微信公众号“dotNET跨平台”中的文章《OpenAI的离线音频转文本模型Whisper的.NET封装项目》介绍了基于.net封装的开源语音辨识Whisper神经网络项目Whisper.net,其GitHub地址见参考文献2。本文基于Whisper.net帮助文档中的示例,测试Whisper.net的基本用法。
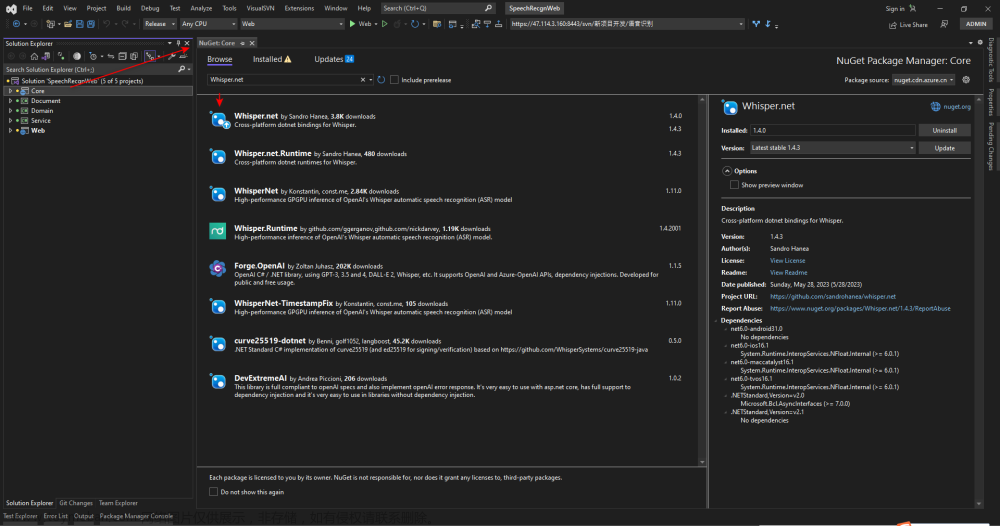
创建基于.net6的Winform项目,然后在NuGet包管理器中搜索并安装Whisper.net包,如下图所示。注意,如果搜索Whisper,还会搜到一个名为WhisperNet的包,这个包跟Whisper.net的用法不同,也不能通用,注意不要安装错了。

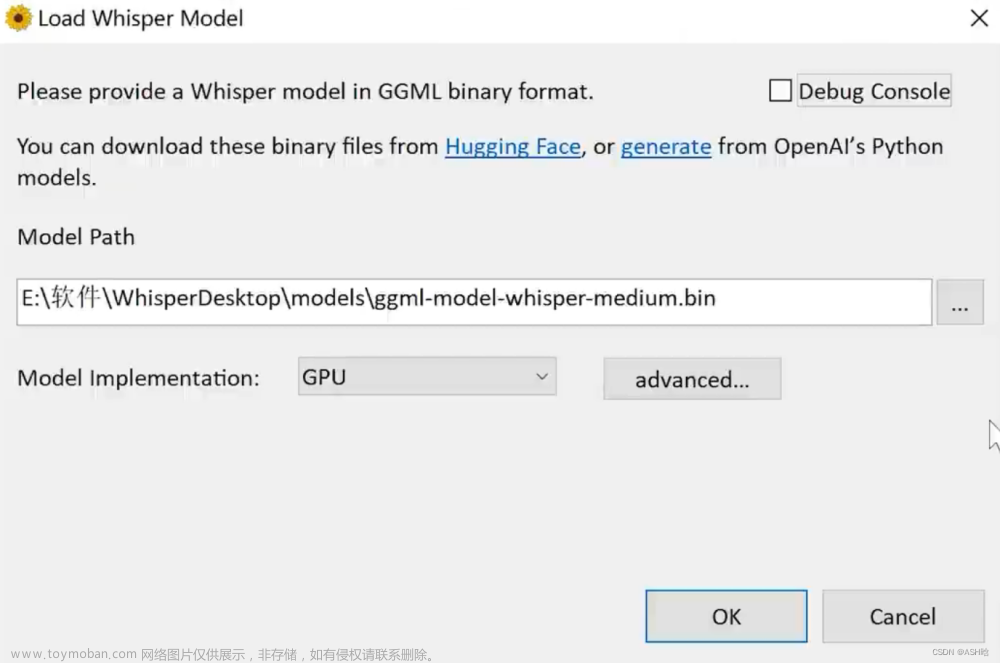
在测试程序之前,需要下载语言模型文件,可以从参考文献3中下载。根据参考文献1中的介绍,下载了ggml-large.bin、ggml-medium.bin、ggml-small.bin等3个支持中文的语言模型文件,并在测试程序中优先选用ggml-large.bin进行测试。
除了语言模型文件,Whisper.net对音频文件要求比较严格,必须是采样率为16KHz的wav格式的音频文件,具体的文件格式要求参见下面列出的Whisper.net包中WaveParser类中的部分格式检查代码。
byte[] array = new byte[36];
if (waveStream.Read(array, 0, 36) != 36)
{
throw new CorruptedWaveException("Invalid wave file, the size is too small.");
}
if (array[0] != 82 || array[1] != 73 || array[2] != 70 || array[3] != 70)
{
throw new CorruptedWaveException("Invalid wave file RIFF header.");
}
if (array[8] != 87 || array[9] != 65 || array[10] != 86 || array[11] != 69 || array[12] != 102 || array[13] != 109 || array[14] != 116 || array[15] != 32)
{
throw new CorruptedWaveException("Invalid wave file header.");
}
int num = BitConverter.ToInt32(array, 16);
if (num < 0)
{
throw new CorruptedWaveException("Invalid wave format size.");
}
if (BitConverter.ToUInt16(array, 20) != 1)
{
throw new CorruptedWaveException("Unsupported wave file");
}
channels = BitConverter.ToUInt16(array, 22);
sampleRate = BitConverter.ToUInt32(array, 24);
if (sampleRate != 16000)
{
throw new NotSupportedWaveException("Only 16KHz sample rate is supported.");
}
bitsPerSample = BitConverter.ToUInt16(array, 34);
if (bitsPerSample != 16)
{
throw new NotSupportedWaveException("Only 16 bits per sample is supported.");
}
本文采用两个音频文件进行测试,第一个是Whisper.net项目自带示例程序中的kennedy.wav文件,用于测试识别英文,另一个是在B站上下载古诗《春晓》的mp4视频文件(参考文献4),用于测试识别中文,通过参考文献5在线将其转换为指定采样率的wav文件,如下图所示。
测试程序的主要代码参考自Whisper.net项目中的示例程序Whisper.net.Tests中的代码。采用Whisper.net识别语音可以采用同步方式或异步方式,示例程序中都有相应的代码,本文采用同步方式的代码进行测试。主要代码如下所示:
try
{
txtResult.Text = String.Empty;
var segments = new List<SegmentData>();
var encoderBegins = new List<EncoderBeginData>();
using var factory = WhisperFactory.FromPath("ggml-large.bin");
using var processor = factory.CreateBuilder()
.WithLanguage("auto")
.WithEncoderBeginHandler((e) =>
{
encoderBegins.Add(e);
return true;
})
.WithSegmentEventHandler(segments.Add)
.Build();
using var fileReader = File.OpenRead(txtFilePath.Text);
processor.Process(fileReader);
foreach (var segment in segments)
{
txtResult.Text += "\r\n" + ($"New Segment: {segment.Start} ==> {segment.End} : {segment.Text}");
}
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
程序运行效果如下面的截图所示:

后续还会继续学习Whisper.net的用法。文章来源:https://www.toymoban.com/news/detail-490118.html
参考文献:
[1]https://it.sohu.com/a/670010700_121124363
[2]https://github.com/sandrohanea/whisper.net
[3]https://huggingface.co/ggerganov/whisper.cpp/tree/main
[4]https://www.bilibili.com/video/BV19W411k7Bo/?spm_id_from=333.337.search-card.all.click&vd_source=db4a1f65c18549c78df3e9d579e59e19
[5]https://www.aconvert.com/cn/audio/文章来源地址https://www.toymoban.com/news/detail-490118.html
到了这里,关于测试离线音频转文本模型Whisper.net的基本用法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!