这篇具有很好参考价值的文章主要介绍了【Stable Diffusion论文精读】High-Resolution Image Synthesis with Latent Diffusion Models(主打详细和易懂)。希望对大家有所帮助。如果存在错误或未考虑完全的地方,请大家不吝赐教,您也可以点击"举报违法"按钮提交疑问。
文章来源地址https://www.toymoban.com/news/detail-491225.html
文章来源:https://www.toymoban.com/news/detail-491225.html
到了这里,关于【Stable Diffusion论文精读】High-Resolution Image Synthesis with Latent Diffusion Models(主打详细和易懂)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处: 如若内容造成侵权/违法违规/事实不符,请点击违法举报进行投诉反馈,一经查实,立即删除!

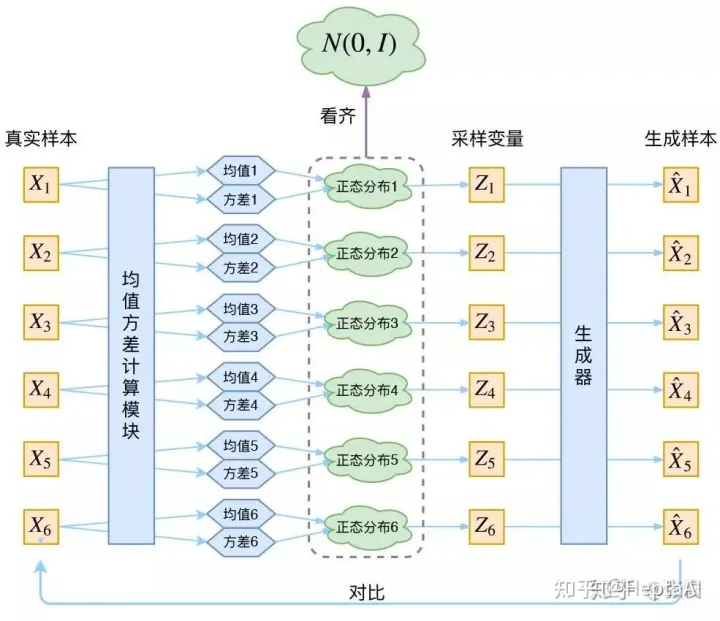



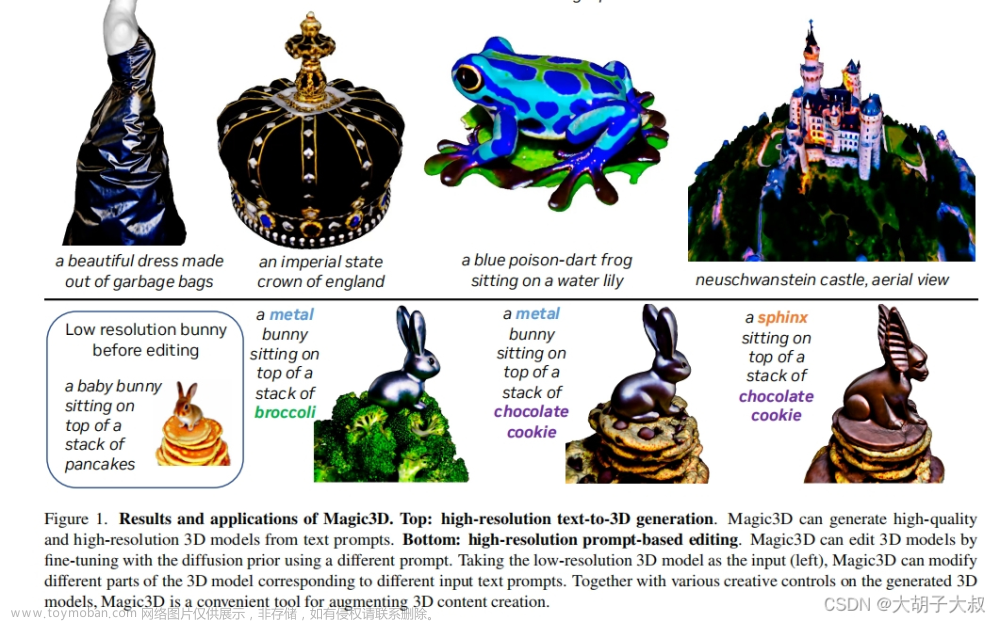


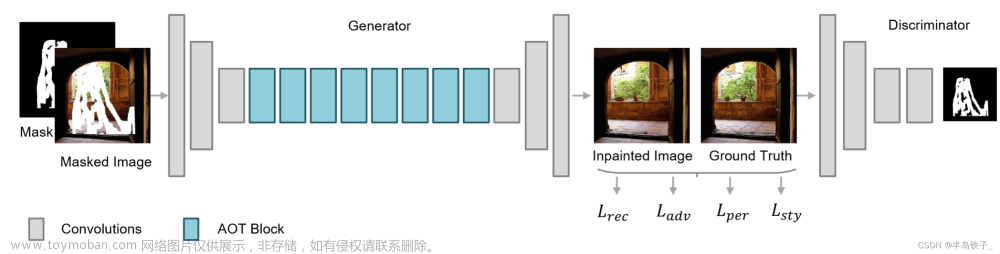
![[CVPR-23-Highlight] Magic3D: High-Resolution Text-to-3D Content Creation](https://imgs.yssmx.com/Uploads/2024/02/642215-1.png)



