背景:在训练自己数据集进行kie之前,想跑一下md里面的例程,但md教程内容混乱,而且同一个内容有多个手册,毕竟是多人合作的项目,可能是为了工程解耦,方便更新考虑……需要运行的模型和运行步骤散落在不用文件夹下的不同md里面……很无语,对于新手小白真的很不友好,因此在这里,按照一个正常工程的使用顺序,进行一个总结。
本篇内容:使用PP-Structure 文档分析中关键信息抽取,运行VI-LayoutXLM模型在XFUND_zh数据集上的推理模型,跑通推理
2023.4.24更新:PaddleNLP中的新模型:UIE,在信息提取上的表现远好于VI-LayoutXLM,于是,VI-LayoutXLM方法已经被打入冷宫!
最新更好表现的UIE模型,见这篇:https://blog.csdn.net/z5z5z5z56/article/details/130346646
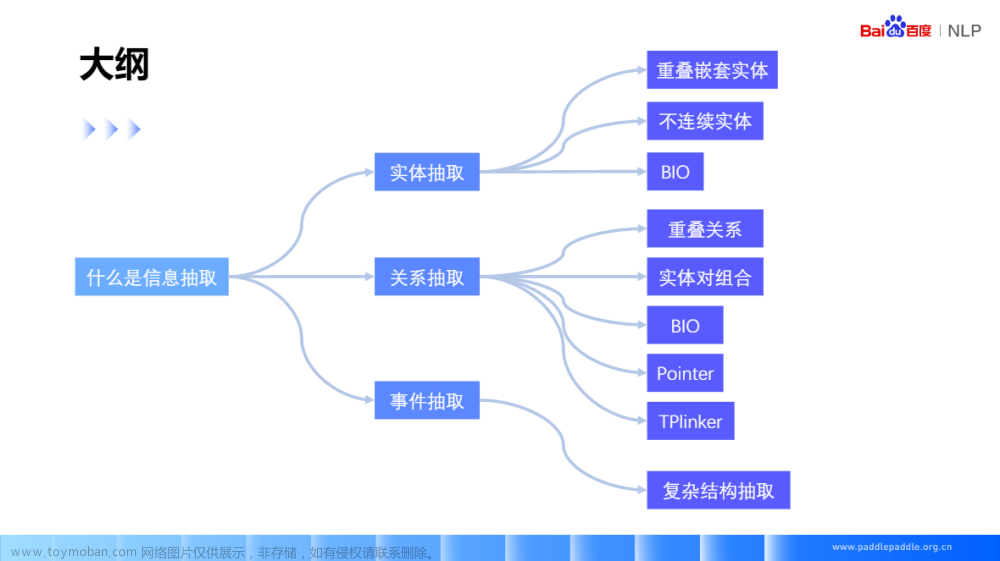
工程中关键信息提取相关内容
这里首先列出ppocr项目中与kie相关内容路径,方便查找,步骤从这些md中整合而来:
- (本文主要参考这个)关键信息抽取-快速开始手册:
.\ppstructure\kie\README_ch.md - 关键信息抽取全流程指南:
.\ppstructure\kie\how_to_do_kie.md - (自己模型训练评估与推理)关键信息抽取手册md
.\doc\doc_ch\kie.md - 关键信息抽取算法-VI-LayoutXLM
.\doc\doc_ch\algorithm_kie_vi_layoutxlm.md - 配置文件位于
.\configs\kie\vi_layoutxlm\ - 关键信息抽取数据集说明文档(介绍了FUNSD、XFUND、wildreceipt数据集三种)
.\doc\doc_ch\dataset\kie_datasets.md - 自己标注关键信息:PPOCRLabel使用文档
./PPOCRLabel/README_ch.md
本文参考
-(本文主要参考这个)PP-Structure 文档分析-关键信息抽取-快速开始手册:.\ppstructure\kie\README_ch.md
主要使用这个文件夹里面的内容
其他参考:https://blog.csdn.net/m0_63642362/article/details/128894464
理论部分
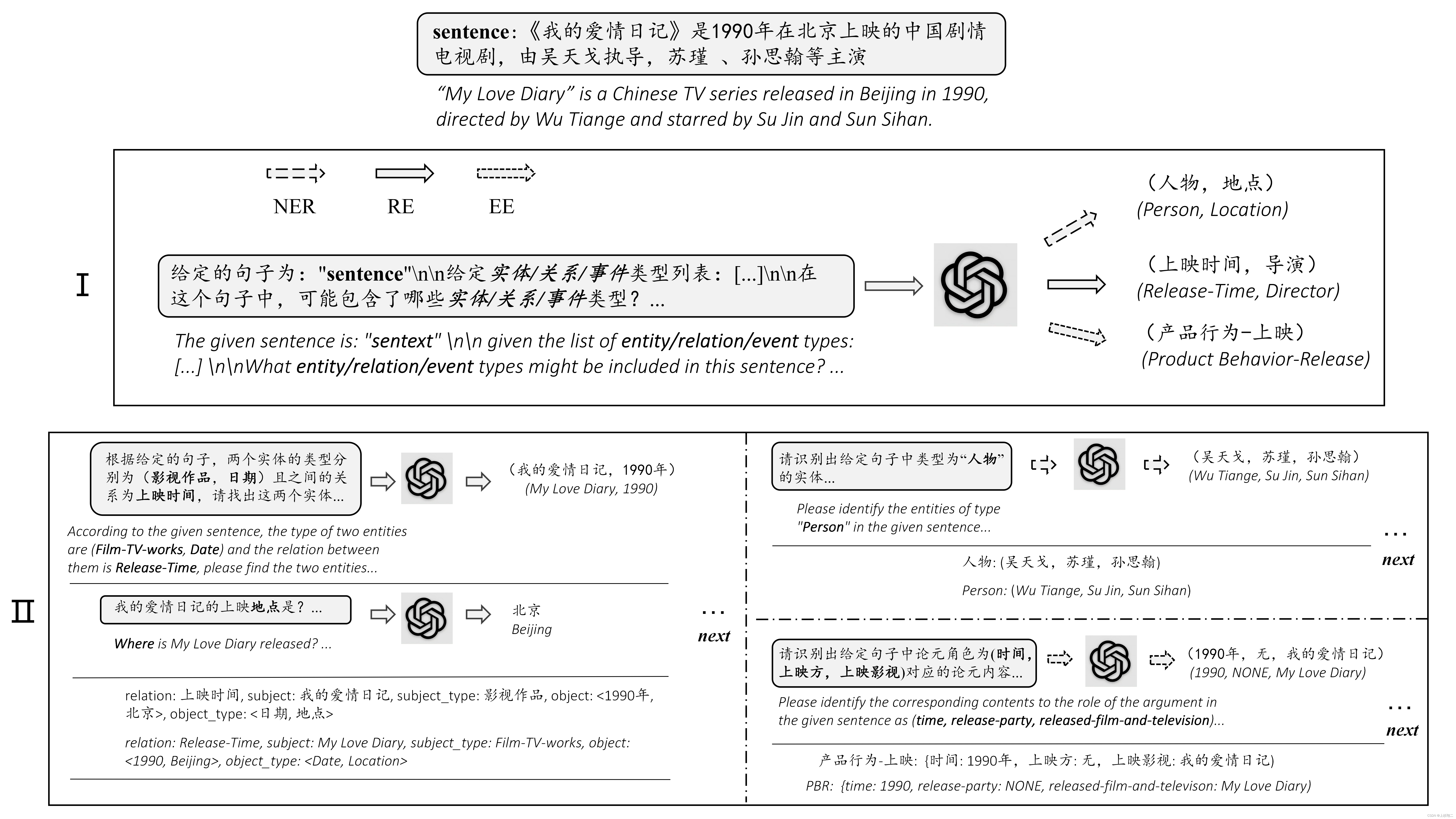
基于多模态模型的关键信息抽取任务有2种主要的解决方案。
(1)文本检测 + 文本识别 + 语义实体识别(SER)
(2)文本检测 + 文本识别 + 语义实体识别(SER) + 关系抽取(RE)
关于上述解决方案的详细介绍,请参考关键信息抽取全流程指南:.\ppstructure\kie\how_to_do_kie.md
我们下面首先执行单SER
step0、环境准备
除了前期基础环境安装
git clone https://github.com/PaddlePaddle/PaddleOCR.git
cd PaddleOCR
pip install -r requirements.txt
以外,还有一句
pip install -r ppstructure/kie/requirements.txt
step1、下载解压VI-LayoutXLM推理模型
环境配置这里不赘述,可以参考博主之前的文章,下面默认已经下载好ppocr项目文件夹了:
下表来自《关键信息抽取算法-VI-LayoutXLM》.\doc\doc_ch\algorithm_kie_vi_layoutxlm.md
下载保存推理模型到项目根目录名为model的文件夹里面
| 模型 | 骨干网络 | 任务 | 配置文件 | hmean | 下载链接 |
|---|---|---|---|---|---|
| VI-LayoutXLM | VI-LayoutXLM-base | SER | ser_vi_layoutxlm_xfund_zh_udml.yml | 93.19% | 训练模型/推理模型 |
| VI-LayoutXLM | VI-LayoutXLM-base | RE | re_vi_layoutxlm_xfund_zh_udml.yml | 83.92% | 训练模型/推理模型 |
或直接在终端下载+解压
#下载解压ser_vi_layoutxlm_xfund_infer.tar
wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_infer.tar
tar -xvf ser_vi_layoutxlm_xfund_infer.tar
#下载解压re_vi_layoutxlm_xfund_infer.tar
wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_infer.tar
tar -xvf re_vi_layoutxlm_xfund_infer.tar


step2、下载XFUND数据集
下载XFUND数据集,放在根目录train_data文件夹里面,
下载解压:
# 准备XFUND数据集,对于推理,这里主要是为了获得字典文件class_list_xfun.txt
mkdir ./PaddleOCR/train_data
wget https://paddleocr.bj.bcebos.com/ppstructure/dataset/XFUND.tar
tar -xf XFUND.tar
之所以叫train_data,是因为和配置文件里面的路径保持一致,方便不修改yaml文件而直接用

step3、使用模型进行预测(基于PaddleInference)
PaddleOCR/ppstructure/kie
单SER: 语义实体识别 (Semantic Entity Recognition)
使用前面下载好的SER推理模型
cd ppstructure
python3 kie/predict_kie_token_ser.py \
--kie_algorithm=LayoutXLM \
--ser_model_dir=../model/ser_vi_layoutxlm_xfund_infer \
--image_dir=./docs/kie/input/zh_val_42.jpg \
--ser_dict_path=../train_data/XFUND/class_list_xfun.txt \
--vis_font_path=../doc/fonts/simfang.ttf \
--ocr_order_method="tb-yx"
复制版
python3 kie/predict_kie_token_ser.py --kie_algorithm=LayoutXLM --ser_model_dir=../model/ser_vi_layoutxlm_xfund_infer --image_dir=./docs/kie/input/zh_val_42.jpg --ser_dict_path=../train_data/XFUND/class_list_xfun.txt --vis_font_path=../doc/fonts/simfang.ttf --ocr_order_method="tb-yx"
- ser_model_dir:我放在model文件夹内,
- image_dir:要预测的图片
- ser_dict_path:指向数据集的list文件位置
- vis_font_path:是字体文件夹
第一次运行会下载一些模型
可视化结果保存在ppstructure/output目录下
对应infer.txt
SER+RE: 关系抽取 (Relation Extraction)
cd ppstructure
python3 kie/predict_kie_token_ser_re.py \
--kie_algorithm=LayoutXLM \
--ser_model_dir=../model/ser_vi_layoutxlm_xfund_infer \
--re_model_dir=../model/re_vi_layoutxlm_xfund_infer\
--use_visual_backbone=False \
--image_dir=./docs/kie/input/zh_val_42.jpg \
--ser_dict_path=../train_data/XFUND/class_list_xfun.txt \
--vis_font_path=../doc/fonts/simfang.ttf \
--ocr_order_method="tb-yx"
复制版
python3 kie/predict_kie_token_ser_re.py --kie_algorithm=LayoutXLM --ser_model_dir=../model/ser_vi_layoutxlm_xfund_infer --re_model_dir=../model/re_vi_layoutxlm_xfund_infer --use_visual_backbone=False --image_dir=./docs/kie/input/zh_val_42.jpg --ser_dict_path=../train_data/XFUND/class_list_xfun.txt --vis_font_path=../doc/fonts/simfang.ttf --ocr_order_method="tb-yx"
我在NX盒子上推理会比较慢

RE在有些内容上还是比较弱的
另一种方法(基于动态图的预测)
手册里面还有一个使用tools/infer_kie_token_ser.py代码,PaddleOCR引擎的,使用预训练模型的,基于动态图的预测
不过经过实测,这里直接使用预训练模型和上面使用微调模型效果一样,毕竟没微调
#安装PaddleOCR引擎用于预测
pip install paddleocr -U
mkdir pretrained_model
cd pretrained_model
# 下载并解压SER预训练模型
wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_pretrained.tar && tar -xf ser_vi_layoutxlm_xfund_pretrained.tar
# 下载并解压RE预训练模型
wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_pretrained.tar && tar -xf re_vi_layoutxlm_xfund_pretrained.tar
如果希望使用OCR引擎,获取端到端的预测结果,可以使用下面的命令进行预测。
仅预测SER模型
python3 tools/infer_kie_token_ser.py \
-c configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml \
-o Architecture.Backbone.checkpoints=./pretrained_model/ser_vi_layoutxlm_xfund_pretrained/best_accuracy \
Global.infer_img=./ppstructure/docs/kie/input/zh_val_42.jpg
SER + RE模型串联
python3 ./tools/infer_kie_token_ser_re.py \
-c configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh.yml \
-o Architecture.Backbone.checkpoints=./pretrained_model/re_vi_layoutxlm_xfund_pretrained/best_accuracy \
Global.infer_img=./train_data/XFUND/zh_val/image/zh_val_42.jpg \
-c_ser configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml \
-o_ser Architecture.Backbone.checkpoints=./pretrained_model/ser_vi_layoutxlm_xfund_pretrained/best_accuracy
(后续训练篇幅涉及)如果希望加载标注好的文本检测与识别结果,仅预测可以使用下面的命令进行预测。
仅预测SER模型
python3 tools/infer_kie_token_ser.py \ -c
configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml \ -o
Architecture.Backbone.checkpoints=./pretrained_model/ser_vi_layoutxlm_xfund_pretrained/best_accuracy
\ Global.infer_img=./train_data/XFUND/zh_val/val.json \
Global.infer_mode=FalseSER + RE模型串联 python3 ./tools/infer_kie_token_ser_re.py \ -c configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh.yml \ -o
Architecture.Backbone.checkpoints=./pretrained_model/re_vi_layoutxlm_xfund_pretrained/best_accuracy
\ Global.infer_img=./train_data/XFUND/zh_val/val.json \
Global.infer_mode=False \ -c_ser
configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml \ -o_ser
Architecture.Backbone.checkpoints=./pretrained_model/ser_vi_layoutxlm_xfund_pretrained/best_accuracy
end
ps:文章来源:https://www.toymoban.com/news/detail-491223.html
在关键信息抽取手册md
.\doc\doc_ch\kie.md也有提到使用预训练模型的预测(tools/infer_kie_token_ser.py)
我们在后面几篇再展开:具体内容摘抄:
如您通过python3 tools/train.py -c configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml完成了模型的训练过程。您可以使用如下命令进行中文模型预测。python3 tools/infer_kie_token_ser.py -c configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=./pretrained_model/ser_vi_layoutxlm_xfund_pretrained/best_accuracy Global.infer_img=./ppstructure/docs/kie/input/zh_val_42.jpg
使用tools/infer_kie_token_ser.py需要首先有训练产生的checkpoints : ./output/ser_vi_layoutxlm_xfund_zh/best_accuracy作为支持,所以只能在训练后使用文章来源地址https://www.toymoban.com/news/detail-491223.html
到了这里,关于【PaddleOCR-kie】关键信息抽取1:使用VI-LayoutXLM模型推理预测(SER+RE)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!