1. 基本信息
| 题目 | 论文作者与单位 | 来源 | 年份 |
|---|---|---|---|
| GPT Understands, Too | 清华大学 |
Citations, References
论文链接:https://arxiv.org/pdf/2103.10385.pdf
论文代码:
2. 要点
| 研究主题 | 问题背景 | 核心方法流程 | 亮点 | 数据集 | 结论 | 论文类型 | 关键字 |
|---|---|---|---|---|---|---|---|
| 微调大模型 | 采用传统微调的gpt在自然语言理解(NLU)方面未能取得良好的效果,所以提出了P-tuning. | LAMA,SuperGlue | P-tuning在少样本上,在bert,gpt都取得不错的效果。 |
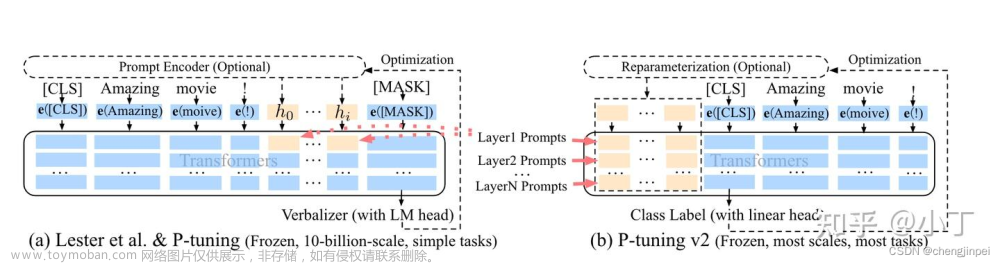
3. 模型(核心内容)
3.1 模型例子
![[论文阅读笔记76]GPT Understands, Too(P-tuning)](https://imgs.yssmx.com/Uploads/2023/06/491257-1.png)
这里的模型思想是例如有一个模板T:The capital of [X] is [Y], 这里的X定义为上下文,Y定义为目标,其它字符表示prompt.
对于离散型,每一个prompt提示词都可以在V词典中查到,然后都可以经过预模型模型进行编码。
*** T = {*****[P_0:i ], x, *****[P_*****i+1:m], y}, [P_i ] *****∈ V, ***
![[论文阅读笔记76]GPT Understands, Too(P-tuning)](https://imgs.yssmx.com/Uploads/2023/06/491257-2.png)
在p-tuning中p_i被看成是一个伪token,对应用的模板应该是这样的:
![[论文阅读笔记76]GPT Understands, Too(P-tuning)](https://imgs.yssmx.com/Uploads/2023/06/491257-3.png)
这里的h_i是可以训练的的,通过训练可以获得列准确的prompt,这个prompt将会超过当前的prompt.
最后的损失函数为:
![[论文阅读笔记76]GPT Understands, Too(P-tuning)](https://imgs.yssmx.com/Uploads/2023/06/491257-4.png)
其它这个跟之前几篇思想是一样的。直接把离散的代替成了连续的。
优化时面临两个挑战:
Discreteness
如果h用随机分布初始化,优化器很容易落入局部极小值。
Association
嵌入的h应该是相互联系的,并不是独立的,在设计时应该把h的相关作用加入去。
解决这个方法: 把h隐变量建立成一个序列,采用一prompt编码器来进行编码,这个编码器采用小而轻的神经网络的完成。实际的实践中采用了lstm来完成。
![[论文阅读笔记76]GPT Understands, Too(P-tuning)](https://imgs.yssmx.com/Uploads/2023/06/491257-5.png)
4. 实验与分析
4.1 实验
任务1:LAMA (Petroni et al., 2019) knowledge probing
把三元组 (Dante, born-in, Florence) 变成cloze的句子:“Dante was born in [MASK].”,作为原始的样本。
![[论文阅读笔记76]GPT Understands, Too(P-tuning)](https://imgs.yssmx.com/Uploads/2023/06/491257-6.png)
1) Manual Prompt(MP):使用LAMA的原始手工提示;
2)Fine-tuning(FT):通过主语与微调模型去预测宾语;
3) Manual Prompt with Fine-tuning(MP+FT):使用手工提示数据来微调语言模型;
4)P-tuning:使用连接提示(固定语言模型的参数)。
另外发现,LAMA-29k数据集中P-tuning比fine tuning还要好。
任务2:SuperGlue (Wang et al., 2019b)
BERT-base-case,GPT2-base,BERT-large-cased, GPT2-medium, 从这些实验结果来看,基本上是超过Fine-tuning的效果的。
![[论文阅读笔记76]GPT Understands, Too(P-tuning)](https://imgs.yssmx.com/Uploads/2023/06/491257-7.png)
![[论文阅读笔记76]GPT Understands, Too(P-tuning)](https://imgs.yssmx.com/Uploads/2023/06/491257-8.png)
few shot中的提示的语义、格式、语法没有明显的相关性,其次,手动提示中的微小变化会导致巨大的性能差异。
![[论文阅读笔记76]GPT Understands, Too(P-tuning)](https://imgs.yssmx.com/Uploads/2023/06/491257-9.png)
5. 总结
思想与之前的两篇的差不多,这篇也做了很多实验,效果大部分可与fine tuning进行比较了。挺好的。文章来源:https://www.toymoban.com/news/detail-491257.html
7. 知识整理(知识点,要读的文献,摘取原文)
8. 参考文献
made by happyprince文章来源地址https://www.toymoban.com/news/detail-491257.html
到了这里,关于[论文阅读笔记76]GPT Understands, Too(P-tuning)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!