本次案例较为简单,符合人文社科、经济学管理学等专业本科生适用。
本文的数据来源于中国家庭金融调查(China Household Finance Survey,CHFS)是西南财经大学中国家庭金融调查与研究中心(下称中心)在全国范围内开展的抽样调查项目,由甘犁教授于2009年发起并领导,收集有关家庭金融微观层次的相关信息。
这个数据很大很杂,本文选取家庭人口,总消费,总收入,和负债四个变量作为解释变量,资产作为被解释变量,进行回归分析。
(这五个变量数据都是我自己清洗处理出来的,需要这代码演示数据的同学可以参考:数据)
案例背景:
家庭是社会部门中重要组成部分,掌握了大量财富资源,以我国为例,统计数据显示,我国个人持有的可投资资产总体规模已达到190万亿元。家庭资产配置情况,不仅事关家庭自身财富保值增值和抵御风险,也事关整个国家的经济、金融发展,逐渐成为研究热门领域。
一方面,家庭资产配置对于家庭财富累积和抵御风险具有重要意义。家庭资产配置的合理性与否,会影响到家庭收入的稳定性,诸如调查显示我国城市家庭资产配置较为单一和极端,此外研究也发现家庭资产配置相距理论研究的构成还有很大差距,主要表现为风险金融资产持有不足,这就是“有限参与”之谜。此外,随着经济增长增速的放缓,工资等劳动性收入放缓,而投资等财产性收入占比将上升,实现有效的资产配置有利于提升家庭财富累积水平。
另一方面,家庭资产配置对于金融市场发展具有重要影响。家庭资产是经济发展的重要资金来源,诸如家庭资产中形成的储蓄会形成社会投资的资金来源。实证研究表明,家庭资产配置的结构与金融发展水平呈现相互影响的关系。一方面,家庭资产配置会受限于金融发展水平,尤其是金融可获得性、金融市场发展等,丰富的金融产品有利于推动家庭资产配置的多元化;另一方面,家庭资产配置的结构也会影响到金融发展水平,如果家庭资产配置过于集中于存款等低风险资金,那么很难支持股市的发展,以美国为例,通过设立养老账户,积极配置公募基金参与到股市的发展,实现了美国股市的长期牛市。
不过,家庭资产配置与之前研究的保险公司等机构资产配置有较大差别,这主要在于机构资产配置具有很高的专业性,同时也会有部分监管要求的体现,从而实现科学合理的资产配置,而家庭资产配置很难做到如此理性投资决策,而且研究发现家庭资产配置具有很强的惯性,也就是资产配置结构具有显著的延续性,同时家庭资产配置一个是代际传承的目标,诸如部分父母是想要将部分财产留给子女,这也决定了家庭资产配置的复杂性和异质性。
研究目的与意义
通过本文研究,我们可以达到以下三点目的:
- 探究影响家庭资产变动的一些基本宏观微观的经济指标因素。
- 对比我国家庭资产配置和国外不一样的现象不同和原因。
- 对我国家庭资产和其可能的影响因素做出线性回归,分析我国家庭资产的影响因素
二、相关理论
(都是废话看看就行....代码在第三章)
(一)中外家庭资产配置的影响因素
首先需要了解的是什么因素影响着家庭资产配置,尤其是金融资产配置,其中的机制如何。明白了家庭资产配置的影响因素,也会为相关政策制定提供了一定参考。综合中外研究成果,影响家庭资产配置的因素较多,主要分为外部因素和内部因素,尤其是以内部因素为主,包括年龄、收入、健康、风险偏好、背景风险、性别、家庭人口数量、互联网、社会信任和互动、社会保障水平、教育、信贷约束、职业、城乡、幸福感等,可以确认的因素较多,这里主要谈一下年龄、性别、风险偏好、互联网、城乡差异、职业、家庭人口数量等因素的影响情况。
年龄方面,根据生命周期理论,不同生命阶段的收入和支出状况决定了在资产配置方面的差异,与传统的认为随着年龄增长风险金融资产配置比例下降的观点,现有实证研究认为,年龄与风险金融资产配置比例呈现倒U型关系,也就是风险资产配置比例随着年龄不断上升,会在某个年龄达到定点,一般认为50-60岁之间是配置风险金融资产的最高峰此后开始下降。不过,也有认为年龄与风险金融资产配置占比呈现双峰关系,也就是经历两个高峰阶段,而且第二个阶段的高度要高于第一个阶段。但是不管怎样,随着进入老龄化社会,为了应对养老消费,需要保持稳定的支出来源和流动性,对于风险金融资产的需求是持续下降的。
性别方面,家庭中掌握财务和资产配置的成员性别是会影响到资产配置构成的。这主要在于研究发现,女性在风险偏好方面要比男性更为稳健和保守。
风险偏好方面,风险偏好更多是一个各类因素作用于家庭资产配置的核心机制。风险偏好的形成既有先天因素,诸如性别、年龄、健康,也有后天因素,诸如收入、教育水平等。这些因素作用形成了各国家庭风险偏好的差异性,进而也会作用于家庭资产配置的结构。从国内实证研究看,家庭风险偏好与资产组合分散度呈现正相关关系,这也可以进一步解释我国家庭资产配置具有单一性,更多低风险偏好的家庭将资金投资于银行理财等少数资产,从而形成了较为集中的资产组合。
互联网方面,互联网的普及率在持续上升,提供了大量及时信息,有利于解决金融产品交易中的信息不对称问题。互联网的这种信息传递属性也有利于优化家庭的资产配置,主要是降低交易成本。不过互联网应用的影响在一定程度上是存在异质性,对于高学历、金融投资经验丰富的家庭具有更大的益处,而对于其他人群影响不大。
城乡差异方面,由于我国具有显著的二元经济体特征,城乡发展差距较大,这也会造成城乡家庭资产配置的差异性。实证研究也证实了这点,户主的户籍性质以及城乡家庭分布等都会造成彼此之间的资产配置差异,尤其是在风险金融资产方面,这种差异体现的更为显著。
家庭人口数量方面,针对这一因素部分论文也有所提及,不过实证结果的结论并不一致,一种解释是家庭成员较多,未来支付等不确定性增大,从而需要家庭预留更多安全资产,降低风险金融资产的配置;另一种解释认为,家庭成员多,收入来源增加,财务水平增大,有利于提升对于风险资产的配置力度。
(二)影响家庭资产的宏观因素
(1)经济周期
经济周期包括四个阶段:衰退、危机、复苏和繁荣。一般来说,在经济衰退期间,家庭资产的配置更倾向于持有货币。根据美林时钟的理论,在不同的经济周期,每种资产的性价比是不一样的,因此每个家庭可能会根据经济周期去动态的调整自己的资产组成。
(2)通货膨胀水平
通货膨胀是影响股市和股价的重要宏观经济因素。一般来说,货币供应量与股票价格成正比,即货币供应量的增加使股票价格上涨, 在通货膨胀阶段,钱是不值钱的,因此持有商品或金融资产是最明智的选择。
(3)利率变化
利率水平的变化对储蓄有非常大的影响,如果利率高的话,我国储蓄整体的水平就会明显提高。
(4)自然因素
正常情况下, 家庭资产主要是以增值和满足个人需求进行配置的。但如果发生了天灾人祸等不可抗拒的因素后,这些资产配置会有极大的变动。比如新冠疫情期间,更多的人就会选择买食物等生活物资。
(5)经济指标
根据政府相关部门发布的各种经济指标和景气政策信号,家庭资产配置者可以分析经济增长走势判断资产的类别。
三、实证研究
(一)研究设计
本文的数据来源于中国家庭金融调查(China Household Finance Survey,CHFS)是西南财经大学中国家庭金融调查与研究中心(下称中心)在全国范围内开展的抽样调查项目,由甘犁教授于2009年发起并领导,收集有关家庭金融微观层次的相关信息。
本文选取家庭人口,总消费,总收入,和负债四个变量作为解释变量,资产作为被解释变量,进行回归分析。变量名称和其英文简称如下表所示:
表1 变量说明
| familynum |
consump_total |
income_total |
debt |
asset |
| 家庭人口 |
总消费 |
总收入 |
负债 |
资产 |
(二)模型构建
本文采用的是多元线性回归模型,涉及多个自变量的多元线性回归方程,表示为:
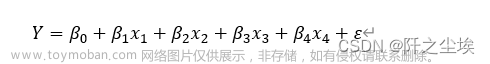
其中,Y是资产(asset),x1至x4代表为家庭人口(familynum)、总消费(consump_total)、总收入(income_total)、负债(debt)。ε代表是误差项的随机变量,β0代表截距,β1至β10代表每个变量的斜率。
(三)数据检验
描述性统计:
开始代码,导入包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号
sns.set_style("darkgrid",{"font.sans-serif":['KaiTi', 'Arial']})数据读取,展示前五行
data=pd.read_excel('data_clean.xlsx')
data.head()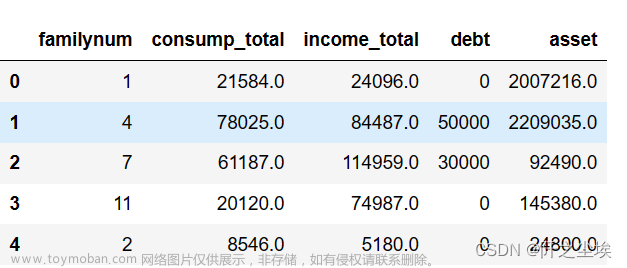
描述性统计
data.describe()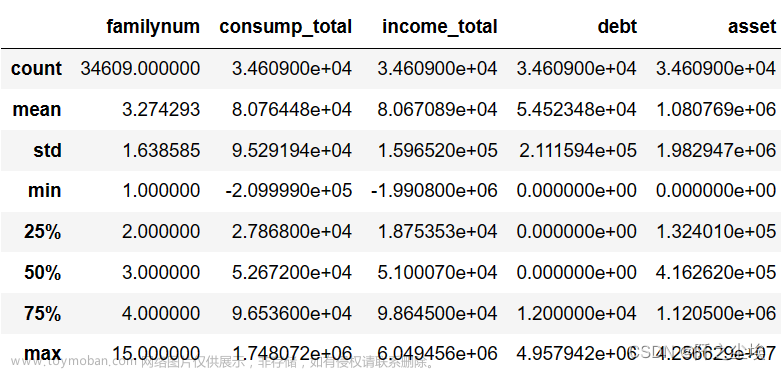
总共34609个观测量。表示不同家庭还有不同时间点上的家庭资产负债等变量的情况。可以看出,除了人口,其他这几组变量的方差都很大,说明几组数据波动性较大。分布较为分散。其中人口的平均值为3.27,说明绝大多数家庭都是三口之家,这和我国目前的国情也符合。进一步考察每个变量的箱线图和密度图如下:
先去掉极端值和异常值:
data=data[data['consump_total']<2e6]
data=data[data['income_total']<0.75e7]
data=data[data['income_total']>-0.25e7]
data=data[data['debt']<5e6]
data=data[data['asset']<5e7]画箱线图:
column = data.columns.tolist() # 列表头
fig = plt.figure(figsize=(7,4), dpi=128) # 指定绘图对象宽度和高度
for i in range(5):
plt.subplot(2,3, i + 1) # 2行3列子图
sns.boxplot(data=data[column[i]], orient="v",width=0.5) # 箱式图
plt.ylabel(column[i], fontsize=12)
plt.tight_layout()
plt.show()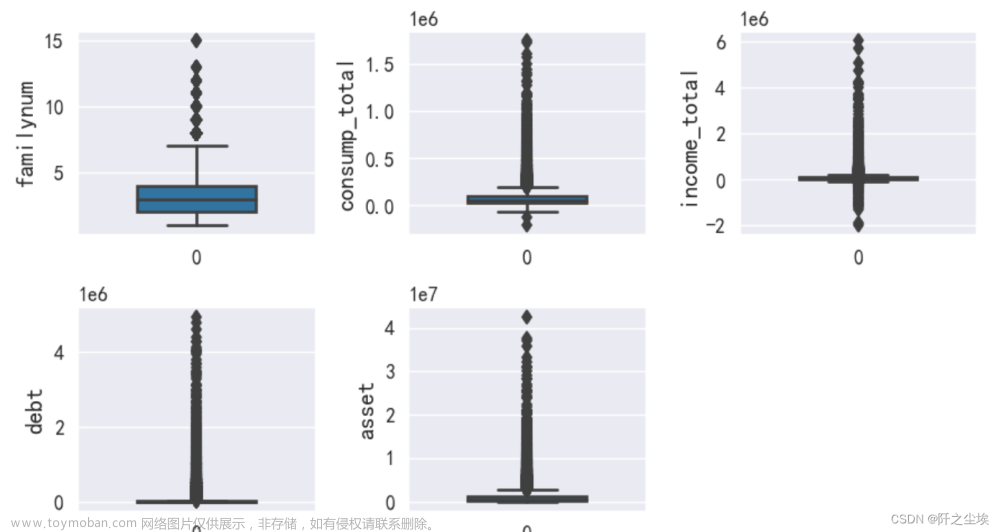
密度图:
fig = plt.figure(figsize=(7,4), dpi=128) # 指定绘图对象宽度和高度
for i in range(5):
plt.subplot(2,3, i + 1) # 2行3列子图
ax = sns.kdeplot(data=data[column[i]],color='blue',shade= True)
plt.ylabel(column[i], fontsize=12)
plt.tight_layout()
plt.show()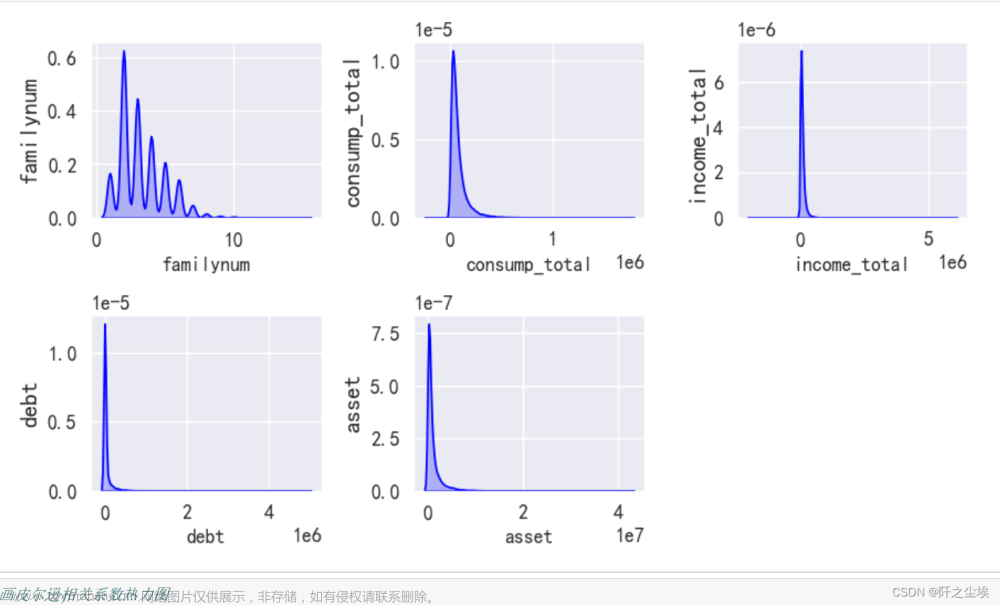
#画皮尔逊相关系数热力图
corr = plt.subplots(figsize = (4,4),dpi=128)
corr= sns.heatmap(data[column].corr(),annot=True,square=True) 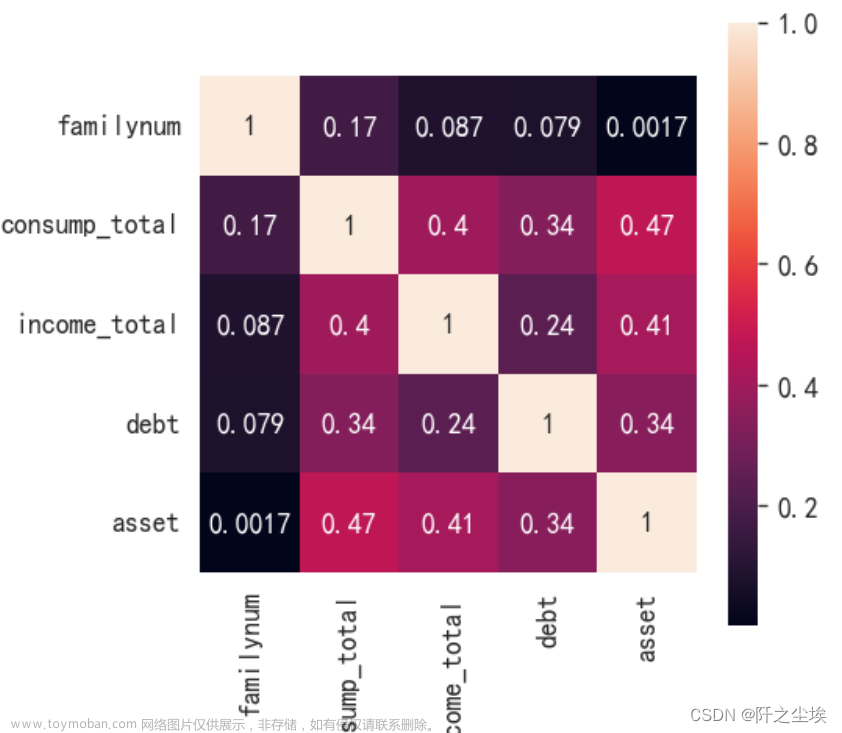
从相关系数表中可以得知,与资产相关系数最大的是消费,为0.4733。其次为收入,再就是负债和人口数量。解释变量之间的相关系数都不算高,因此该模型应该不会出现多重共线性的问题。下面进行回归分析。
回归分析
导入包,写出回归方程式
import statsmodels.formula.api as smf
import statsmodels.api as sm
all_columns = "+".join(data.columns[:-1])
print('x is :'+all_columns)
formula = 'asset~' + all_columns
print('The regression equation is :'+formula)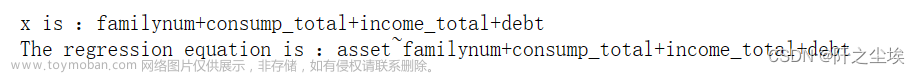
进行拟合:
results = smf.ols(formula, data=data).fit()
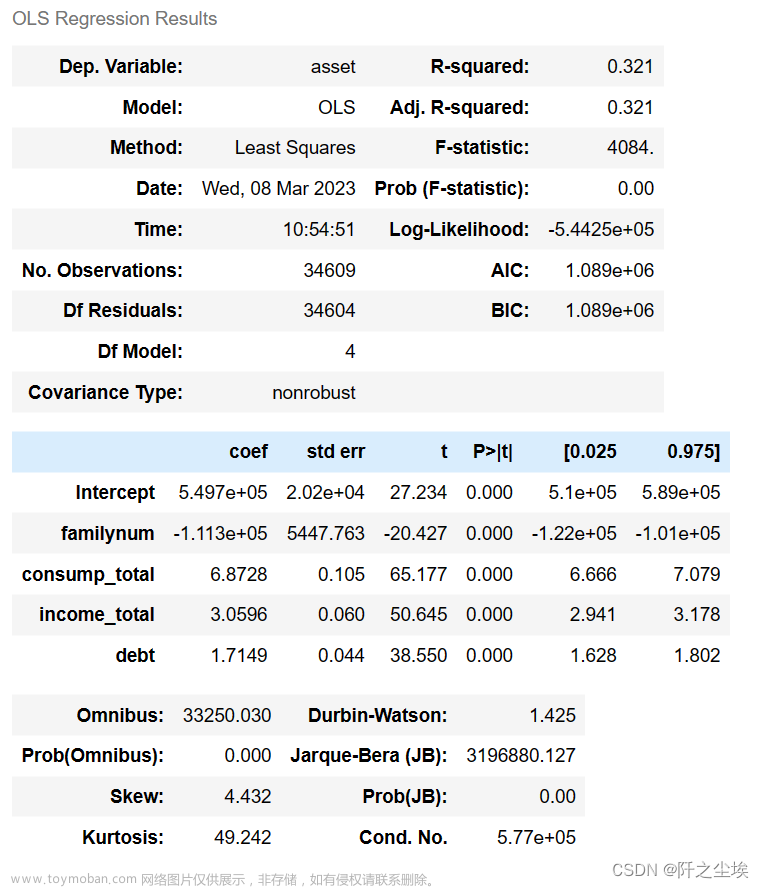
results.summary()将四组自变量对因变量资产做多元线性回归,得到的结果如下:
上面的展示结果类似于Eviews,或者这样打印出来好看一些:
print(results.summary())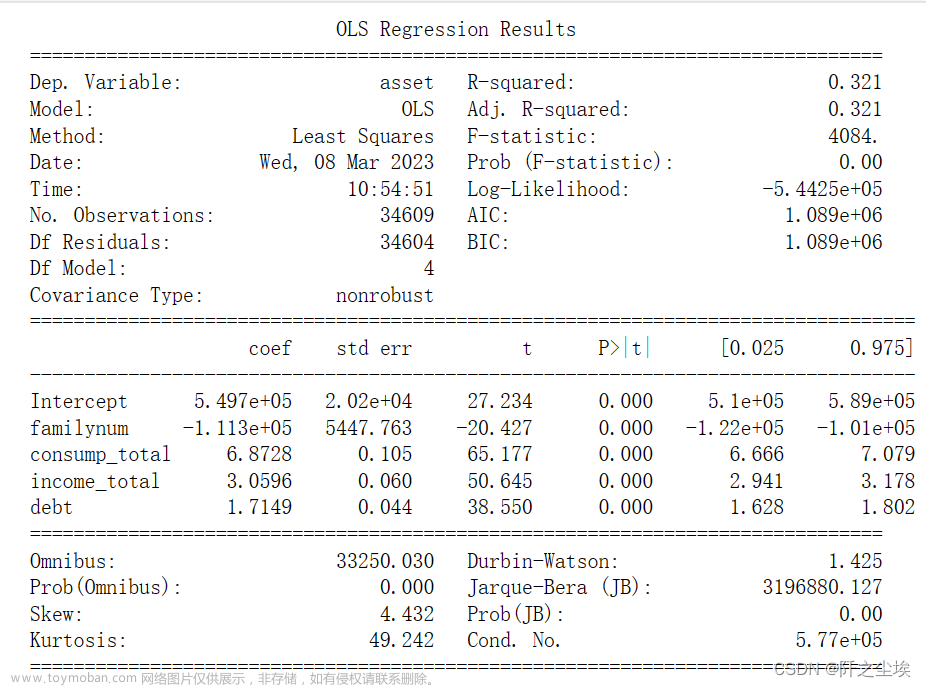
调整后的R-squared=0.32,说明资产变动的幅度有32%可以用此模型解释。虽然拟合优度不算很高,但是整体回归模型的F值为4083.75,说明整体回归方程十分显著。
对于每一个变量的显著性检验,从回归结果中,我们可以发现在0.05的显著性水平下,观察P值, 四组解释变量它们的系数,都通过了显著性检验,说明他们的变动对于资产的变动影响是显著的。并且t值都很大,说明是十分显著。其中最为显著的是消费,说明消费越高的家庭资产也越高。而人口与资产是反方向变动,家庭里面的人口如果越多,那么家庭的资产就越少。
输出方差分析表
from statsmodels.stats.anova import anova_lm
anova_lm(results,typ=1)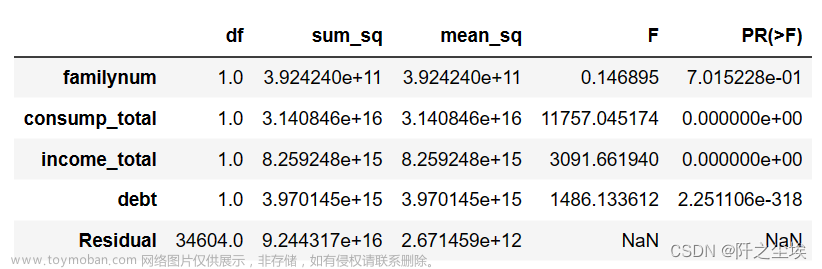
下面检验模型的多重共线性。
定义计算方差膨胀因子的函数VIF:
#容忍度和方差扩大因子
def vif(df_exog,exog_name):
exog_use = list(df_exog.columns)
exog_use.remove(exog_name)
model=smf.ols(f"{exog_name}~{'+'.join(list(exog_use))}",data=df_exog).fit()
rsq=model.rsquared
return 1./(1.-rsq)计算上述的回归得到的方差膨胀因子如下:
df_vif=pd.DataFrame()
for x in data.columns[:-1]:
vif_i=vif(data.iloc[:,:-1],x) #X们都放入
df_vif.loc['VIF',x]=vif_i
df_vif.loc['tolerance']=1/df_vif.loc['VIF']
df_vif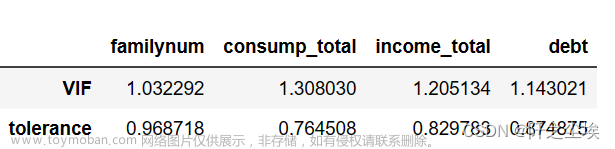
一般认为方差膨胀因子大于10的变量就具有多重共线性,本文的四个变量的VIF值都是一点多,远小于10,说明模型不存在严重的多重共线性。
残差分析
画出残差图和残差的QQ图:
x=results.fittedvalues ; y=results.resid
plt.subplots(1,2,figsize=(7,3),dpi=128)
plt.subplot(121)
plt.scatter(x,y)
plt.xlabel('拟合值')
plt.ylabel('残差')
plt.title('(a)残差值与拟合值图',fontsize=12)
plt.axhline(0,ls='--')
ax2=plt.subplot(122)
pplot=sm.ProbPlot(y,fit=True)
pplot.qqplot(line='r',ax=ax2,xlabel='期望正态值',ylabel='标准化的观测值')
ax2.set_title('(b)残差正态Q-Q图',fontsize=12)
plt.tight_layout()
plt.show()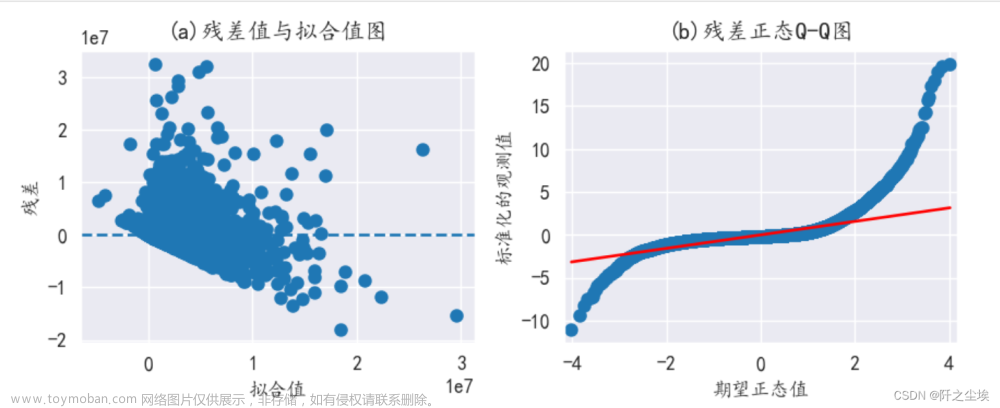
可以看到残差不是很符合正态性的假定,所以模型里面考虑的因素不完全,在残差里面体现出来了。这也是为什么拟合优度只有32%。因此这个模型需要考虑更多的变量进去才行。
四、研究结论及启示
(一)主要结论
本文首先通过分析我国家庭资产配置的特点以及和国外的不同,还有影响因素的可能性的分析。再利用2019年的家庭金融调查数据,选取了收入消费资产负债人口等因素做出回归分析,分析我国家庭资产变动影响因素。
实证结果显示,对于我国家庭资产来说,人口,消费,收入和负债都是影响家庭资产很重要的原因。他们对于资产都是有显著性的影响。其中影响因素最大的是消费,说明消费越多的家庭,他们的资产也越多。消费收入和负债,对于资产的影响都是正向变动的,而人口对于资产的影响是负向变动,说明一个家庭里面人口越多,资产越少。
结束语
本文的不足之处在于实证分析研究中模型较为简化,资产变动的影响控制变量有的不是很显著,考虑变量没有特别全面,因此拟合优度也不算很高。所以本文所得结论也具有一定程度的局限性。仅对该课题进行了浅层次的研究。文章来源:https://www.toymoban.com/news/detail-491170.html
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制代码可私信)文章来源地址https://www.toymoban.com/news/detail-491170.html
到了这里,关于Python数据分析案例20——我国家庭资产影响因素分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!