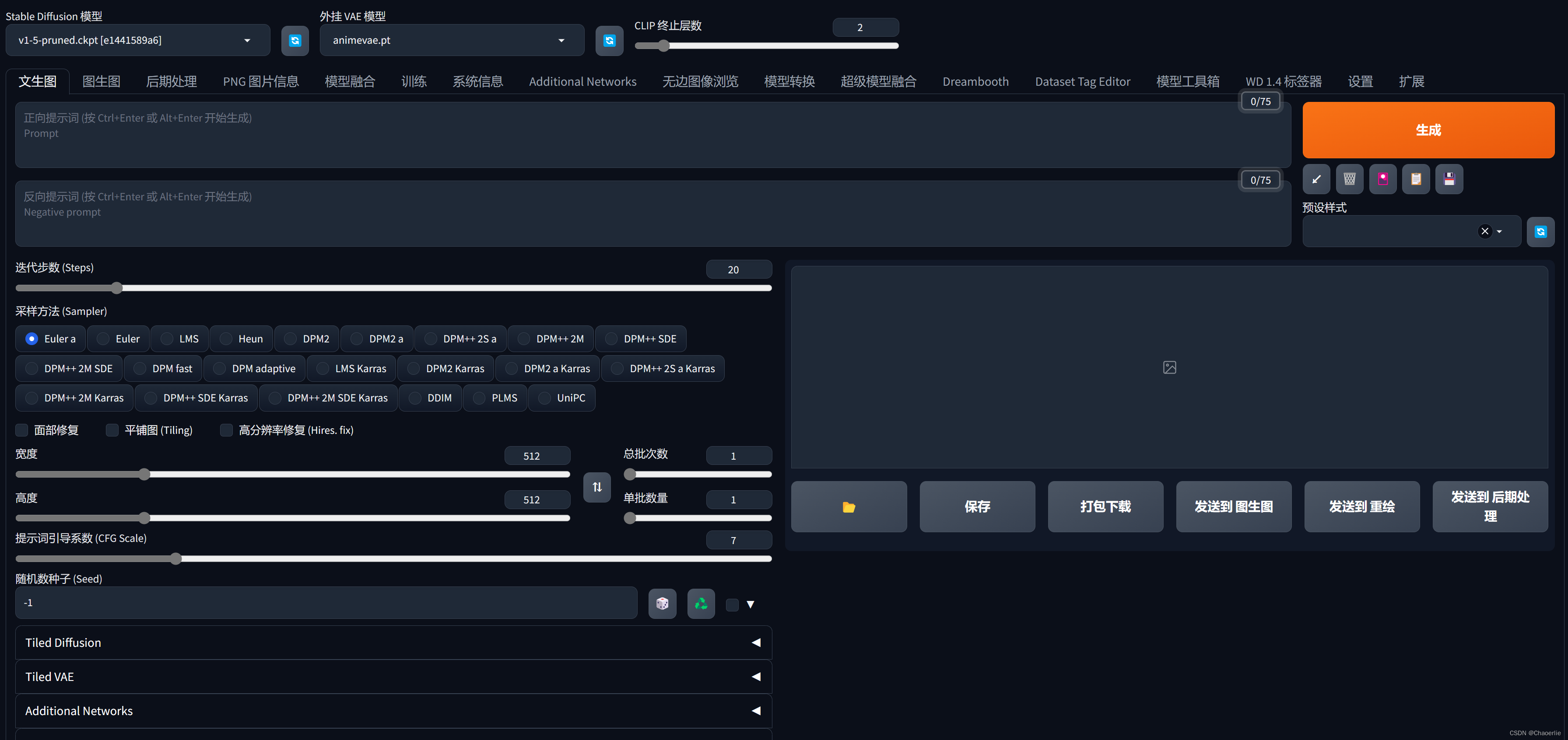
2. 迭代步数
AI生成图像步骤类似一个加噪去噪的过程,先将原图片进行加噪扩散使图片模糊,通过模型和对应Prompt关键词进行逆过程去噪,每迭代一次,图片就会变得更清晰,迭代的次数越多,花费的时间就越久。。
推荐的迭代步数值一般设置在20,如果算力充足也最求更好可以在30-40,最少不能低于10
3. 采样方法
AI生成图像使用的某种特定的算法
模型不同有差异,只是推荐使用,并非绝对的,推荐使用带有+号的
- 适合插画风格 Euler, Euler a
- 出图快 DPM 2M,2M Karras
- 细节丰富 SDE Karras
3.1 宽度高度 最后出图的分辨率
默认的是 512×512 即使出图效果很好,画面很更富也会感觉很模糊 可以提到1024×1024 设置太大的宽高出图会有问题,而且设备的显存等遭不住啊。。。。。。。
一般使用小的宽高比生成图片,在使用高清修复来放大,使用的原理是图生图
3.2 面部修复
一般都会勾选上,AI出图会使用特定的对抗算法对人物的面部进行修复,相当于美图P图软件的修脸文章来源:https://www.toymoban.com/news/detail-489898.html
3.3 生成批次,每批数量
- 生成批次 ===> 使用相同参数让AI批量的生成多张图片,在生成完成对应数量之后,会生成一张全部批次对应的合集,方便对比
- 每批数量 =====> 不推荐修改
如果觉得提示词Prompt不好写,不妨去搜搜对应提示词的插件,或者对应提示词的可视化网站文章来源地址https://www.toymoban.com/news/detail-489898.html
到了这里,关于AIGC:如何使用Stable Diffusion生图的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!