作者:zizhan居士 来源:投稿
编辑:学姐
前段时间大火的工具Github Copilot想必大家都略有耳闻,我们只需要输入一些注释说明你需要的函数功能,AI就会自动帮你编写完整的函数代码,代码逻辑、规范甚至比自己写的都好,可谓是让人瑟瑟发抖的结对编程好兄弟。
而这个工具背后的大boss就是参数量让人瑟瑟发抖的GPT-3语言模型。本文不仅介绍大哥大GPT-3,还对他的同胞兄弟GPT-1, GPT-2也进行介绍,讲解他们之间的演化过程。强烈推荐李沐老师的b站讲解视频,本文内容与之强相关,算是李沐老师讲解视频的一个笔记。
首先,简要介绍下,孕育这三兄弟的机构是OpenAI。
GPT-1:Improving Language Understanding by Generative Pre-Training
GPT-2:Language Models are Unsupervised Multitask Learners
GPT-3:Language Models are Few-Shot Learners
GPT-1 (生于2018年)
在自然语言处理任务中,存在大量无标签的语料数据,而有标签的语料数据相对较少,因此基于有监督训练的模型性能的提升大大受限于数据集。为了解决这个问题,作者提出先在大量的无标签数据上训练一个语言模型,然后再在下游具体任务的有标签数据集上进行fine-tune。
利用无标签数据的难点
-
设计何种目标函数来学习文本表示。已有的各种目标函数和子任务的相关度比较高,没有说哪一种目标函数特别好。
-
如何有效地把语言模型学到的文本表示迁移到下游子任务上。因为NLP领域的各种任务差别比较大,没有一个统一有效的方式使得一种文本表示能够很好地迁移到各种子任务上。
算法关键
-
无监督训练的模型采用Transformer的decoder,目标函数采用标准的语言模型的目标函数,即通过前文预测下一个词。
这个目标函数其实是比BERT模型那种完形填空式的语言模型目标函数要难,因为预测未来要比预测中间难。这可能也是导致GPT在训练和效果上比BERT差一些的一个原因。反过来说,如果你的模型真能预测未来,那么要比BERT这种通过完形填空训练的模型的强大很多,这也是作者一直将GPT模型不断做大,诞生三兄弟的一个原因吧。 -
有监督fine-tune采用标准的分类目标函数。此外,作者发现在有监督训练时额外加上语言模型的目标函数更好,能够提高模型的泛化性和加速模型收敛。
输入形式
对于不同的下游任务,将数据转换成统一的形式送入预训练好的语言模型,再接一层线性层进行分类等。可以发现,在fine-tune时,仅需要对预训练的语言模型做很小的结构改变,即加一层线性层,即可方便地应用于下游各种任务。
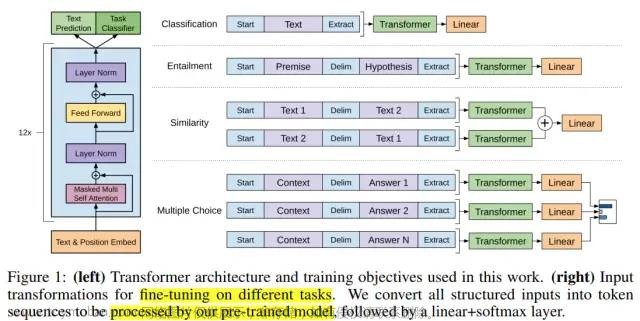
图1:在不同下游任务上输入数据的形式
GPT-2 (生于2019年)
GPT-2模型依旧使用Transformer模型的decoder,但相比于GPT-1,数据和模型参数变得更大,大约是之前的10倍,主打zero-shot任务。
现有基于监督学习训练的模型的泛化性不是很好,在一个任务上训练好的模型也很难迁移到下一个任务上。多任务学习(Multitask learning)是指在训练一个模型时,同时看多个任务的数据集,而且可能通过多个损失函数来达到一个模式在多个任务上都能用的效果,但是在NLP领域用的不多。NLP领域主流的做法还是像GPT-1或BERT那样先在大量无标签数据上预训练语言模型,然后在每个下游任务上进行有监督的fine-tune,但是这样也有两个问题:
-
对于下游的每个任务,还是要重新训练模型
-
需要收集有标签的数据
这样导致在拓展到新任务上时还是有一定的成本。因此,GPT-2提出利用语言模型做下游任务时,不需要下游任务的任何标注信息,即zero-shot设定,也不用训练模型。因此基本实现一劳永逸,训练一个模型,在多个任务上都能用。
此时,我们需要考虑一个问题,如图1所示,GPT-1在做下游任务时会对输入进行构造,引入了一些模型在预训练时没见过的符号(预训练时见到的是自然文本),比如Start、Delim、Extract,但因为有fine-tune的环节,所以模型会去认识这些符号。
然而,现在要做zero-shot,也就是在做下游任务时,模型不能被调整了,如果还引入一些模型之前没见过的符号的话,模型就会很困惑。因此,在构造下游任务的输入时,我们就不能引入模型未见过的符号,而要使得输入像模型预训练时见到的自然文本一样,比如:
机器翻译任务:translate to french, english text, french text。“translate to french”这三个词可以被认为是一个特殊的分隔符,后面叫Prompt。
阅读理解任务:answer the question, document, question, answer
下图所示为GPT-2在不同任务上进行预测时采用的Prompt:

图来自李宏毅老师机器学习课件
GPT-3 (生于2020年)
GPT-3结构和GPT-2一样,但是数据约为GPT-2的1000倍,模型参数约为GPT-2的100倍,暴力出奇迹,使得效果很惊艳。
GPT-3不再追求极致的zero-shot学习,即不给你任何样例去学习,而是利用少量样本去学习。因为人类也不是不看任何样例学习的,而是通过少量样例就能有效地举一反三。
由于GPT-3庞大的体量,在下游任务进行fine-tune的成本会很大。因此GPT-3作用到下游子任务时,不进行任何的梯度更新或fine-tune。
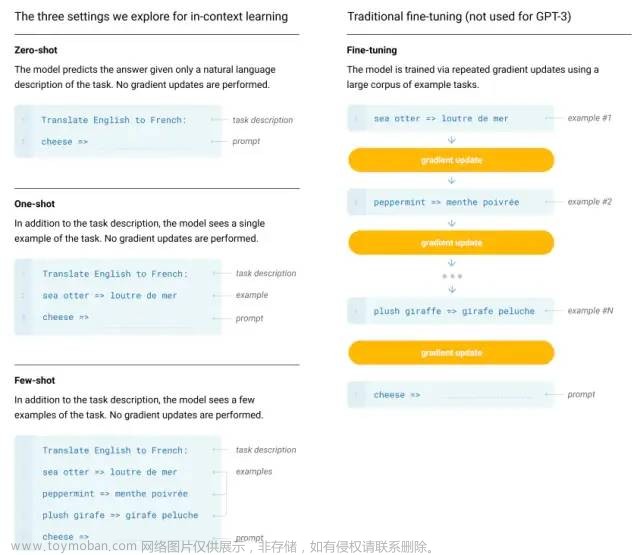
evaluate GPT-3
这里=>可以看成是一个Prompt。
GPT-3可以生成人类都很难分辨的新闻文章,瞎扯起来像模像样,比如:

news articles generated by GPT-3
局限性
-
虽然效果比GPT-2好很多,但是在文本生成上还是比较弱的。假如让GPT-3生成一个很长的文本,可能给了几段之后,就会重复起来
-
结构和算法的局限性。GPT-3是语言模型,不能像bert那样双向看。
-
均匀地预测下一个词。不能判断哪个词重要,哪个词不重要,导致语言模型可能会花很长时间去学习一些常见的虚词,不像人类学习的划重点。
-
样本有效性不够。基本上把整个网络上的文章下载下来了。
-
做few-shot时,模型真的是根据你给的样本从头学习的吗?这样碰到训练样本上没有出现的任务,也能够泛化过去;还是根据这些样本,从训练记忆里找出相关的,认出了这个任务,那拼的就是训练数据的大小了。
-
不具有可解释性
Improving Language Understanding by Generative Pre-Training Language Models are Unsupervised Multitask Learners Language Models are Few-Shot Learners https://www.bilibili.com/video/BV1AF411b7xQ文章来源:https://www.toymoban.com/news/detail-490525.html
点击卡片👇👇👇关注,600+篇ACL论文免费领文章来源地址https://www.toymoban.com/news/detail-490525.html
到了这里,关于Github Copilot编程工具背后的算法技术的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!