一:服务器虚拟化
1.名词解释
(1)资源动态调整(对象是虚拟机)
管理员操作,对CPU、内存、网卡、硬盘、GPU进行调整。
FusionCompute支持虚拟机资源动态调整,用户可以根据业务负载动态调整资源的使用情况。
虚拟机资源调整包括:
离线/在线调整vCPU数目
无论虚拟机处于离线(关机)或在线状态,用户都可以根据需要增加虚拟机的vCPU数目。虚拟机处于离线状态时,用户可以根据需要减少虚拟机的vCPU数目。通过离线/在线调整虚拟机vCPU数目,可以满足虚拟机上业务负载发生变化时对计算能力灵活调整的需求。
离线/在线调整内存大小
无论虚拟机处于离线或在线状态,用户都可以根据需要增加虚拟机的内存容量。虚拟机处于离线状态时,用户可以根据需要减少虚拟机的内存容量。通过离线/在线调整内存大小,可以满足虚拟机上业务负载发生变化时对内存灵活调整的需求。
离线/在线添加/删除网卡
虚拟机在线/离线状态下,用户可以挂载或卸载虚拟网卡,以满足业务对网卡数量的需求。
离线/在线挂载虚拟磁盘
无论虚拟机处于离线或在线状态,用户都可以挂载虚拟磁盘,在不中断用户业务的情况下,增加虚拟机的存储容量,实现存储资源的灵活使用。
在线增加CPU和内存可以在线生效,不需要重启,但前提是需要开启虚拟机的热插拔开关才行,且对操作系统的版本也有一定的限制,不是所有的操作系统都支持在线增加CPU和内存。
(2)动态资源调度DRS(对象是集群)
DRS,即动态资源调度 (Dynamic Resource Scheduler):指采用智能负载均衡调度算法,并结合动态电源管理功能,通过周期性检查同一集群资源内各个主机的负载情况,在不同的主机间迁移虚拟机,从而实现同一集群内不同主机间的负载均衡,并最大程度降低系统的功耗。
在 FusionCompute 中,可以配置集群动态资源调度功能:采用智能负载均衡调度算法,周期性检查集群内主机的负载情况,在不同的主机之间迁移虚拟机,从而达到集群内的主机之间负载均衡目的。
集群的自动化级别有两种:自动和手动。在自动调度模式下,系统会自动将虚拟机迁移到最合适的主机上。在手动操作模式下,系统会生成操作建议供管理员选择,管理员根据实际情况决定是否应用建议。
资源调度可以配置不同的衡量因素,可以根据 CPU、内存或 CPU 和内存进行调度。只有资源复用时,才会影响虚拟机性能。因此,如果未使用内存资源复用,建议配置为根据 CPU 调度。如果使用内存复用,建议配置为根据 CPU 和内存综合调度。
资源调度的高级规则可以用来满足一些特殊需求。例如两台虚拟机是主备关系时,可以为其配置互斥策略,使其运行在不同的主机上以提高可靠性。
资源调度的分时阈值设置,可以满足不同时段的调度需求。由于虚拟机迁移会带来一定的系统开销,所以建议在业务压力较大时设置为保守策略,在业务压力较小时设置为中等或激进策略,避免影响业务性能。
操作对象:1、内存 2、cpu 3、cpu+内存 第3点的关系是“且”的关系。达到负载高度时,只要一个达到就触发。
引申:
FC集群内无法使用DRS的原因有哪些?
1、设置了聚集或者互斥规则组;
2、虚拟机禁用了DRS;
3、虚拟机与所在主机进行了绑定;
4、虚拟机与DRS的目标主机不兼容;
5、迁移阈值为“保守”;
6、某设备挂载了一个或多个虚拟机;
7、虚拟机内存大于 8G。
DRS需要共享的存储
(3)动态资源管控QOS 即服务质量(quality of service),服务质量,为了在资源紧张的情况下,保障关键业务的体验度。Qos包括CPU Qos、内存QOS、磁盘Qos、网卡Qos。
CPU资源份额 CPU份额定义多个虚拟机在竞争物理CPU资源的时候按比例分配计算资源。 以一个主频为2.8GHz的单核物理主机为例,如果上面运行有三台单CPU的虚拟机。三个虚拟机A,B,C,份额分别为1000,2000,4000。当三个虚拟机CPU满负载运行时,会根据三个虚拟机的份额按比例分配计算资源。份额为1000的虚拟机A的计算能力约为400MHz的,份额为2000的虚拟机B获得的计算能力约为800MHz,份额为4000的虚拟机C获得的计算能力约为1600MHz。(以上举例仅为说明CPU份额的概念,实际应用过程中情况会更复杂)。 CPU份额只在各虚拟机竞争计算资源时发挥作用,如果没有竞争情况发生,有需求的虚拟机可以独占物理CPU资源,例如,如果虚拟机B和C均处于空闲状态,虚拟机A可以获得整个物理核即2.8GHz的计算能力。 CPU资源预留 CPU预留定义了多个虚拟机竞争物理CPU资源的时候分配的最低计算资源。 如果虚拟机根据份额值计算出来的计算能力小于虚拟机预留值,调度算法会优先按照虚拟机预留值的能力把计算资源分配给虚拟机,对于预留值超出按份额分配的计算资源的部分,调度算法会从主机上其他虚拟机的CPU上按各自的份额比例扣除,因此虚拟机的计算能力会以预留值为准。 如果虚拟机根据份额值计算出来的计算能力大于虚拟机预留值,那么虚拟机的计算能力会以份额值计算为准。 以一个主频为2.8GHz的单核物理机为例,如果运行有三台单CPU的虚拟机A、B、C,份额分别为1000、2000、4000,预留值分别为700MHz、0MHz、0MHz。当三个虚拟机满CPU负载运行时: 虚拟机A如果按照份额分配,本应得400MHz,但由于其预留值大于400MHz,因此最终计算能力按照预留值700MHz算。 多出的(700-400)MHz按照B和C各自的份额比例从B和C处扣除。 虚拟机B获得的计算能力约为(800-100)MHz,虚拟机C获得的计算能力约为(1600-200)MHz。 CPU预留只在各虚拟机竞争计算资源的时候才发挥作用,如果没有竞争情况发生,有需求的虚拟机可以独占物理CPU资源。例如,如果虚拟机B和C均处于空闲状态,虚拟机A可以获得整个物理核即2.8GHz的计算能力。 CPU资源限额 控制虚拟机占用物理CPU资源的上限。以一个两CPU的虚拟机为例,如果设置该虚拟机CPU上限为3GHz,则该虚拟机的两个虚拟CPU计算能力被限制为1.5GHz。
内存资源份额 内存份额定义多个虚拟机竞争内存资源的时候按比例分配内存资源。 在虚拟机申请内存资源,或主机释放空闲内存(虚拟机迁移或关闭)时,会根据虚拟机的内存份额情况按比例分配。 不同于CPU资源可实时调度,内存资源的调度是平缓的过程,内存份额策略在虚拟机运行过程中会不断进行微调,使虚拟机的内存获取量逐渐趋于比例。 以6G内存规格的主机为例,假设其上运行有三台4G内存规格的虚拟机,内存份额分别为20480、20480、40960,那么其内存分配比例为1:1:2。当三个虚拟机内部均逐步加压,策略会根据三个虚拟机的份额按比例分配调整内存资源,最终三个虚拟机获得的内存量稳定为1.5G、1.5G、3G。 内存份额只在各虚拟机竞争内存资源时发挥作用,如果没有竞争情况发生,有需求的虚拟机可以最大限度地获得内存资源。例如,如果虚拟机B和C没有内存压力且未达到预留值,虚拟机A内存需求压力增大后,可以从空闲内存、虚拟机B和C中获取内存资源,直到虚拟机A达到上限或空闲内存用尽且虚拟机B和C达到预留值。以上面的例子,当份额为40960的虚拟机没有内存压力(内存资源预留为1G),那么份额为20480的两个虚拟机理论上可以各获得最大2.5G的内存。 内存资源预留 内存预留定义多个虚拟机竞争内存资源的时候分配的内存下限,能够确保虚拟机在实际使用过程中一定可使用的内存资源。 预留的内存被会虚拟机独占。即,一旦内存被某个虚拟机预留,即使虚拟机实际内存使用量不超过预留量,其他虚拟机也无法抢占该虚拟机的空闲内存资源。 内存资源限额 控制虚拟机占用物理内存资源的上限。在开启多个虚拟机时,虚拟机之间会相互竞争内存资源,为了使虚拟机的内存得到充分利用,尽量减少空闲内存,用户可以在创建虚拟机时设置虚拟机配置文件中的内存上限参数,使服务器分配给该虚拟机的内存大小不超过内存上限值。 内存资源限额需要开启内存复用开关才有效,否则无法调整。
网络Qos策略提供带宽配置控制能力,Qos功能不支持同一主机上虚拟机之间的流量限制。包含如下方面:
基于端口组成员接口发送方向与接收方向的带宽控制
基于端口组的每个成员接口提供流量整形、带宽优先级的控制能力。
在端口组中配置,针对发送流量和接受流量流做Qos,有以下三种属性 平均带宽(某段时间内允许通过端口的平均每秒发送/接收位数) 峰值带宽(发送/接收流量突发时,每秒钟允许通过端口的最大传输位数) 突发大小(允许流量在平均带宽的基础上产生的突发流量的大小)
磁盘Qos:
可设置虚拟机每个磁盘的IO上限,以避免某个虚拟机的磁盘IO过大,影响其他虚拟机的性能
存储QOS在哪设置?
点击虚拟机-磁盘-更多-设置磁盘IO上线(BPS和IOPS)
BPS:描述每秒IO大小
IOPS:每秒进行读写操作的次数
磁盘方面可以限制读写的IOPS和BPS。
(4)动态资源管理DPM
DPM,动态电源管理 (Dynamic Power Management),根据业务情况,智能地将部分物理机上下电。
对应 FusionCompute 中的“电源管理自动化”:电源管理自动化功能会周期性地检查集群中服务器的资源使用情况,如果集群中资源利用率不足,则会将多余的主机下电节能,下电前会将虚拟机迁移至其他主机;如果集群资源过度利用,则会将离线的主机上电,以增加集群资源,减轻主机的负荷。
电源管理依赖于计算资源调度,因此电源管理只有在开启计算资源调度,并且迁移阈值的设置不为"保守"时生效。
当系统的集群下主机的“最大CPU占用率和最大内存占用率超过了设定值,此时会开始执行调度策略,调度方式分为手动跟自动。
引申:
上电:VRM通过 CNA 物理节点上的BMC 卡完成上电动作。
下电:VRM 通过 VNA 对 CNA 节点进行安全关机动作。
引申:
CPU和内存预留有什么区别?
CPU预留不会独占CPU,内存预留会独占内存。
分布式资源调度:(慎答)
先问考官是不是DRS,如果不是就答私有云场景的
针对私有云,在多个VDC中动态调整资源,把负载低的VDC中的资源调整到负载高的VDC资源中去用。
如果考官追问一个VDC可不可以动态调整资源,就答我一个VDC中可以动态调整多个AZ中的资源。
答案有待验证。
(5)弹性IP
弹性IP(Elastic IP,EIP),是基于互联网上的静态IP地址,是可以通过Internet直接访问的IP地址。弹性IP可以与子网中关联的弹性云服务器、裸金属服务器、虚拟IP、弹性负载均衡等资源灵活地绑定及解绑。
私有云局域网(LAN)上各个实例配置的IP地址都是私有IP地址,无法访问互联网。当实例上的应用需要访问外部网络时,可以通过绑定弹性IP的方式来实现VPC中的实例通过固定的公网IP地址与互联网互通。
作用:
弹性IP用于构建云资源的外网出口,可与多种业务资源灵活地绑定与解绑,满足各种业务诉求。
用户可以将弹性IP绑定到ECS或BMS上,绑定后的ECS或BMS即可连接公网。
用户可以为虚拟IP地址绑定一个弹性IP,从互联网可以访问后端绑定了同一个虚拟IP地址的多个主备部署的弹性云服务器,增强容灾性能。
用户可以为负载均衡器绑定弹性IP,可以接收来自公网的访问请求并将请求自动分发到添加的多台弹性云服务器。
共享带宽可提供多实例使用一条带宽的功能,用户根据实际业务情况,将对带宽要求不高的实例加入共享带宽。
多个弹性IP共享一条带宽,相较于独立带宽大大节省带宽使用成本。
提供Region级别的带宽复用共享能力,节省带宽使用的运营及运维成本。
共享带宽拥有超大弹性峰值,用户可根据实际情况通过调整带宽大小来调整峰值。
可以和哪些服务绑定?
弹性IP地址(Elastic IP address,EIP)是可以通过Internet直接访问的IP地址。弹性IP是一个静态的公共IP地址,可以与弹性云服务器、裸金属服务器、虚拟IP、弹性负载均衡等资源灵活地绑定及解绑 。将弹性IP地址和子网中关联的云服务器绑定,可以实现云服务器与Internet互通。
弹性IP一定公网IP吗?
不一定,他也可以是企业内部的IP
弹性IP和ECS什么比列关系?
是1:1。也可以1:M(就是我们可以申请一个ELB,为这个ELB绑定一个EIP,那么我们多个ECS就可以同时通过一个EIP出去了)。
EIP和FIP有什么关系?
EIP=FIP
EIP是私有云中云服务的说法
FIP是OpenStack的说法
(6)内存复用
内存复用是指在服务器物理内存一定的情况下,通过综合运用内存复用单项技术(内存气泡、内存共享、内存交换)对内存进行分时复用。通过内存复用,使得虚拟机内存规格总和大于服务器规格内存总和,提高服务器中虚拟机密度。
内存共享+写时复制:虚拟机之间共享同一物理内存空间(蓝色),此时虚拟机仅对内存做只读操作。当虚拟机需要对内存进行写操作时(红色),开辟另一内存空间,并修改映射(多台虚拟机共享数据内容为零的内存页(新版本叫共享数据内容相同的内存页))。
内存置换:虚拟机长时间未访问的内存内容被置换到外部存储中,并建立映射,系统需要使用这些数据时,再与预留在内存上的数据进行交换。
内存气泡:系统主动回收虚拟机暂时不用的物理内存,分配给需要复用内存的虚拟机。内存的回收和分配均为系统动态执行,虚拟机上的应用无感知。整个物理服务器上的所有虚拟机使用的分配内存总量不能超过该服务器的物理内存总量。
作用:当出现竞争时,由内存复用策略为虚拟机实时调度内存资源,综合运用内存复用技术释放虚拟机的空闲内存,为其他虚拟机的内存需求提供条件。
价值(应用场景上):
1)降低运营商或者企业的成本
2)计算节点内存数量固定时,提高虚拟机密度
3)计算节点虚拟机密度固定时,节省计算节点内存数量
限制条件:
1.每个计算节点上运行的所有虚拟机的预留内存之和不能大于节点虚拟化域内存总和。
2.旧版6.1之前:与Guestnuma、inic网卡冲突,Guestnuma、inic网卡会独占内存。与内存复用冲突。
3.新版6.3之后:内存复用与SRIOV直通、GPU直通、NVME SSD盘直通特性互斥。直通设备的虚拟机必须内存独占,内存独占后虚拟机的内存不会被交换到交换空间。内存复用的虚拟机不能直通设备。
4.主机需要配置足够的交换空间才能保证内存复用功能的稳定运行。主机最大内存复用率依赖于swap空间大小配置,具体计算公式如下:
主机支持的最大内存复用率=1+(主机swap空间大小-虚拟化域物理内存大小*0.1)/虚拟化域物理内存大小。
内存共享+写时复制:共享的是相同的数据,别答零页数据,零页数据虽然也可以,但是不全面。
引申:
内存复用作用的对象是主机还是集群?
集群
虚拟机内存复用比到120:触发告警 150:无法创建新的虚拟机。
内存气泡怎么将内存分配给其他虚拟机的?
是通过修改映射关系将内存分配给其他虚拟机的。
内存复用的3项技术可以单独使用某一个吗?
不可以,开启内存复用后,3项技术必须同时使用,不能单独使用。
内存复用技术开启对虚拟机有影响么?
内存复用技术默认不开启,开启后对虚拟机有一定影响,通过内存复用3项技术可知,虚拟机使用内存时会有一定的延迟。
关闭内存复用要注意什么?
将集群内所有运行中的虚拟机的内存预留设置:内存预留=内存规格。
谁监控内存不足?
Hypervisor
内存置换,为什么不直接从硬盘的数据返回给用户,要置换回内存,再给用户?
从硬盘直接读取数据的话相对比较慢,因为在硬盘中还要进行数据的检索会浪费时间,性能相对较低,而且对于用 户读取数据的流程一般都是先读缓存,因为速度较快性能较好,这也是为什么要置换回内存的主要原因。
内存置换,是换到主机磁盘还是虚拟机磁盘?
主机磁盘,且是虚拟化的本地硬盘。
3种技术都有影响吗?
都有。内存共享因为要开辟新的写空间,导致性能下降。内存置换,因为要把数据存放在外部存储上,数据调用时需要访问外部存储。内存气泡因为要做内存的回收和重分发,会有性能影响。
哪种内存复用性能影响最大?
内存置换
实现内存超分配是用的哪一种技术?
内存气泡,其它两种技术用来配合内存气泡使用,提供更多的空闲内存。
(7)快照
快照是什么?
快照是(虚拟机)某一时刻下数据的一个副本或复制。
或者说快照是特定数据集的一个完整可用拷贝,该数据集包含源数据在拷贝点的静态映象,快照可以是数据再现的一个副本或者复制。
COW:COW 在创建快照时,并不会发生物理的数据拷贝动作,仅是拷贝了原始数据所在的源数据块的物理位置元数据。因此,COW 快照创建非常快,可以瞬间完成。在创建了快照之后,快照软件会监控跟踪原始数据的变化(即对源数据块的写操作),一旦源数据块中的原始数据被改写,则会将源数据块上的数据拷贝到新数据块中,然后将新数据写入到源数据块中覆盖原始数据。新数据块就组成了快照卷。COW 有一个很明显的缺点,就是会降低源数据卷的写性能,因为每次改写新数据,实际上都进行了两次写操作。(例如新数据 D’更新原始数据D。此时在D’覆盖D之前,需要先把D拷贝到快照卷中,并且更新快照数据指针表的记录使其指向新的存储地址。最后再将D’写入到D原来的位置,源数据指针表不需要更新。)
ROW:ROW的实现原理与COW非常相似,区别在于ROW对原始数据卷的首次写操作,会将新数据重定向到预留的快照卷中。在创建快照之后,也就是在快照时间点之后,发生了写操作,那么新数据会直接被写入到快照卷中,然后再更新源数据指针表的记录,使其指向新数据所在的快照卷地址。
ROW与COW最大的不同就是:COW的快照卷存放的是原始数据,而ROW的快照卷存放的是新数据。ROW在传统存储场景下最大的问题是对读性能影响比较大。
ROW(写前重定向):写直接写快照卷,读:先读快照、再读原卷 读性能会有所影响,特别多次快照之后 ,读性能会有较大影响(可能会出现比较严重的数据碎片化)
COW(写前复制):写:假如原位置有数据,先将数据复制到快照卷中,再把新数据写到原卷中。写性能会有较大影响。读,直接读原卷。
全拷贝:将数据完全镜像一份,优点:快照可以不依赖原卷 缺点:十分占用空间
对虚拟机快照:1、虚拟机本身的描述文件2、虚拟磁盘
一致性快照:将内存上的数据先写入到磁盘中再对磁盘打快照
内存快照:直接对内存打快照
引申:
创建快照时,当前磁盘被置为只读,系统自动在磁盘所在数据存储中创建增量磁盘,后续对该磁盘数据的编辑将保存在增量磁盘中,即增量磁盘表示磁盘当前状况和上次执行快照时的状况之间的差异。对该磁盘再次创建快照时,原磁盘和当前增量磁盘均被置为只读,系统会在数据存储中再创建一个增量磁盘。
如果该虚拟机有多个快照,则在删除快照后,该快照内的数据会自动合并到该虚拟机的下一个快照中。
应用场景:
虚拟机用户在执行一些重大、高危操作之前,例如系统补丁、升级、破坏性测试前执行快照,可以用于故障时的快速还原。
(8)HA
解释:当一台主机或者虚拟机发生故障的时候,系统将会在资源池内启动一台虚拟机到其他可用的物理主机上。
原理:管理节点会自动查询VM状态,发现故障后会查看VM是否有HA属性,如果开启了 HA属性会把故障机的规格信息发给可用的CNA并启动这台虚拟机,启动过程中会将VM 之前的卷重新挂载,包括用户卷。
怎么触发HA?
1.主机发生宕机、上下电、重启的时候
2.虚拟机系统放生故障的时候:window蓝屏、Linux Panic
3.CAN与VRM心跳中断30秒的时候
4.系统故障检测,通过在主机之间实行网络心跳检测,发现没有主机与虚拟机没有IO行为的时候触发HA(整个行为与VRM无关)
预留方案
HA 资源预留:在整个集群内按照配置的值预留 CPU 与内存资源,该资源仅用于虚拟机 HA 功能使用。
使用故障专用切换主机:预留故障专用切换主机,平时该主机不对外提供业务。
集群允许主机故障设置:设置集群内允许指定数目的主机发生故障,系统定期检查集群内是否留有足够的资源来对这些主机上的虚拟机进行故障切换。
条件:
1.安装Tools(实验证明,没有tools也能HA)。且正常运行;
2.其他主机有预留HA资源,不能处于维护模式;
3.共享存储;
4.VM不能绑定主机,USB设备和GPU;
5.集群开启HA功能。
整个HA过程数据会丢失吗?
会,会丢失未落盘的数据。
热迁移和HA有什么区别?
热迁移不会中断业务(用户无感知),HA会中断业务(HA触发时,业务已中断)
热迁移是计划性迁移,HA 是非计划性迁移
(9)镜像
镜像是一个包含了软件及必要配置的弹性云服务器模板,至少包含操作系统,还可以包含应用软件(例如,数据库软件)和私有软件。镜像分为公共镜像、私有镜像和共享镜像。
镜像服务(Image Management Service,以下简称IMS)提供简单方便的镜像自助管理功,能。用户可以灵活便捷的使用公共镜像、私有镜像或共享镜像申请弹性云服务器。同时,用户还能通过弹性云服务器或外部镜像文件创建私有镜像。
引申:3种镜像有什么区别?
公共镜像
公共镜像是云平台系统提供的标准镜像,包含常见的标准操作系统和预装的公共应用,能够提供简单方便的镜像自助管理功能,对所有用户可见。用户可以便捷的使用公共镜像创建弹性云服务器或裸金属服务器。
私有镜像
私有镜像是用户基于云服务器创建的个人镜像,仅用户自己可见。包含操作系统、预装的公共应用以及用户的私有应用。通过私有镜像创建云服务器,可以节省您重复配置云服务器的时间。私有镜像分为通过云服务器创建的私有镜像和通过外部镜像文件创建的私有镜像。
通过弹性云服务器创建新的私有镜像。
通过注册外部镜像文件创建新的私有镜像。
共享镜像
当用户将自己的私有镜像共享给其他用户使用时,可以使用镜像服务的共享镜像功能。对于多项目用户,共享镜像功能可以方便用户在同一个区域内的多个项目间使用镜像。
当用户作为共享镜像的提供者时,可以共享指定镜像、取消共享镜像、添加或删除镜像的共享租户。当用户作为共享镜像的接受者时,可以选择接受或者拒绝其他用户提供的共享镜像,也可以移除已经接受的共享镜像。
镜像怎么得到的?
镜像根据创建方式分为以下两种:(1)通过弹性云服务器创建并且转为镜像(2)通过外部镜像文件导入进行创建
(10)链接克隆
链接克隆是一种通过将链接克隆母卷和链接克隆差分卷组合映射为一个链接克隆卷,提供给虚拟机使用的技术。其中链接克隆母卷为只读卷,多个链接克隆虚拟机共用一份,链接克隆差分卷是读写卷,其存储是精简配置的,每个链接克隆虚拟机一份,保存了每个虚拟机差异化的数据。链接克隆技术具有创建速度快、占用存储空间小的优点,非常适合于同质化用户、桌面高度标准化场景。
2.内存复用?
作用:当出现竞争时,由内存复用策略为虚拟机实时调度内存资源,综合运用内存复用技术释放虚拟机的空闲内存,为其他虚拟机的内存需求提供条件。
限制条件:
每个计算节点上运行的所有虚拟机的预留内存之和不能大于节点虚拟化域内存总和。
旧版6.1之前:与Guestnuma、inic网卡冲突,Guestnuma、inic网卡会独占内存。与内存复用冲突。
新版6.3之后:内存复用与SRIOV直通、GPU直通、NVME SSD盘直通特性互斥。直通设备的虚拟机必须内存独占,内存独占后虚拟机的内存不会被交换到交换空间。内存复用(非100%内存预留)的虚拟机不能直通设备。
内存共享+写时复制:共享的是相同的数据,别答零页数据了,零页数据虽然也可以,但是不全面。
引申:
内存复用作用的对象是主机还是集群?
集群
虚拟机内存复用比到120:触发告警 150无法创建新的虚拟机。
内存气泡怎么将内存分配给其他虚拟机的?
是通过修改映射关系将内存分配给其他虚拟机的。
内存复用的3项技术可以单独使用某一个吗?
不可以,开启内存复用后,3项技术必须同时使用,不能单独使用。
3.快照
快照是什么?
快照是(虚拟机)某一时刻下数据的一个副本或复制。
ROW(写前重定向):写直接写快照卷,读:先读快照、再读原卷 读性能会有所影响,特别多次快照之后 ,读性能会有较大影响
COW(写前复制):写:假如原位置有数据,先将数据复制到快照卷中,再把新数据写到原卷中。写性能会有较大影响。读,直接读原卷。
全拷贝:将数据完全镜像一份,优点:快照可以不依赖原卷 缺点:十分占用空间
对虚拟机快照:1、虚拟机本身的描述文件2、虚拟磁盘
一致性快照:将内存上的数据先写入到磁盘中再对磁盘打快照
内存快照:直接对内存打快照
引申:
创建快照时,当前磁盘被置为只读,系统自动在磁盘所在数据存储中创建增量磁盘,后续对该磁盘数据的编辑将保存在增量磁盘中,即增量磁盘表示磁盘当前状况和上次执行快照时的状况之间的差异。对该磁盘再次创建快照时,原磁盘和当前增量磁盘均被置为只读,系统会在数据存储中再创建一个增量磁盘。
如果该虚拟机有多个快照,则在删除快照后,该快照内的数据会自动合并到该虚拟机的下一个快照中。
4.虚拟磁盘文件的格式?
固态磁盘文件(普通)
动态磁盘文件(精简&普通延迟置零)
差分磁盘文件(快照、链接克隆)
1、固态磁盘文件:创建时需要将磁盘文件对应的存储块空间全部进行初始化成”0”,
创建的时候,由于需要全部空间都写0,需要消耗较长时间,创建比较慢。但在写数据的时候,可以写数据,IO性能较好
应用在系统中的普通卷。
2、动态磁盘文件:创建时只需写头和结束块
创建的时候,只需要在头和结束块写0,不需要消耗时间,创建比较快,但在写数据的时候,需要先置0,再写数据,相对来说,IO性能较好。当动态磁盘文件使用时间越长,性能也就越接近固态磁盘文件。
应用于精简磁盘和普通延迟置零磁盘。
3、差分磁盘文件:差分磁盘的结构和动态磁盘一模一样,只是文件头中会记录它的父文件路径。
快照、非持久化磁盘、链接克隆等
磁盘的模式:
1、从属:快照中包含该从属磁盘,更改将立即并永久写入磁盘。
2、独立-持久:更改将立即并永久写入磁盘,持久磁盘不受快照影响。
即对虚拟机创建快照时,不对该磁盘的数据进行快照。使用快照还原虚拟机时,不对该磁盘的数据进行还原。
3、独立-非持久:关闭电源或恢复快照后,丢弃对该磁盘的更改。
若选择“独立-持久”或“独立-非持久”,则对虚拟机创建快照时,不对该磁盘的数据进行快照。使用快照还原虚拟机时,不对该磁盘的数据进行还原。
如果快照后,该磁盘被解绑定且未绑定其他虚拟机,则快照恢复的虚拟机会重新绑定该磁盘,但磁盘数据不进行还原。
如果快照后,该磁盘被删除,则快照恢复的虚拟机上不存在该磁盘。
5.非持久化磁盘和持久化磁盘?
存储时非持久化,如内存盘,虚拟机关机后,磁盘恢复到原始状态
持久化数据存储指硬盘等能够持久存储数据的空间,虚拟机关机后,数据还会在
6.模版文件类型?
虚拟机模板格式分为ova和ovf两种。其中ova格式的模板只有一个ova文件。ovf格式的模板由一个ovf文件和多个vhd文件组成,规则如下:
ovf文件:虚拟机的描述文件,文件名为导出模版时设置的文件名,如“template01.ovf”。
vhd文件:虚拟机的磁盘文件,每个磁盘生成一个vhd文件(虚拟机的磁盘不算,在FC中看到的一个磁盘才算一个Vhd),文件名为:“模版名称-磁盘标识.vhd”,如“template01-sdad.vhd”。
7.两VM不通?
虚拟机侧:
虚拟机故障或者网卡故障。
同网段:1.虚拟机的操作系统的防火墙拦截。
2.IP地址或掩码配置有误(假如A:192.168.1.1/23 B:192.168.1.2/24 A ping B,A会认为B与自己同网段, B收到A的arp消息,通过子网掩码去匹配发现A与其不同网段,则发给网关。
不同网段:1.网关配置错误。
中间系统
1.同一主机、同一DVS、同一二层,不同端口组,也就是虚拟机1和2不通:端口组VLAN配置错误。
2. 不同主机、同一DVS、同一二层,同一端口组,也就是虚拟机1和3不通:TOR交换机可能未放行相应的VLAN、或者PVID配置错误。
3.同一主机、同一DVS、不同二层,同一端口组,也就是虚拟机1和2不通:TOR交换机可能未放行相应的VLAN、或者PVID配置错误(VM和TOR交换机pvid一定要不一致)、ACL策略拦截、网关配置错误、网关无法路由或这被路由器拦截。
4.不同主机、不同DVS,也就是虚拟机1和4不通:由于不同DVS分别属于不同的物理网络,所以虚拟机1和4天然不通。
5.对虚拟机配置了安全组,并被安全组策略拦截(安全组功能由虚拟机所在主机的 iptables
实现)
故障排错:
虚拟机1和2不通举例
二层情况下:ping目标VM,不通
查看arp表(不ping是因为刚ping完),如果有arp条目,则被可能被防火墙或第三方软件拦截。如果不存在,则说明时二层问题。
三层情况下:在源目查看arp表是否存在各自的网关,如果不存在,则是本端二层有问题
存在的话,各自ping下自己的网关看看是否能通,不能通还是二层问题,通的话,再ping对端VM的网关,通则可能被防火墙或第三方软件(为什么要ping网关,因为可能arp条目老化时间到了,ping是为了让arp重新有网关条目)。
如果在不同路由器下,则可能是路由问题,用tracert
二层问题:
检查虚拟机网口配置,查看连接的端口组
看是否在同一CAN主机,不在看条件是否允许迁移至同一主机,如果通,则可能是物理网络配置问题(到交换机上检查是否允许VLAN通过)
可以在不同DVS上划分相同的VLAN,因为两个不同物理网络的VLAN可以相同,这是两个不同的二层。
引申:为什么虚拟机1和2会单通?
可能是虚拟机1开了防火墙,虚拟机2关闭了,导致单通。或者是安全组拦截了。或者是物理交换机设置了ACL策略。
虚拟机不通快速定位?
比如VM1和VM3不通快速定位,首先我们将VM3迁移致CNA01中,然后去ping,如果能通,那么是tor交换机的问题,如果不通就是DVS的问题。
中继场景下,同一个ip网段的虚拟机但是不同vlan能不能只通过中继这个端口组通信?
不能。
8.华为存储资源模型
1、存储资源表示物理存储设备,告诉FC,需要添加存储叫什么名字,是什么类型,在哪里。例如IPSAN、Advanced SAN、NAS、FS等。
2、存储设备表示存储资源中的管理单元,类似ipsan(LUN)、 Advanced SAN、FS(存储池)、NAS(共享目录)等。本地磁盘
3、数据存储表示虚拟化平台中可管理、操作的存储逻辑单元。虚拟化的数据存储,裸设备映射,(旧版本还有非虚拟化数据存储)
由于裸设备映射、非虚拟化数据存储同样都不支持虚拟化特性,裸设备映射性能更好,所在6.3.1版本以后,把非虚拟化数据存储删除了。
9.存储虚拟化
1、裸设备+逻辑卷 非虚拟化数据存储 性能较好
2、主机存储虚拟化+文件系统 虚拟化数据存储 san(vims) 本地磁盘(ext4) nas(nfs)性能较差,应用于快照、链接克隆、精简配置等
3、存储设备虚拟化 Fusionstorage、advance san
10.FS\Advan SAN 与虚拟化数据存储的对比?
1、同样都支持虚拟化特性
2、FS虚拟化特性依赖DHT算法
3、FS是一种存储能力卸载的设备
存储能力卸载?
将原本需要CNA主机参与的动作,卸载交给FS、advsan自己实现。节省CNA主机的CPU。
11.如何给一个FC添加一个数据存储?
1、在FC上,添加存储资源(名字、类型、IP)
2、在存储侧创建lun,创建lun
创建主机,创建主组 添加映射关系
3、在FC上,存储资源,关联主机
4、在FC上,扫描存储设备,会扫出前面所映射单元
5、在FC上,把存储设备添加为数据存储。(虚拟化、非虚拟化、裸设备映射)
12.热迁移需要Tools吗?
新版FC热迁移不需要tools,6.5中不再需要。kvm本身可以实现。
13.HA?
解释:当一台主机或者虚拟机发生故障的时候,系统将会在资源池内启动一台虚拟机到其他可用的物理主机上。
原理:VRM或者集群的Master节点检测到某计算节点故障或者虚拟机故障,主动根据自身记录的虚拟机信息,在正常的节点上重新启动故障虚拟机,同时,存储层面的锁机制防止在多个节点上启动虚拟机。
怎么触发HA?
1.主机发生宕机、上下电、重启的时候
2.虚拟机系统放生故障的时候:window蓝屏、Linux Panic
3.CAN与VRM心跳中断30秒的时候
4.系统故障检测,通过在主机之间实行网络心跳检测,发现没有主机与虚拟机没有IO行为的时候触发HA(整个行为与VRM无关)
预留方案
HA 资源预留:在整个集群内按照配置的值预留 CPU 与内存资源,该资源仅用于虚拟机 HA 功能使用。
使用故障专用切换主机:预留故障专用切换主机,平时该主机不对外提供业务。
集群允许主机故障设置:设置集群内允许指定数目的主机发生故障,系统定期检查集群内是否留有足够的资源来对这些主机上的虚拟机进行故障切换。
条件:
1.安装Tools(实验证明,没有tools也能HA)。且正常运行;2.其他主机有预留HA资源,不能处于维护模式;3.共享磁盘;4.VM不能绑定主机,USB设备和GPU;5.集群开启HA功能。
整个HA过程数据会丢失吗?
会,会丢失未落盘的数据。
14.什么是端口组?
一组类型相同的虚拟端口的集合。一般与虚拟机连接。 类型(比如网络属性(vlan qos)等等)
引申:端口组和VLAN的比列关系?
一个DVS下,端口组和VLAN可以是1:1,也可以是1:m
多个DVS下,端口组可以复用,那么比列就是m:n
15.服务器虚拟化
6.3.1的FC:
华为FusionSphere是业界领先的服务器虚拟化解决方案,能够帮助客户带来如下的价值,从而大幅提升数据中心基础设施的效率。
帮助客户提升数据中心基础设施的资源利用率。
帮助客户成倍缩短业务上线周期。
帮助客户成倍降低数据中心能耗。
利用虚拟化基础设施的高可用和强恢复能力,实现业务快速自动化故障恢复,降低数据中心成本和增加系统应用的正常运行时间。
应用场景介绍:
单虚拟化场景:
单虚拟化场景适用于企业只采用FusionCompute作为统一的操作维护管理平台对整个系统进行操作与维护的应用场景。包含资源监控、资源管理、系统管理等。
FusionCompute主要负责硬件资源的虚拟化,以及对虚拟资源、业务资源、用户资源的集中管理。它采用虚拟计算、虚拟存储、虚拟网络等技术,完成计算资源、存储资源、网络资源的虚拟化。同时通过统一的接口,对这些虚拟资源进行集中调度和管理,从而降低业务的运行成本,保证系统的安全性和可靠性。
多虚拟化场景:
多虚拟化场景适用于企业有多套虚拟化环境需要进行统一管理。多虚拟化场景提供如下主要功能:
统一管理和维护:支持同时接入FusionCompute和VMware虚拟化环境,对多虚拟化环境的资源和业务进行统一的管理和维护。
统一监控告警:支持对多个虚拟化环境、多种物理设备的告警进行统一接入、监控和管理。
FusionCompute各模块功能:
CNA主要提供以下功能:
CAN:提供虚拟计算功能。
管理计算节点上的虚拟机。
管理计算节点上的计算、存储、网络资源。
VRM主要提供以下功能:
管理集群内的块存储资源。
通过DHCP(Dynamic Host Configuration Protocol)为虚拟机分配私有IP地址。
管理集群内的网络资源(IP/VLAN/DHCP),为虚拟机分配IP地址。
管理集群内虚拟机的生命周期以及虚拟机在计算节点上的分布和迁移。
管理集群内资源的动态调整。
通过对虚拟资源、用户数据的统一管理,对外提供弹性计算、存储、IP等服务。
通过提供统一的操作维护管理接口,操作维护人员通过WebUI远程访问FusionCompute对整个系统进行操作维护,包含资源管理、资源监控、资源报表等。
FusionSphere逻辑架构:
FusionCompute:
必选部件
FusionCompute是云操作系统软件,主要负责硬件资源的虚拟化,以及对虚拟资源、业务资源、用户资源的集中管理。它采用虚拟计算、虚拟存储、虚拟网络等技术,完成计算资源、存储资源、网络资源的虚拟化。同时通过统一的接口,对这些虚拟资源进行集中调度和管理,从而降低业务的运行成本,保证系统的安全性和可靠性,协助运营商和企业构筑安全、绿色、节能的云数据中心能力。
FusionManager:
可选部件
FusionManager主要对云计算的软件和硬件进行全面的监控和管理,实现同构,异构VMware虚拟化多资源池管理;软硬件统一告警监控;自助服务及流程审批三大关键能力,并向内部运维管理人员提供运营与管理门户。
FusionSphere eSDK:
可选部件
FusionSphere eSDK是FusionSphere服务器虚拟化北向统一接口,第三方网关系统和其他运营平台可以通过eSDK轻松完成无缝对接。eSDK开放了FusionSphere服务器虚拟化的全部能力,包括虚拟机的生命周期管理,虚拟化高级功能,运维管理功能等。
eBackup:
可选部件
eBackup是虚拟化备份软件,配合FusionCompute快照功能和CBT(Changed Block Tracking)备份功能实现FusionSphere的虚拟机数据备份方案。
新版6.5的FC(考试以新版为准,不要说老版本的)
FusionCompute
必选部件
FusionCompute是云操作系统软件,主要负责硬件资源的虚拟化,以及对虚拟资源、业务资源、用户资源的集中管理。它采用虚拟计算、虚拟存储、虚拟网络等技术,完成计算资源、存储资源、网络资源的虚拟化。同时通过统一的接口,对这些虚拟资源进行集中调度和管理,从而降低业务的运行成本,保证系统的安全性和可靠性,协助运营商和企业构筑安全、绿色、节能的云数据中心能力。
FusionManager
可选部件
FusionManager主要对云计算的软件和硬件进行全面的监控和管理,实现同构,异构VMware虚拟化多资源池管理,软硬件统一告警监控,并向内部运维管理人员提供管理门户。
eBackup
可选部件
eBackup是虚拟化备份软件,配合FusionCompute快照功能和CBT(Changed Block Tracking)备份功能实现FusionSphere的虚拟机数据备份方案。
UltraVR
可选部件
UltraVR是容灾业务管理软件,利用底层SAN存储系统提供的异步远程复制特性,提供虚拟机关键数据的数据保护和容灾恢复。
16.内存分片+迭代迁移?
一开始对数据定格,新数据写入带新空间,把原来定格的数据传送到对端,在传送对端的过程中新产生的数据再进行定格,再一次发送,发送后又产生新数据,不断迭代,最后当新产生的数据量极少时,此时暂停源虚拟机,在一个极短的瞬间内,把剩下的数据发送给对端。
17.存储热迁移?
- 规则的调度优先级?
第一优先级:规则类型为“虚拟机到主机”,规则是“必须在主机组上运行”和“禁止在主机组上运行”的。
第二优先级:规则类型为“聚集虚拟机”和“互斥虚拟机”的。
第三优先级:规则类型为“虚拟机到主机”,规则是“应该在主机组上运行”和“不应该在主机组上运行”的。
19.热迁移中什么时候在对端创建虚拟机?
热迁移中,当虚拟机的设备信息和配置信息发送给对端后,才开始创建虚拟机
引申:绑定硬件设备为什么不能迁移?
迁移后对端没有设备
二:FusionStoage
1.数量问题
一个存储池中,2副本最多288个硬盘对应288个OSD,3副本最多2048个硬盘对应2048个OSD。
ZK最少3个,最多7个
MDC最大96个,控制MDC最少3个,归属MDC最多93个,控制MDC最多7个,那么归属MDC最多89个。一个归属MDC最多接管2个存储池。
控制MDC最少需要几个可以维持工作?
最少一个
一个归属MDC可以最多管理多少个OSD?
288×2个或者2048x2
存储池最大128个。
VBS最多4096个。
每个服务器上有 3 个~36 个硬盘可供 FusionStorage 使用(包含独立部署的元数据盘)。
两副本时,每个服务器上提供给每个存储池使用的硬盘数量为 2 个~12 个。
三副本时,每个服务器上提供给每个存储池使用的硬盘数量为 2 个~36 个。
每个存储池中的硬盘数量不能少于 12 个。
同一个资源池中的存储节点上硬盘数量之差不能大于 2 块。(此处所指的硬盘为加入该存储池的硬盘,而不是服务器上所能提供的硬盘总数。)
同一个资源池中的存储节点上缓存的数量必须一致
同一个资源池中的存储节点上缓存的类型必须一致
2.什么是分布式chace?
io发送给vbs后,先进行分片,再经过dht算法,每个分片最终会均匀落到多个存储节点的cache中。
3.FusionStorage可靠性
1、fsm主备部署,zk形成集群关系和多活,mdc、vbs形成集群主备关系
2、数据可靠性:2副本/3副本,通过强一致性保障数据一致
3、安全级别:服务器级别,机柜级别,机房级别
4、掉电保护介质:掉电保护、非易失性介质保存cache
4.FS组件交互流程?
先部署ZK,一个系统需部署 3、5、7 等奇数个 ZK组成ZK集群,为MDC集群提供选主仲裁机制,Zookeeper至少3个,必须保证大于总数一半的Zookeeper处在活跃可访问状态。且ZK集群有一个主ZK。
再部署MDC,系统启动时,MDC与ZK互动决定主MDC(谁先注册谁为主),当主MDC故障后,其它MDC发现主MDC故障又与ZK互动升任主MDC。
创建存储池,OSD启动时向主MDC查询归属MDC,主MDC告知OSD谁是他的归属MDC,OSD知道自己的归属MDC后向归属MDC报告状态并且维持心跳关系。归属 MDC把状态变化发送给VBS。
最后创建VBS,VBS启动时查询主MDC,向主MDC 注册(主 MDC 维护了一个活动 VBS 的列表,主MDC同步VBS列表到其它 MDC,以便MDC能将OSD的状态变化通知到VBS),向 MDC 确认自己是否为 leader,所有VBS 从主MDC获取IO View,主VBS向OSD获取卷元数据,其它VBS向主VBS获取卷元数据。
5.VBS如何找到主MDC进行注册?
VBS配置文件中会有所有MDC的ip地址,控制节点MDC序号在所有MDC序号的最前面。
引申:主MDC故障,由备MDC重新选择出一个主MDC,备MDC故障时,不做任何处理。
归属MDC故障的话,控制MDC不会接管,由主MDC指定另一个MDC接管。
OSD如何找到归属 MDC?
OSD进程在启动时会加载相应配置文件,文件中,包含所有MDC的IP及端口号,所以OSD 可以向这些MDC确定归属MDC。
6.MDC部署在哪?
控制MDC部署在控制节点,归属MDC部署在存储节点。
为什么归属MDC需要部署在存储节点?
归属MDC需要对归属存储管理
引申:当只有3台服务器时,那么只有3个控制MDC,且控制MDC充当归属MDC。
归属MDC的作用:存储池的创建和元数据的管理
7.为什么的ESXI需要安装CVM虚拟机?
因为FSA是基于RPM包进行安装的,而CVM虚拟机是要是一台Linux操作系统的虚拟机就行,目前提供的兼容性列表有CentOS、RedHat、Oracle Linux、SUSE、
EulerOS
引申:为什么每台ESXI主机都要部署一个CVM虚拟机?
性能损耗上,SCSI在内部消耗,损耗较低,ISCSI承载在IP网络上,时延和损耗较大,为提高性能,尽可能减少封装解封在和时延的损耗。通过在每台ESXI上部署一个CVM虚拟机缩短IO路径,提供性能。
8.FusionStorage 对比传统存储有哪些缺点?
1.通常,FusionStorage 的时延高于传统,所以不适合于核心系统,例如 OLTP 业务(采用 IP 网络、廉价存储介质、多级存储路径、DHT算法等原因)
2.FusionStorage目前不像某些传统存储(例如华为的统一存储)同时提供文件存储、对象存储服务(慎答,因为FS8.0可以同时提供了,但是华为还没有发出产品)
3.FusionStoage 至少三点节起步,并且在节点数据达到一定规模后性能才能赶上传统存储
4.小规模场景,FusionStorage 的实施比传统存储复杂许多
5.FS的磁盘利用率比较低,没有传统存储磁盘的利用率高。
9.FusionStorage 对比传统存储有什么优势?
传统存储 FusionStorage
机头瓶颈:双控~16 控,且无法线性扩展 分布式控制器,可线性扩展至 4096 节点
元数据服务集中于机头,易出现性能瓶项 元数据服务由分布式控制器提供
IO 集中于有限的机头,易出现 IO 瓶颈 IO 由无状态的分布式软件机头提供
Cache 瓶颈:通常为 GB 分布式 Cache,扩展至 TB 级
传统存储资源缺乏共享,不易管理 数据中心级资源共享和统一管理
性价比:成本随性能提升大幅增加;存储更新换代速度快 支持融合部署,通用 X86 服务器堆叠扩展,节约成本;网络扁平化,扩容简单;既有设备利旧,保护投资
1、机头
1)传统存储支持双控~16控
2)Fusionstorage采用分布式软件机头,可以线性扩展至4096个
引申:
为什么传统存储最大16控?
控制器和控制器间需要形成集群关系,同步信息(如管理数据),关系的维护需要消耗cpu和内存实现,控制器越多消耗的资源越多,再往上加的话,性价比不高。
为什么我的分布式软件机头最大4096个?
主VBS存在性能上瓶颈,因为VBS之间需要同步信息。
VBS集群为什么会有主的VBS?
原因在于解决多 VBS 对同一卷元数据的一致性操作上,FS中如果多个VBS同时操作元数据卷,会引起数据数被写坏等问题,为了防止数据被写坏的问题,所以只有主VBS能够操作元数据,备的VBS不允许对数据进行操作。
2、元数据
1)传统存储中LUN的元数据存放在归属控制器上,访问该LUN时,需要先访问元数据,当LUN较多时,归属控制器需要维护的元数据也较多,并发性性访问时,会存在性能瓶颈。
2)FusionStorage元数据分2部分,试图存放在ZK中,卷的元数据被打散存放在相应资源池的所有存储中。
元数据通过VBS中的DHT算法去计算得到。所以没有性能瓶颈。
引申:DHT为什么要hash?
为了实现负载均衡,使得数据可以分布在各个节点上。
3、IO
1)传统存储访问某个LUN时,需要先访问该LUN的归属控制器,归属控制器存在IO瓶颈。
2)因为VBS是无状态机头,状态信息由管理层面保存并且同步记录(MDC),VBS只要维持管理卷的元数据就行。(处理请求时不会依赖上一次的请求,每次通过DHT计算得到的,所以是无状态的)。它与传统存储不同,指定LUN没有指定的控制器问题,业务到达VBS后,各自有对应的VBS,这种情况下,就不存在IO瓶颈问题。
数据打散存放,不存在IO性能瓶颈。
4、缓存
1)传统存储提供GB级别的缓存,V3存储采用SmartCache特性,读缓存可以达到TB级别,传统存储cache由机头提供。(cache有内存和ssd盘,只有读cache。SSD不给写,因为SSD有擦写次数,如果写操作过多,会影响寿命。)
2)fusionstorage采用分布式智能缓存技术,由多个节点同时提供,可以提供TB级别的缓存
5、管理
1)传统存储缺乏资源共享,不易管理
在数据中心场景下,软硬件紧耦合(买了他的硬件,里面就自带了他的软件),拥有多套存储系统的情况下,没办法将多套存储系统融合在一起(原来的存储系统已经上线了业务,如果要合并可能会影响生产业务),他们各自都带了自己的管理软件,需要分别的管理的。
2)fusionstorage是数据中心级别的资源共享,支持统一管理
软硬件解耦,可以使用一套软件管理多个存储池。且可以管理有差异硬件的存储节点。
6、性价比
1)传统存储成本随性能提升成本大幅提升,性价比不高
2)fusionstorage部署在通用的X86上,计算和存储线性扩展,实现投资保护和设备保护
引申:什么是线性扩展?
是即能够增加存储空间,又能够提高存储性能的。
10.安装FS时要不配置RAID?
FS本身不需要做RAID,某些RAID卡型号不能够认识硬盘(3108、2208),需要对硬盘做单盘的RAID0。
11.除了3种视图外,还有吗?
还有VBS view,VBS view存放的是VBS的状态和VBS ID,与OSD view类似。
12.FS有哪些组件?
ZK:开源的分布式应用协调系统
作用:
1)统一命名服务
2)状态同步服务
3)集群管理
4)分布式应用配置项的管理等工作
MDC:元数据控制器
作用:
1)集群状态监控
2)控制数据分布式规则
3)数据重建规则
引申:数据重建规则:通过视图+DHT算法 分布式集群状态监控:VBS启动时向MDC注册,会向MDC汇报信息。
VBS:虚拟块存储管理组件
作用:
1)卷的元数据管理
2)对外提供标准的SCSI和ISCSI接口,提供接入点服务
OSD:对象存储设备管理服务
作用:
1)执行具体的IO
2)收集磁盘信息
13.为什么传统存储可靠性比fusionstorage要高:
1)传统存储使用raid2.0+技术,有热备空间
2)硬件上有2~16控,16控,每4个做一个控制框,可以做到4坏3
3)多路径
14.为什么ZK需要357部署?
部署1个ZK,无法保障可靠性,易出现单点故障
部署2个ZK,当一个ZK出现故障后,无法满足选举过半机制,导致另一个ZK也不可使用,和部署1个ZK的可靠性无差异
部署3个ZK,当一个ZK出现故障后,剩余的2个ZK任然满足过半选举机制,可以正常对外提供服务
部署4个ZK,也只能够坏1个ZK,坏2个ZK不满足过半选举机制
控制节点到达7节点后,可靠性完全得到保证,再增加ZK,ZK间交互的流量过多,需要消耗过多的资源,导致性能下降
引申:为什么控制MDC需要3、5、7部署?
是因为部署多个MDC的话会有主备问题,所以引入zk决定MDC谁是主的,所以到了ZK为什么3、5、7去部署。
ZK和MDC之间管理的数据是不是不一样,为啥要用ZK又要有MDC?
MDC是zk的client端,zk是server端,MDC就是将元数据提交给ZK进行保存。
(zk提供接口负责元数据存储,MDC负责管理元数据)
15.FS中的VBS组件介绍?
VBM模块负责完成卷和快照的管理功能:创建卷、挂载卷、卸载卷、查询卷、删除
卷、创建快照、删除快照、基于快照创建卷等。
SCSI模块负责从内核(VSC.KO)中将IO引入VBS进程,SCSI模块接收到的IO是标
准SCSI协议格式的IO请求,SCSI模块将收到的IO信息交给VBP(Virtual Block Process)模块,VBP内部将通用块格式的IO(SCSI)转换为FusionStorage内部Key-Value格式的IO下发给client。(看完这个看下面的)。
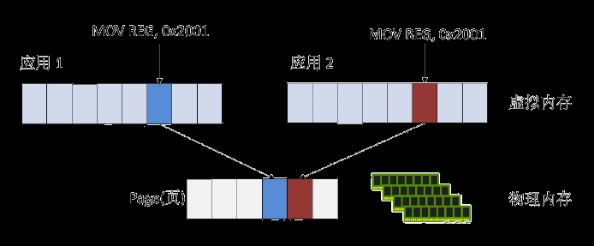
FusionStorage块存储会对每个LUN在逻辑上按照1MB大小进行切片,例如1GB的LUN 则会被切成 1024*1MB 分片(VBP做的)。当上层应用访问 FusionStorage时,在 SCSI 命令中会带上 LUN ID 和 LBA ID 以及读写的数据内容,系统转发该消息到本节点VBS模块,VBS根据 LUN ID 和 LBA ID 组成一个 key,该 key 会包含 LBA ID对1MB的取整计算信息。然后交给Client通过 DHT(先hash(哈希)后取模得到Partition ID)计算出一个整数(范围在 0~2^32 内),并落在指定 Partition中,根据内存中记录的“分区-硬盘(IO View)”映射关系确定具体硬盘,VBS将IO操作转发到该硬盘所属的OSD模块。
每个OSD会管理一个硬盘,系统初始化时,OSD会按照1MB为单位对硬盘进行分片管理,并在硬盘的元数据管理区域记录每个1MB分片的分配信息。OSD接收到VBS发送的IO操作后,根据key查找该数据在硬盘上的具体分片信息,获取数据后返回给VBS,从而完成整个数据路由过程。主的OSD如果读不到,则进行DHT算法,从备OSD读取,并进行数据修复。对于副本写请求,OSD根据分区-主磁盘-备磁盘1-备磁盘 2(Partition View)映射表,通知各备OSD进行写操作,主与备OSD都完成写后返回VBS。
引申:切片:第一次在key-value之前按照1M大小进行切片,第二次在硬盘进行切片,按照1M大小进行切片。
切片后的数据一定会在我们的硬盘中存满1M吗?
不一定。
16.FS中的OSD组件介绍?
OSD:主备模式,MDC实时监控OSD的状态,当指定Partition所在的主OSD故障时,存储服务会实时自动切换到备OSD,保证了业务的连续性。
RSM:复制协议实现。
SNAP:实现卷与快照的IO功能、磁盘空间的管理。
CACHE:实现cache功能。
AIO:实现异步IO下发到底层SMIO模块和通过调用SMIO接口来监控介质故障。
SMIO:下发到IO到实际的物理介质、监控物理介质故障、获取磁盘信息。
17.IO流程?
详细版:VBS 收到 SCSI 指令流—>VBS 会转换成为 key-value 形式—>VBS 对 LUNID+LBAID 进行 hash,得到 hash 值—>VBS 对 hash 值进行取模运算得到 partition 号—>VBS 将 partition 号检索 IO view,得到 OSD。
简略版:OS —SCSI/iSCSI—>VBS—“key-value”—>OSD—SCSI—>disk
APP 下发读 IO 请求到 OS,OS 转发该 IO 请求到本服务器的 VBS 模块;VBS 根据读 IO 信息中的 LUN 和 LBA 信息,通过数据路由机制确定数据所在的 Primary OSD;如果此时 Primary OSD 故障,VBS 会选择 secondary OSD 读取所需数据。
引申:读cache是通过什么技术?
内存:LRU队首机制
读磁盘的cache:热点访问因子
18.windows使用iscsi有什么缺点?
iscsi启动器,向iscsi目标器发起iscsi连接,一对一发起连接,不能够并发处理IO。
winodw使用iscsi会把流量发给其他节点,会有物理网络瓶颈。
19.如何保障iscsi的可靠(安全)性?
在FSM中配置chap认证。
20.分布式机头?
FusionStorage 块存储采用无状态的分布式软件机头,机头部署在各个节点上,无集中式机头的性能瓶颈。单个节点上软件机头只占用较少的CPU资源,提供比集中式机头更高的IOPS和吞吐量。例如:假设系统中有 20 台节点需要访问 FusionStorage 提供的存储资源,每台节点提供给存储平面的带宽为 210Gb,我们在每台节点中部署 1个 VBS 模块(相当于在每台节点中部署1个存储机头),20 台节点意味着可部署 20个存储机头,所能获取到的总吞吐量最高可达 202*10Gb=400Gb,随着集群规模的不断扩大,可以线性增加的存储机头,突破了传统的双控或者多控存储系统集中式机头的性能瓶颈。
21.FusionStorage 块存储采用的 DHT 算法有什么特点?
均衡性:数据能够尽可能分布到所有的节点中,这样可以使得所有节点负载均衡。
单调性:当有新节点加入系统中,系统会重新做数据分配,数据迁移仅涉及新增节点,现有节点上的数据不需要做很大调整。
22.FusionStorage有哪些网络平面?并说明作用
管理平面:用于 FSM 与 FSA 之间的通信
存储平面:用于 MDC、VBS、OSD、ZK 之间通信
业务平面:用于 OS 与 VBS 之间通信
23.业务都是怎么使用FS存储的?
都是通过挂载卷的方式使用FS提供的存储空间,挂载方式不同:
VBS可以安装在生产主机中时,使用 SCSI方式挂载卷。
VBS不可以安装在生产主机时,使用 iSCSI方式挂载卷。
SCSI:生产站点上安装VBS,通过VBS提供的SCSI传输数据,FSM上创建卷,通过SCSI挂载。
ISCSI:在FSM界面上定义主机的iqn启动器(多台主机使用同一存储池中的不同LUN,启动器用来区别分开主机),创建主机与之关联,并且创建卷,使用ISCSI的方式,主机端发起ISCSI连接,建立会话,扫描存储设备,添加数据存储。
引申:FC和vmvare分别适用什么方式?
FC:SCSI、iSCSI
VMware:iSCSI
24.针对部分业务,为什么客户会偏向使用传统存储?
部分业务可能是一些小规模场景;
- 传统存储具有部署简单,上线快等优点;
- 传统存储安装调试简单;
- 一些核心关键业务需要传统存储,保证最低延迟,高iops
- 传统存储支持许多高级特性
- FS初始投资高
25.单个OSD故障?如何修复?
1.被提出:用户没有任何操作,超过5分钟。进行多点到多点的修复。(MDC5秒内没有收到OSD心跳信息的话,则更新视图并且将进行视图引流。)
2.被踢出:用户更换一块新盘。没有超过5分钟,多点到单点的修复。超过5分钟,相当于扩容
3.被踢出:修好盘后或本身硬盘没有故障,重新添加会存储池。
26.如何向客户推荐FS?
27.FS对接Vmware使用时,是否有SCSI流量?
vm到esxi走scsi esxi到cvm中的vbs走iscsi vbs到osd走k-v osd找disk走scsi
28.FC使用FS用ISCSI时为什么不能打快照?
因为我的FS使用ISCSI的话,那么就是以IP SAN的方式给CAN主机使用,我的CAN主机就会认为这是一个IP SAN存储,那么快照动作就会由CAN主机去做,但是我实际是FS,FS的快照动作是由FSM通知VBS去做的,可是我FC接管FS时使用IP SAN的方式,所以这就会造成一个冲突,所以FS以ISCSI使用时就不能打快照。
29.卷元数据存在哪里?
存在存储池中。因为我们的卷元数据就是在OSD中,而存储池就是由OSD组成的。
30.读cache中为什么需要从写cache中读取数据?
因为我的数据可能还在写chche中,并没有落盘。
31.zk为什么要3个?可以4个吗?如果一定要4个可以部署吗?在哪选择?
4个盘,3个zk盘1个zk分区,不能选择4个zk。
32.EC?
ec和副本互斥,4节点,根据文件大小切成n片,m个校验位。允许坏多个校验位。
具体的介绍可以看华为的OceanStor的存储文档。
33.FS安装部署
安装FSM虚拟机
使用FusionStorage_install软件将主备fsm形成集群,并配置浮动IP
通过配置的浮动IP登录FS Portal,添加接入服务器(需要先给服务器安装OS,可以批量添加也可以一台一台添加)
给服务器安装FSA,点击一下就自动安装了
如果在FC里装FSA,那么要在FC界面里给划分存储接口给FS使用
创建控制集群(默认3、可选5、7)这里有几个参数注意一下,是根据存储网段还是根据存储网口接入,选择是zk盘还是zk分区,分区的话是安装OS的时候划分出来的
创建存储池,这里有个主存缓存比,是需要计算的,可以选择EC、副本机制保证可靠性,可选机柜、服务器级,机房级(隐藏),然后选择主存类型和缓存类型,如果主存使用SATA必须3副本,必须有缓存,SSD就没要求。
选择存储服务器加入存储池
给计算节点安装VBS,这里没什么需要注意的,直接选择安装就行了。
三:容灾解决方案
1.双活中没有双活管理模块能不能同时对外提供工作?
不能,这样会发生脑裂问题。
引申:什么是脑裂
如果两个阵列之间没有相互协商,且同时对外提供工作,左右两端业务分别写各自本地存储空间时,可能写在相同的存储位置,在进行远程同步时不知道具体同步哪一份数据。
2.生产存储故障时会自动切换到灾备存储上吗?
主备存储无法自动切换:无协调机制,需要手动切换(无锁机制,易出现脑列问题)
双活存储可以自动切换:静态优先级和第三方仲裁机制,实现自动切换
关于仲裁机制原理推荐看存储文档。
引申:基于主机复制容灾,生产端会打快照吗?
不会,因为IO的流动是通过IOmirror来完成的,IOmirror不需要快照技术去提供支持。虚拟机热迁移中的完整迁移,存储也是没有打快照的。但是会对对端打快照(也就是占为虚拟机),防止出现数据不可用的场景
3.为什么要对占为虚拟机创建快照?
因为在复制数据到占为虚拟机时,防止数据写坏,所以需要打快照以便于恢复。
4.什么是两地三中心?
两地三中心容灾解决方案通过建立同城灾备中心和异地灾备中心,实现对生产数据及业务的多重保护。当生产中心发生灾难时,业务快速切换到同城灾备中心。当生产中心和同城灾备中心同时发生灾难时,也可以在异地灾备中心利用数据副本恢复生产业务,从而最大程度保障业务连续性。
5.本地高可用解决方案概念
本地高可用解决方案在生产业务系统通过主机集群、网络双交换和存储镜像等方式提高存储、数据、网络、服务器甚至应用的整个IT系统可用性。采用冗余部署方式后,当设备故障时,不影响业务连续访问。
6.两地三中心中级联和并联有什么优缺点?
级联组网:
优势:对生产中心性能影响小。劣势:当发生区域性灾难时,如果同城灾备中心完全受损,系统RPO将较大(具体值需参考异步复制周期的大小)。
并联组网:
优势:当发生区域性灾难时,能有效避免级联组网的不足,系统RPO将较小。劣势:对生产中心的性能要求较高且影响大。
7.本地高可用与双活数据数据中心的区别?
1、本地高可用:保护范围是同个数据中心内2个系统或者2个机架。双活数据中心:保护的是同城的2个数据中心,当一个数据中心故障,另一个数据中心继续提供业务。
2、本地高可用使用SmartVirtualization+HyperMirror实现,双活不可以。
3、双活需要考虑安全层、传输层等层次的双活,而本地高可用不需要考虑。
4. 本地高可用使用HyperMetro时,多路径IO选择配置负载均衡,而双活配置本地站点优先
8.双活数据中心每一层都需要实现双活吗?
不需要每层都要实现双活。 双活的定义是指两数据中心同时可以对外提供业务。 因此对业务而言可以通过主备的方式,也可以双活的部署方式。但是存储层要双活,因为要保障数据实时的同步,并且还要同时对外提供业务。
9.容灾使用远程复制时的名词解释
RM:远程复制管理模块。
LOG:记录数据写入操作的日志。
DCL:Data change log,数据变化位图。
10.计算层怎么实现双活?
计算层做集群。
计算层:跨数据中心集群HA:并不是完全不中断,而是让2个DC同时提升业务,完成自动切换。
引申:网络层的追问:
GSLB(当一个数据中心故障时,通过DNS解析来去另一个数据中心) slb(主要针对前端应用进行负载均衡的,比如web)
GSLB是硬件部署。SLB也是
计算层为什么做集群?
因为我们要实现HA(实现高可用)和DRS(负载均衡)
那么我计算层不做集群怎么实现双活?
那就由我的应用来实现双活。
11.怎么向客户推荐双活数据中心?(和主备方案对比)
1、双活数据中心同时对外提供业务,相比主备数据中心,另一个数据中心也提供业务,提高资源利用率。
2、双活能够实现数据0丢失,业务自动切换,主备数据中心无法做到,因为主备只能由管理员手动切换,所以可以得出双活的RTO比主备更小。
主备的问题:静态数据(写入到磁盘中数据)不丢失,动态数据可能会丢失,比如在数据同步远程复制的数据时可能丢失。
3、双活能够实现6层双活,相比于主备容灾,能够容忍任意一次故障。
4、双活本地负载均衡和站点间数据负载均衡,而主备无法实现。
5、双活和主备对比中,rto的双活比主备小,因为双活是主动切换,主备是认为切换
12.主机复制和存储复制有什么不同?
1、实现方式:
主机复制利用fusioncompute的IO镜像功能实现(VRG)
存储复制利用存储设备的远程复制功能
2、应用场景:
主机复制面向非关键性业务
存储复制面向关键性业务
3、RPO:
主机复制采用异步远程复制,RPO大于0(异步是指VRG周期性的将数据传输到远端站点)
存储复制RPO等于0
4、距离不同:
主机复制有距离的限制
存储复制距离支持更远
5、主机复制需要消耗计算资源
存储复制利用自身的远程复制特性实现,不消耗计算资源
6、保护对象:
主机复制保护对象为虚拟机
存储复制保护对象为LUN
13.10台VM部署在10个LUN当中,如何实现容灾?
在华为针对虚拟化平台的容灾方案中,选择主机复制容灾,针对的对象是虚拟机,主机复制容灾的精度可以做得更高一些。
引申:这10个LUN中有可能存在不需要保护的VM,怎么办?
利用FC的存储热迁移技术把数据迁移到其他存储中。
14.主机层复制,存储层复制之间的区别
1对存储设备要求不同,存储层复制要求生产站点和容灾站点存储设备同为华为SAN存储,且为虚拟化存储。主机复制容灾要求虚拟化数据存储就行。
2保护单位不同:存储层复制保护最小单位为LUN,主机复制保护最小单位是VM或者vdisk
3原理上的区别:存储层复制可以实现同步,异步远层复制;主机层复制只能是异步复制。
4场景上的区别:主机复制层只能是Fusionspere,存储层复制没有限制,但推荐被保护的为私有云场景下的虚拟机。
5 BCM是否要接管存储设备:主机层复制是不需要,存储层复制是需要。
15.存储复制容灾新增条件
存储复制平面带宽需根据复制周期内的所有数据变化量来计算。计算公式为:保护虚拟机数量*虚拟机复制周期内平均变化数据量(MB)*8/(复制周期(分钟)*60)。
16.VRG进行主机复制容灾,它是同步还是异步,还是二者都有?
只有异步。RPO>0秒 RTO>0 分钟
17.主机层复制的IOMirror是如何把数据传给VRG的?
IOMirror首先从名字上来说,它会把数据相当于镜像,然后将镜像过的数据通过IP转发给VRG,在主机复制的场景当中,需要给CAN主机添加“虚拟机容灾数据流量业务管理接口”。
18.VRG可以跨主机保护吗?
可以。
19.双活为什么使用波分设备?
因为DCL链路成本太高,所以我们使用波分设备复用链路,减少成本,但是更多的是减少时延。
20.华为接管外部存储原理
20.FusionSphere存储复制组网图
21.FusionSphere主机复制组网图
22.双活中那层最难实现?
计算层。因为因为他很难做到双活,他只是利用集群的HA机制达到双活,并不是实际意义上的双活。
23.什么是主机复制容灾和存储复制容灾?(FusionSphere容灾)
主机复制容灾是利用FusionCompute的IO镜像复制功能,将生产站点存储上的虚拟机数据远程复制到容灾站点,并由BCManage实现虚拟机配置数据(如虚拟机CPU、内存、网卡、磁盘属性等)的复制和容灾恢复计划的管理。
阵列复制容灾是指在两地建立两个站点,分别为生产站点和灾备站点,利用存储设备的远程复制功能,将虚拟机数据从生产站点复制到灾备站点,再使用BCManage容灾管理软件,在灾备站点将灾备存储上的虚拟机注册到虚拟化平台,并自动启动。
24.华为双活数据中心资料,这个最好看看,考试有几率从里面问追问。
四:备份解决方案
1.备份代理为什么能够知道vrm在哪里?
管理员在ebackup的portol上会添加受保护环境,会添加vrm的IP地址。
2.LAN-Base和LAN-Free的应用场景?
Lan-free的应用场景:
LAN-Free备份部署场景适用于备份数据量较大,对备份窗口要求比较严格的场景。
Lan-base的应用场景:
LAN-Base备份部署场景适用于备份数据量小,对备份窗口没有特殊要求的场景。
引申:什么是备份窗口?
在不影响业务的情况下,备份的时长。(也就是开始备份到结束备份的时间)
3.ebackup备份对虚拟机数量的限制?
10000台虚拟机
4.ebackup可靠性如何保证?
1、备份服务器可以做到主备部署,提高可靠性
2、多个备份代理协同工作,出现故障后,由备份服务器协调其他备份代理继续备份工作,支持断点续传。
引申:断点续传怎么实现?
备份代理和备份服务器会有一个共享数据库,ebackup周期性的将备份状态记录到数据库,当备份代理故障后,指定另一个备份代理接替工作,接替的备份代理会从数据库中读取备份状态,继续备份。
5.ebackup支持的生产存储有哪些?
Lan-base组网为虚拟化数据存储
Lan-free组网为虚拟化数据存储或fusionstorage
6.备份代理的规划?
1、备份代理可以承载多少个并发任务数量?
默认单个备份代理可以承载20个备份和恢复并发任务数量(并发任务)最大40个(通过修改配置调整到40个)
2、每个备份代理管理200个虚拟机,可以根据实际情况进行上下浮动
7.现实工作中如何选择2种ebackup组网方式?考虑哪些因素?
1、客户需求
不对现网业务造成影响,使用lan_free
2、现网环境
已经有后端san网络。提高备份性能和体验,使用lan_free达到最优的效果
3、成本考虑
成本比较严苛,使用lan_base,成本低,有效控制成本。
不限于此,要学会发散思维。
8.没有业务闲时如何做备份?
相同备份总量的情况下,拉长备份窗口,尽可能减少备份占用网络的带宽,对现有业务的影响。
9.虚拟化备份和云备份的区别?
10.ebackup备份lan_base备份流程:
11.ebackup备份Lan_free备份流程(无Fusion Storage场景)
12.ebackup备份Lan_free备份流程(有Fusion Storage场景)
13.ebackup存储要求?
生产端存储要求是FusionStorage或者虚拟化存储,因为需要打快照,在线备份是会有数据变更,导致数据不一致,需要采用快照实现数据的一致,需要对存储打快照。
备份存储要求为共享存储或分布式文件存储(vims cifs nfs),能够让多台主机同时访问(共享存储的原因是因为有多个备份代理需要同时访问存储)
14.ebackup支持对物理机进行备份么?
ebackup是业务在线备份,需要对整个业务虚拟机进行定格,通过打快照实现,ebackup无法对物理整机打快照,所以无法实现对物理机打快照。
15.华为有没有server-free?
没有,ebackup在备份时,生产系统需要参与备份,如打快照,参与数据转发,server free要求生产系统完全不会参与的,故没有server-free。
16.Lan-base中生产存储可以使用FS么?
不行,生产存储的VBS和备份代理的VBS要同步快照信息,通过存储平面。
17.Lan-base和lan-free的区别:
1、网络平面
Lan-base有前端LAN网络和各自的SAN网络,SAN网络不需要互通
Lan-free有前端LAN网络和共享的SAN网络
2、流量走向
Lan-base控制流和备份流都走前端LAN网络
Lan-free控制流走前端LAN网络,备份流走后端SAN网络
3、对现有业务影响
Lan-base需要占用前端LAN网络走备份流量,对业务影响较大
Lan-free不需要占用前端LAN网络走备份流量,对业务影响较小
4、成本
Lan-base利旧现有设备,成本低
Lan-free需要新建SAN网络,成本高
5、生产存储
Lan-base只能是虚拟化数据存储(CBT技术)
Lan-free可以是虚拟化数据存储和fusionstorage(快照对比)
18.备份流程?
首先在备份存储里创建存储单元、存储池、存储库
之后在备份里创建保护集、保护策略、保护计划
19.ebackup有什么特点?
1.分布式架构
2.在线备份
3.永久增量式备份、恢复
4.支持文件颗粒级恢复
5.任务负载均衡(多个备份代理同时工作)
6.无代理备份
7.支持重复数据重删和数据压缩减少存储空间
8.使用B/S架构,也就是可以以网页的方式进行使用和方便管理
20.备份怎么恢复的?
恢复时,以什么方式备份就以什么方式恢复
21.CBT图解
-
备份服务器和备份代理用虚拟机方式部署时,备份存储能否使用FC SAN?
不能,因为使用FC SAN需要HBA卡,但是虚拟机没有HBA卡,所以我的备份存储不能使用FC SAN。 -
快照谁打的?
CAN打的。
引申:
快照是不是都由CAN打?
不是。lan-free场景下生产存储使用的是FS的时候是由vbs完成的。
为什么快照流走管理平面?
因为VRM没有存储平面
25.CBT文件存在哪里?内存位图呢?
CBT文件存在于生产存储和备份存储上。内存位图存在于内存中。
26.为什么生产存储使用FS的时候需要备份服务器物理部署?
因为性能和VBS的原因(答案有待验证)
五:桌面云解决方案
1.组件部署方式
WI HDC VAG 多活
ITA DB VLB 主备
License Backup 单个部署
2.虚拟机登录流程
1、获取登录界面:
1)TC/SC输入桌面云的域名,TC/SC到DNS解析成VLB的IP地址,并转发获取登录界面请求到VLB
2)VLB根据内部的负载均衡算法,选择一个负载较轻的WI,并转发获取登录页面请求到WI
3)WI返回登录界面给VLB
4)VLB返回登录界面给TC/SC,TC/SC呈现给用户
2、验证并登录
1)用户在TC/SC上的登录界面输入用户名密码,转发给VLB
2)VLB转发用户名和密码给WI
3)WI收到用户名密码后转发给AD,进行验证
4)AD验证成功后返回验证成功给WI
5)WI返回登录成功后的页面给TC/SC,TC/SC呈现有用户
3、获取虚拟机列表信息
1)TC/SC发起获取虚拟机列表信息请求给VLB
2)VLB转发请求给WI
3)WI转发请求给AD,查询用户所属的用户组信息
4)AD返回用户所属的用户组信息给WI
5)WI轮询向HDC查询用户虚拟机列表
6)HDC向DB查询用户所拥有的虚拟机列表信息,并查询虚拟机状态
7)HDC返回用户虚拟机列表信息给WI
8)WI返回给VLB
9)VLB返回给TC/SC,呈现给用户
4、发起预连接流程
1)TC/SC选择需要登录的虚拟机,转发预登录请求给VLB
2)VLB转发预登陆请求给WI
3)WI转发预登陆请求给HDC
4)HDC记录登录状态到DB中,并获取虚拟机地址和状态
5)HDC向虚拟机发起预连接请求
6)虚拟机向HDC请求策略文件
7)HDC到DB中查询策略文件,返回给虚拟机
8)HDC与LICENSE服务器交互,查询LICENSE是否充足
9)HDC返回信息给VLB(vag ip、address ticket、logon ticket)
10)VLB返回给TC/SC
5、登录虚拟机
1)TC/SC拿着vag ip信息发送登录请求给VAG
2)VAG和HDC进行交互,获取虚拟机IP和端口号
3)HDC返回虚拟机IP和端口号给VAG
4)VAG解析后,向虚拟机发起登录请求
5)虚拟机拿着logion ticket向HDC换取用户名和密码
6)HDC将虚拟机的用户名和密码返回给VM
7)虚拟机拿着用户名密码向AD请求关联与和认证
8)认证成功后,VM向VAG返回登录成功
9)VAG向TC/SC返回登录成功
10)VM向HDC上报登录状态,HDC记录到DB
引申:在TC/SC输入的是谁的域名?
输入的是VLB的域名,如果没有VLB则输入WI的域名。
获取桌面状态有什么用?
判断注册情况,虚拟机情况,电源检查。在专有池静态多用户如果已有用户在使用虚拟机,就会提示有用户已登录。
VM机关机会怎么办?
在登录中,DB中查询到VM的状态为停止运行,DB将其返回给HDC,HDC返回给WI,WI通知ITA,ITA通知VRM对虚拟机进行上电。
为什么要进行预连接?
将桌面开机
应用桌面策略。(策略性系存储在HDC管理的数据库中)
License验证
返回桌面登陆材料:①Loginticket、②HDP是否经过vAG, 是:返回AddressTicket和vAG的ip,否:返回VM的ip
为什么获取WI登录界面,返回时WI不直接返给TC,而是要VLB转发?
因为WI认为VLB是客户端而WI不知道TC的存在。
VLB的作用有哪些?
1.实现负载均衡。
2.实现WI的冗余。避免WI的单点故障
VAG的作用有哪些?
桌面接入网关(ita场景下配置的)、自助维护平台。
点击虚拟机时一直转圈圈怎么回事?
首先在点击登录时之前的步骤是没有问题的,那么就考虑点击虚拟机之后的流程问题。
1.可能HDC找不到DB中VM的信息,或者DB的虚拟机信息被篡改。2.可能LICENSE不足。3.HDC可能无法跟VM通信。4.可能虚拟机的HAD故障。5.虚拟机可能未注册。6.兼容性问题。
登录完成后还会不会查license?
不会
登录所有流程走完了,流量交互还过不过HDC ?
不经过。登录成功后,客户端HuaweiAccessClient与VM中的HDA使用HDP协议进行点对点通信。
用户鉴权过程中,如果AD鉴权失败,会返回什么?
返回鉴权失败,没有其他信息。
虚拟机预连接中HDC找DB查询虚拟机的信息有哪些?
虚拟机有没有被使用
虚拟机运行状态,分配状态等等
ip地址等等
3.LICENSE用户数和并发用户数的区别?
都是以用户为对象扣除
用户数退出登陆后,不会释放LICENSE,超过15天未登陆会释放LICENSE
并发用户数在退出后会立刻释放掉LICENSE
4.为什么完整复制不需要同一个模板,而链接克隆需要同一个模板?
链接克隆可以配置统一升级和补丁等操作,这些操作时对整个虚拟机组进行的,如果虚拟机组中的虚拟机不是来自同一个模板,无法统一升级打补丁等操作。
5.为什么桌面组类型为专有,只支持虚拟机组类型为完整复制和托管机?
链接克隆类型虚拟机具有大量同质化数据,不安全,不适合专有类型桌面组
6.静态多用户的虚拟机支持多个用户同时登陆吗?
不支持
引申:不同用户静态多用户登陆的电脑界面一样吗?
进入到同一个电脑,桌面环境不一样 这个是由Windows提供的多用户。
7.链接克隆为什么要在制作模板的时候加域?
1、省去在发放过程中加域这个动作,发放速度快
2、发放桌面时如果开启了关机还原场景下,加域属于差异化数据,加域是会重启的,关机时加域信息会消除掉,开机时需要重新加域,因为虚拟机注册信息不一致,有可能加域失败。
3、可以用于批量发放。
8.链接克隆为什么不封装?
1.首先如果封装会消除个性化信息,包括域信息,那么就会导致我们发放过程中需要手动加域。
2.封装的话,在关机还原时,我们每次都需要加域,那么会导致域信息不一致,导致我们加域失败。
9.完整复制为什么不在制作模版时加域?
因为完整复制会封装,封装会消除域信息,即使加了域,也会退域,所以制作模版时不需要加域。
10.完整复制为什么需要封装?
因为是通过模板发放的,发放出来的sid都是相同的,就会出现问题,封装是为了给虚拟机重新分发sid,还有就是消除一些个性化信息。因为完整复制如果要给多个虚拟机用的话,如果有个性化信息,到发放的时候就会应用到所有虚拟机上。
11.完整复制为什么发放时解封装?
解封装是因为要重新获取sid ip等等信息。
12.完整复制和链接克隆有什么区别?
制作模版上
模板类型区别:在制作模板需要选择完整复制/链接克隆类型进行制作模板。
是否加域区别:完整复制不需要,链接克隆需要。
是否配置允许本地登录区别:链接克隆一般发放给user用户使用,所以要配置,而完整复制桌面一般发给管理员使用的,所以不需要配置,默认允许管理员账号登录。
OS是否封装区别:完整复制需要,链接克隆不需要,根据选择不同类型的模板,会进入不同的模板制作流程。
使用场景上
完整复制使用在保存个性化数据,个性化应用的场景;连接克隆应用在同质化比较高的场景。
发放上
用户是否加入权限组。完整复制需要;链接克隆不需要。
链接克隆发放速度快(除第一次外,都比完整复制快,因为第一次需要生成母卷);完整复制较比链接克隆要慢很多。
完整复制可以加入所有类型的桌面组,连接克隆只能加入静态池,动态池
链接克隆支持关机还原;完整复制不支持。
技术上
完整复制使用独立的磁盘与OS类似于物理PC一样,给用户使用;链接克隆采用链接克隆母卷加链接克隆差分卷组合映射为链接克隆卷映射给VM使用。
存储成本上
每个完整复制桌面使用独立的磁盘使用存储空间,所以占用大量存储空间;
多个链接克隆桌面可以共享一个链接克隆母卷,近而节省大量存储空间。
13.静态池和动态池的区别?
用户的关系:
静态池登录后会形成绑定关系;动态池退出后会解除绑定。
关机还原:
静态池默认不开启 关机还原;动态池默认开启。
14.静态多用户与静态池的区别?
- 比例:
静态多用户桌面可以同时分配给多用个用户(1:m);静态池同时只能分配给唯一一个用户(1:1); - ITA用户:
静态多用户在发放完成后仍保留ITA用户,用于后续的删除、追加用户;静态池不保留; - 应用场景:
静态多用户针对多用户共同使用桌面;静态池应用于同质化比较高的场景; - 发放后的分配状态
静态多用户为已分配;静态池为未分配(用户登录时才会分配); - 支持的虚拟机组
静态多用户只支持完整复制;静态池支持所有;
15.虚拟机为什么要注册?
HDP承载在IP之上,所以与桌面建立HDP连接需要知道桌面IP地址;
桌面的IP通道通常是DHCP,桌面没有一个固定的IP;
注册可以让HDC获取桌面的IP,用作后续桌面连接;
可以收集桌面的状态信息。
16.协议问题
预连接成功前,使用HTTP/HTTPS协议,但是VLB和WI是用IP协议,预连接后使用HDP协议。
17.虚拟机登录不上什么原因?
登录不上就是出了问题,首先先分情况,是大规模故障还是小规模故障。
大规模故障考虑组件问题。1.可能是HDC故障、或者DB故障、DB信息被篡改。2.可能License故障或者不足。3.可能组件之间无法通信。4.可能版本问题。5.TC/SC可能故障。
小规模故障考虑虚拟机侧。1.可能虚拟机未注册。2.可能虚拟机故障。3.可能HDA故障。4.可能虚拟机无法与HDC通信。5.FC的资源可能不足(追问再答)。
18.如果我客户要求是链接克隆虚拟机但是又要保存个性化数据,要怎么实现?
使用链接克隆静态池方式发放桌面。
19.在链接克隆场景,通过同一模板产生的虚拟机,他们的MAC地址是不是一样的?
不一样的,由于是网卡有CNA模拟出来的,每个模拟的网卡的MAC不一样
在桌面云场景中制作模板会要求DHCP获取,所以是DHCP获取或者注入。
20.虚拟机组和桌面组的区别?
虚拟机组代表虚拟机的产生方式,由同一个模板产生的虚拟机放到同一个虚拟机组中,桌面组代表如何分配虚拟机,代表虚拟机和用户的关系,通过桌面组维持虚拟机和用户的关系。
虚拟机组在发放时有可能是分配状态,也有可能是未分配状态
桌面组在发放时是一种已经分配的状态
21.桌面云容灾?
1、基于客户端的自主容灾
采用基于CloudClient进行对VLB进行健康检查进行容灾切换的方式适用于小规模、简单而且不需要进行数据容灾的场景,如:营业厅、客服坐席、呼叫中心等。
CloudClient是部署在终端一个集成了浏览器功能的组件,该组件主要有如下两个功能:用户通过该组件的配置界面WI的URL;用户点击该组件时,该组件能够通过Http协议,和WI交互,向用户呈现Web登陆界面。如果需要使用CoudClient的容灾功能,可以通过CloudClient配置生产站点和灾备站点的URL,当用户点击该组件进行桌面登陆时,该组件优先登陆生产站点。当发现生产站点异常时,则该组件会登陆到灾备站点。
2、基础GSLB的容灾
GSLB充当了客户端(包括TC和SC)的DNS服务器,GSLB定时检查两个数据中心的vLB的健康状态。
GSLB充当了客户端(包括TC和SC)的DNS服务器,GSLB定时检查两个数据中心的vLB的健康状态。当客户端登陆桌面时,首先向GSLB(DNS)解析待登陆数据中心的URL,GSLB根据用户预设规则,优先返回预设规则数据中心的IP地址,如果首选数据中心异常时,则把客户端的域名解析为灾备数据中心的IP地址。
上图为容灾方案的组网图,两个数据中心独立部署一套完整的VDI系统,为了简化说明,下图只画出了VLB、WI和AD等容灾相关VDI基础架构。在生产和灾备站点各部署一套AD,AD通过自身的机制进行用户信息同步,这样可保证用户用同样的密码进行WI登录。
3、基于GSLB+NAS的容灾方案
数据盘放在NAS上,通过NAS本身的远程复制机制,把数据盘的数据异步拷贝到灾备数据中心进行容灾。
当用户登录时,由用户的AD策略,挂载数据盘。当生产数据中心异常时,用户登录灾备中心的虚拟机,虚拟机则根据域策略,重新挂载数据盘,从而实现数据容灾。在该方案中,生产站点和灾备站点是独立的两套VDI系统,每个系统都运行一个虚拟机,系统盘是独立的,但数据盘是共用的,由用户登录时挂载。
虚拟机的数据盘为通过CIFS协议挂载的NAS网盘。NAS在每个数据中心都部署一套或者多套,两个数据中心的NAS通过NAS自身的复制机制进行数据同步。根据实际需要,在两个站点之间选择一个部署主NAS。只有当主NAS异常时,GSLB才把该域名解析为备用NAS。
22.FA中DB保存了什么信息?
HDC和虚拟机信息。
23.DHCP服务器正常,物理链路正常,发放虚拟机拿不到IP,为什么?拍错一下。
可能地址池满了、二层广播域不通、跨三层配置中继、虚拟机端口组配置错误。
24.桌面云发布流程
25.为什么虚拟机发放到50%时卡住了,发放不了怎么回事?
可能是虚拟机网络出问题了,可能是DHCP地址池满了、DHCP服务器故障、或者DNS故障,无法解析域名、或者AD域故障、或者发放桌面时端口组选择错误、等等。。。。
26.链接克隆怎么保存个性化数据?
- 不要把关机后还原开关打开;
- 给VM单独配置数据盘(针对链接克隆池化,拥有管理员权限的场景);
- 采用共享文件存储的方式。配合AD域中配置用户的配置自动完成磁盘映射的配置;
- AD的数据漫游功能(通过在Active Directory上为这些用户规划配置Profile重定向或文件夹重定向的方式来满足。)
27.快速封装和完整复制的区别?
在制作快速封装模版时,不会对该虚拟机进行封装。
快速封装虚拟机创建时,没有解封装过程,并且已经提前加域,省去了重启操作,该类型虚拟机比完整复制虚拟机发放速度更快。
注意:
通过快速封装模板发放的虚拟机,其Local SID都是一样的。个别行业软件会通过Local SID识别虚拟机,因此会将同一个快速封装模板发放的所有虚拟机识别为同一台虚拟机,从而导致一些安装和使用上的问题。建议在使用快速封装时,小批量发放一些测试虚拟机,确保客户需要使用的行业软件都能正常运行。
28.什么是专有、静态池。动态池?
专有:用于发放“完整复制”类型的桌面,用户和虚拟机之间有固定的分配绑定关系。分配方式为静态多用户时,一个用户可以拥有多台虚拟机,一台虚拟机可以分配给多个用户;分配方式为单用户时,一台虚拟机只能分配给一个用户,是该用户的专有虚拟机。
静态多用户分配方式下,多个用户共享同一台虚拟机,用户保存的资料可被其他用户访问,请不要在虚拟机中保存个人敏感数据。
静态多用户适用于安全性要求不高的场景,例如营业厅、呼叫中心等。
动态池:用于发放所有类型的桌面。分配方式为动态多用户。用户和虚拟机之间无固定的分配绑定关系,一个用户在同一个桌面组内只能拥有一台虚拟机,虚拟机分配给用户后,用户每次登录可能为不同的虚拟机。
静态池:用于发放所有类型的桌面。分配方式为动态多用户。初始用户和虚拟机之间无固定的分配绑定关系,一个用户在同一个桌面组内只能拥有一台虚拟机,虚拟机分配给用户后,一旦用户登录虚拟机,即产生固定绑定关系,用户每次都会登录该虚拟机。
29.那些组件是非必选的?
VLB、VAG、AD、DNS、DHCP、ebackup、TCM
六:业务迁移
1.迁移的目的是什么?
这个问题同以下问题一样:
为什么要做迁移?为什么要上云平台?为什么要上虚拟化?为什么要用华为云平台?云计算/虚拟化好处?
- 本质来说是提高资源利用率。
- 配合虚拟化管理平台(云平台)简化运维,统一管理。通过管理平台进行绿色节能DPM,DRS。
- 节省物理空间。
2.rainbow可不可以在物理机上部署?
可以 (rainbow是个exe的执行软件)
引申:安装rainbow只能安装在window系统吗?
是,rainbow是个exe的执行软件。
3.用浏览器登陆Rainbow,它是什么架构
B/S架构
4.文件级、块级的选择?
Llnux:
1.迁移后需要对存储空间进行增容减容的情况下;
2.Linux系统首先考虑文件级迁移;(通过tar多次将大量的文件归档为一个单文件,然后用SSH发送过去,最后用rsync进行数据同步)
3.迁移过程中只迁移部分数据的情况下,
4.对成功率要求不高的情况下,
5.业务的复杂度不高的情况下
Windows:
1.有空洞文件用块级迁移(含0页文件)
2.保证原来分区不变用块级迁移
3.Windows系统文件数量多,单文件小,所以推荐用块级(VSS技术,块级迁支持零拷贝)
4.磁盘分局结构和源端一致。
5.文件级迁移和块级迁移有什么区别?
文件级:
1、支持分区大小调整
2、可按目录排除不需要迁移的文件(效率高)
3、只迁移有效数据
块级:
1、速度相对较快
2、分区结构与源端保持一致
6.为什么Windows推荐使用块迁移。Linux推荐使用文件级迁移?
Windows:
1.window小文件较多,且条目不清晰,需要频繁访问元数据,块级迁移只要将块迁移过去就行,不需要频繁访问元数据。
2.使用块级迁移配合NTFS文件系统,不会对未使用的空间进行迁移(源端有大量的零页空间的文件,数据本应该拷贝过去的,但是没拷贝过去,对端自动生成了),迁移速度快。
3.块级迁移使用VSS卷影副本机制定格数据,数据不会受损。
基于上面三点块级迁移比文件级迁移快,成功率高。
Linux:
Linux如果使用块级迁移(也就是DD技术)无法对系统打快照,也就是无法定格数据,可能造成数据受损。可是文件迁移通过tar多次将大量的文件归档为一个单文件,然后用SSH发送过去,最后用rsync来同步。(不是一次tar打包所有文件,通过多次tar多次打包数据)。
7.Rainbow能否迁移应用?
Rainbow是系统级迁移工具,它并不能针对特定的应用进行应用级的迁移,但是是系统级迁移之后,源端的应用也会一起被迁移过去,但是不能保证应用一定处于可用状态。
8.怎么样减少我们的迁移中断时间?
1.增大带宽
2.操作人员的熟悉程度
3.进行多次数据同步,让最后一次数据同步的数据量减少
4.业务闲时时,也就是在单位时间IO量比较小的情况下操作
5.增加目的端虚拟机的CPU内存,提高迁移效率
引申:使用Rainbow迁移VM为什么要在业务闲时操作?
IO比较大的情况下,单位时间内产生的增量数据会比较多,因此会造成最后一次同步的数据差异量较大,进而增加最后一次同步时长。
9.迁移需要多长时间?
业务在线迁移时间+最后一次同步时长+业务切换时间
10.我怎么保障目标虚拟机的IP和源端主机的IP一致?怎么实现的?
切换到目的虚拟机前使用临时IP,在离线同步结束后,禁用源端虚拟机的网卡配置ip,配置目的端虚拟机IP为源IP。
11.迁移的时候源端需不需要做快照,谁做的?
Linux不需要快照(Linux使用文件级迁移用tar技术将数据归档传送)
Windows需要,源端每次同步都会打一次快照(Windows因有VSS支持打快照,其他的不打快照)
12.windows迁移打几次快照?
源端一次:在线迁移,源端数据会发生变化,需要快照定格。
目的两次:1、迁移完成后,配置操作系统之前 原因:迁移完成后,配置操作系统。这个动作ebackup认为是高危动作,需要定格数据。2、测试之前 原因:有可能损坏数据、修改数据,产生脏数据,需要快照定格,便于恢复时需要进行回退。剥离脏数据。
引申:
一定就是3次快照吗?
不一定,每次数据同步都是打3次快照。
13.迁移时流量进过Raninbow吗?
不经过,直接源端到目的端。因为如果并发迁移的话,那么Raninbow会有性能瓶颈。
14.RaniBow介绍?
1、概念:
Rainbow是华为自研迁移工具,支持将X86服务器的操作系统和虚拟平台上的虚拟机的操作系统和数据迁移到华为的虚拟化平台上。
2.特点
1、是系统级别的迁移工具
2、支持在线迁移
3、兼容主流的window和linux操作系统(window XP之后的版本,suse、centos、redhat、Ubuntu等等),还兼容物理机。
4、兼容很多第三方虚拟化平台(vmware、fc、xen、hyper-v、kvm、思杰)
5、支持文件级迁移和块级迁移
6、支持并发迁移任务
7、多次数据同步,保障数据一致性
8. 支持V2V迁移和P2V迁移
15.RainBow业务迁移流程
1、安装rainbow,只能装在win7、win10、windows server2008
2、创建目标虚拟机带有rainbow字样,配置磁盘、网卡、内存和CPU
3、配置云平台、配置license、配置共享
4、配置源端虚拟机
1)用户名、密码
2)检测磁盘和分区
5、创建迁移任务
给目标端虚拟机配置临时IP
6、执行迁移任务
1)给源端虚拟机推送agent
2)给目标端虚拟机配置IP地址
3)给目标端虚拟机进行分区
4)进行系统迁移
5)配置目的端虚拟机
6)迁移成功
7、业务测试:验证迁移后的系统可以正常工作
数据同步:将原虚拟机迁移后新增数据同步到目标虚拟机
业务切换:最后一次数据同步后将业务切换到目的端虚拟机
Rainbow迁移虚拟机word文档详解一份:
16.如何进行业务切换?
1、禁用原主机网卡
2、tools是否一致,如果不一致,卸载tools,安装华为tools
3、给目标端虚拟机配置IP地址
17.Rainbow迁移windows主机的时候,是只迁移C盘还是把CDEF所有的盘都给迁移了?
文件级迁移可以选择想要迁移的磁盘和文件夹,块级迁移也可以选择盘符
18.为什么不支持半虚拟化迁移?
对操作系统的代码进行修改,针对虚拟化平台进行处理,迁移到其他虚拟化平台可能不生效。
19.数据库一定要迁移到Rainbow怎么迁移?
1、使用数据库厂商自带的迁移软件进行迁移。
2、停止数据库业务,再使用Rainbow进行迁移。
20.AIX为什么不能迁移?
因为AIX是运行在Power架构上的操作系统,而现在我们都是基于X86架构进行迁移的(因为FusionSphere是x86架构的),所以不能迁移。
21.rainbow在windows块迁移为什么不能对分区减容?
因为迁移时没有文件系统的参与,所以系统并不能感知块中是否有真实的数据存在,如果减容,可能会减去(丢失)一些有使用数据的块,导致数据损坏。
引申:未分配的磁盘空间,即有磁盘,没有创建分区,这样的磁盘是可以减容的,所以windows的块迁移是可以对磁盘进行增减容的。
22.Linux块迁移为什么不能对分区进行增减容?
因为Linux块迁移使用的DD技术,DD技术对磁盘进行迁移,不是针对分区的(磁盘概念大)。
23.rainbow迁移会数据损坏吗?
一般不会损坏。块迁移是用VSS(卷影副本技术保证数据一致性) 文件迁移使用文件系统保证数据不会损坏。
24.为什么windows要装代理,linux不用装?
因为windows是闭源的,不安装agent的话,无法调度数据,linux是开源的,只需开放22端口就能获取数据。
25.VSS有什么作用?
VSS(volume shadow copy service,卷映射拷贝服务),通过在卷管理模块上加入快照功能,在此基础上就可以创建基于时间点(point-In-time)的映像(image),从而实现数据的快速备份和恢复,用户也无需害怕因无意删除数据而造成的困扰。
26.为什么目的端需要挂载winpe或者livecd?
1.因为我们需要对磁盘进行分区格式化,以便源端磁盘分区数据可以迁移过去使用。2.还有就是需要对目的虚拟机设置临时IP地址。
- rainbow服务器需要三张网卡,哪三张?
1、与源端虚拟机的网卡,推送代理
2、与目的端平台互联,命令其创建目的虚拟机等
3、与目的虚拟机互通,给目的虚拟机挂载临时操作系统
七:Openstack
1.keystone介绍
提供认证服务:①认证鉴权②服务目录
1.来访者身份识别。(类似于公司前台,是来访者第一个入口)
2.来访者进行指引。
3.身份识别后,发放一个具有有效期的统一的身份证明,Token提供给来访者一个目录,包含提供具体服务的入口有哪些,基于rest架构与客户进行沟通,通常采用HTTP,每个服务都有三个URL:internal,admin,public
引申:Token之间的区别:
UUID:Token大小小,只有32B大小。缺点是过期之后不会自动删除,FSO运行时间长之后Keystone压力大,成为性能瓶颈。
PKI/PKIZ:采用非对称加密方式,Keystone使用私钥加密,各个组件收到用户Token后采用公钥解密,无需再次向Keystone对用户Token进行认证,在组件本地完成认证。缺点是Token较大,有2000B,而PKIZ方式与PKI方式工作流程一致,对Token进行压缩,压缩后大小为原先90%左右。
Fernet(华为默认使用这个):采用对称方式对Token进行加密,Token生存周期到后会自动清理Token,Keystone负载压力较小,工作方式与UUID相似。
四种Token详细介绍网址
https://www.cnblogs.com/allcloud/p/5120414.html
华为默认使用的是最后一个,也就是Fernet。
2.glance介绍
Glance-api:
1、对外暴露rest api,接收用户请求
2、返回用户相关查询信息
Glance-registry
与DB交互,负责处理和存取image的metadata
引申:Glance支持镜像格式有哪些?
Vmdk
Vhd
Iso
qcow2
Glance安装在哪里的?
CPS分为控制节点及计算节点。
Glance安装在CPS节点中,一般部署在控制节点当中。
glance-api可以用什么协议上传?
https、nfs、共享方式
glance协议选择?
大于6G选择nfs、小于4G选择https
3.ceilometer介绍
提供数据收集服务,并将标准化后的数据提供给其他组件使用
1、ceilometer-api:
a.提供rest api接口,接收请求
b.返回查询数据
2、ceilometer-collector:
集中各种agent收集的数据,存入数据库
3、ceilometer-agent-compute:
在每个计算节点上轮询查询资源利用率和统计信息(收集)
4、ceilometer-agent-central:
查询与实例或计算节点无关的资源利用率和统计信息
5、ceilometer-agent-notification:
在消息队列中接收各服务组件的构建事件、计量数据消息(接收)
6、ceilometer-hardware-agent:
获取物理主机计量数据
ceilometer通过各个agent收集相关计量数据,发送给消息队列(rabbit mq),ceilometer collector收集mq上的计量数据下传到db
4.cinder创建卷的流程?
- 用户下发创建卷请求
- cinder-api效验用户是否具有权限,以及做一些基本效验,配额预占等操作,异步返回卷信息(生成卷ID)
- cinder-api将创卷消息投递到scheduler消息队列中,filter根据可用分区过滤掉一些不能访问某存储的主机。
- scheduler从自己的消息队列消息中读取创建卷的消息,根据各个volume定期上报的能力以及卷信息,选择一个主机进行创卷
- scheduler调度到主机后,将消息投递到相应的volume队列中
- volume从自己的消息队列中消费创建消息,调用driver的接口进行创卷,最后更新数据库。
- volume调用driver插件,将创卷的命令发给存储,存储完成创卷动作。
Cinder提供块存储服务。
Cinder创建卷流程详细版:
5.heat介绍
提供应用编排服务
1、heat-api
a.暴露rest api接口,将请求路由到heat-engine
2、heat-api-cfn
提供aws兼容的api的接口,将请求路由到heat-engine
3、heat-engine:
a.协调并装载模板
b.将模板解析成事件请求,分别发送到其他服务的API
6.nova介绍
提供计算服务
Nova-api:
1.接受外部API消息
2.处理消息
3.回馈响应
Nova-conductor:
1.复杂流程控制和处理
2.代理数据库的操作
Nova-scheduler:
相应规则筛选一台合理的控制节点,来承载业务
Nova-compute:
用于对接底层的计算节点,对实例生命周期的管理
引申:在Nova内部通信中,为什么使用RabbitMQ?
使用消息队列进行异步消息传送。
- 异步传输:多任务进行处理,提高整体性能,不会因为某一节点的瓶颈而引起全局的瓶颈;
- 实现组件之间的解偶。比如Nova-API与Nova-Conductor通信情况下,因为某些原因需要替换掉Nova-Conductor,此时不需要修改Nova-API的接口,因为Nova-API与RabbitMQ进行连接。
1.可以避免同步通信因某节点瓶颈造成整体性能瓶颈
2.解耦组件间的关系,有利于对各组件之间扩展和增减
3.每个组件可以独立运行一些修订而不影响其他组件间的工作
组件内部通信协议?
消息类型为RPC(远程过程调用)
它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
经过Internal_base网络平面,与RabbitMQ进行通信,消息类型为RPC.
nova除了虚拟机还可以对什么进行管理?
还可以对裸金属和容器进行管理
7.介绍块存储、文件存储、对象存储,并说明区别?
1、块存储:
名词定义:以块为基本的存储单位提供存储空间
优点:
最原始的存储使用方式,以硬件的形态设计,设计简单,性能好。
缺点:
未考虑锁机制,多个客户端共享同一块设备的情况下,容易造成数据受损。
2、文件存储:
名词定义:以文件为基本单位提供存储空间,在块存储上以软件的形态工作
优点:
支持锁机制,支持多个客户端共享同一文件存储。
缺点:
性能较差
3、对象存储:
名词定义:以对象为基本的存储单位提供存储空间,元数据和数据分离,利用分布式技术,以软件为形态,通常在块存储或者文件存储之上以对象的方式提供存储空间。
优点:
线性扩展能力强,基于网络的使用方式,多主机可以共享对象存储空间,基于X86服务器,廉价。
缺点:
时延高,要求应用自身对时延不敏感。
8.glance和swift经过MQ吗?
glance不会经过过MQ通信,以RPC的方式通信
SWIFT也不会用MQ
9.Swfit能够对接哪些存储?
本地磁盘
远端存储(XFS文件系统)
10.虚拟机创建流程?
11.mongodb和GaussDB有什么区别?
1、节点部署方式,mongodb是3节点负载分担模式,GaussDB为主备部署
2、性能区别:MongoDB性能优于GaussDB。MongoDB热数据存放在内存(热数据处理放在内存中)
3、数据处理:MongoDB处理非结构化数据(非关系型),GaussDB处理结构化数据(关系型数据)
ceilometer收集来的openstack数据大多数以非结构化数据为主,收集到的信息也比较庞大,需要高性能数据库
引申:
mongodb:默认多活部署,可以选择主备部署
manggoDB部署几节点?
一般为3、5、7
MangoDB使用什么存储设备作为存储空间?
SSD硬盘
华为的Openstack采用了哪些数据库软件?
Ceilometer 采用 MongoDB(使用SSD盘作为存储),其它采用 GaussDB(考官存在质疑,慎答)(社区版采用 Mysql)
华为为什么使用mogondb作为ceilomoter的数据库?
12.哪些组件多活部署,哪些组件主备部署?
多活:mongodb、nova-conductor、api (选答:keystone)
主备:gaussdb、ntp-server、cps-web、dns-server、rabbitmq、fc-nova-compute、haproxy、(选答:Coilmeter-agent-central)(其余基本上都是多活方式部署)
13.swift为什么用XFS:
性能好
可靠性高
XFS支持扩展性的文件系统
14.nova-scheduler筛选怎么知道资源池的信息?
因为nova-compute是知道底层的资源池情况的,nova-compute会定期跟nova-conductor汇报信息,之后保存到DB中,所以nova-scheduler会跟数据库通信,获取资源池情况。
15.rabbitmq?
不属于openstack组件
实现异步消息的功能,组件内部子组件消息交互通过MQ。
16.在社区版新版的S版中增加了什么?
17.OPS中的nova组件部署方式?
注:图中的nova-api是多活部署的,并不是主备部署,图片是不准的。
八:私有云:
1.私有云环境网络类型?
外部网络
vpc的内部网络
引申:
内部网络,路由网络,外部网络,直连网络?
6.3.版本之后,
外部网络包含:外部+直连
内部网络包含:内部+路由
内部网络:仅提供裸VLAN,不提供网关,可选支持 IP 地址管理。
路由网络:提供VLAN,IP 地址管理,三层网关,可以通过nat,eip访问外部网络。
外部网络:不被VDC管理的网络,可以是企业的内部网络也可以是公共网络。网关和路由不在虚拟数据中心方案中管理的网络,外部网络在虚拟数据中心方案中表现为一个独立VLAN,虚拟数据中心方案不管理这个VLAN上的IP 地址分配。
直连网络:提供将虚拟机直接接入到外部网路的能力。部署到这个网络中的VM可以分配到外部的IP地址。
2.级联架构和非级联架构的区别?
1.大规模部署,解决节点瓶颈问题,比如MQ、DB等等
2.级联层做一个统一管理,调度。不会实际去接入资源,比如计算资源,网络资源,这些资源由我们的被级联层来进行接入。
级联的意义是扩展性
3.华为CPS支持对接哪些虚拟化平台?
FusionCompute、VMware(vCenter/ESXi)、KVM、hyper-v,后续有待研究。
4.多套OpenStack可以共用一套KeyStone么?
可以,但不是必须。
级联/并联架构看多套OpenStack必须要共用一套KeyStone。
5.External-om平面为什么能够替代external-base平面?
Ecternal-om能与FusionCompute管理网络3层互通,RabbitMQ所在的CPS节点有或者能够进行external-om平面。
引申:代替有什么优缺点?
优点:简化网络、节省VLAN、易管理。
缺点:未进行网络隔离,安全性较差。
6.FSO的定位怎么说?
FusionSphere是华为面向多行业客户推出的云操作系统解决方案。FusionSphere基于开放的OpenStack架构,并针对企业云计算数据中心场景进行设计和优化,提供了强大的虚拟化功能和资源池管理能力、丰富的云基础服务组件和工具、开放标准化的API接口,可以帮助客户水平整合数据中心物理和虚拟资源,垂直优化业务平台,在支持现有企业IT应用的同时,更面向新兴应用场景,让企业的云计算建设、使用及演进更加便捷、平滑。
7.FSO有什么优势?
易部署、自动化: 提供界面化的OpenStack 自动化部署加载、组件配置、角色修改、扩容等能力。简化安装和OpenStack 管理(通过图形化界面自动化安装并且定义了CPS角色,通过定义角色去部署相应组件(首先通过部署工具完成了第一个节点的安装,然后通过CPS服务完成网络平面的划分,节点功能的划分,nova,cinder,neutron等组件的配置))。
易运维:提供升级工具(udate tool工具),可通过Web 界面和命令行界面对系统进行升级;支持对主机操作系统、基础支撑服务、OpenStack 进行升级。还有FusionCare,提供信息、日志收集机制;扩展命令,用于查看系统和虚拟机的相关信息;提供了告警和性能监控功能,也可以通过CPS运维,进行节点的扩容、日常维护(鉴权、时间同步内部的SSL、检测网络的连通性,安装包管理。存储容灾管理,服务管理(启动、停止服务))。
高可靠: 管理服务均以主备或者负荷分担模式部署,防止单点故障;增强虚拟机异常监控能力,根据虚拟机监控结果进行VM 的HA,即监控虚拟机中GuestOS 系统panic、内核死循环等异常,并提供虚拟机异地重建的机制。独创双分区技术,自动化数据备份。(通过对前端的API采用LB实现多活,并且LB自身主备部署,之后的其他组件通过MQ实现负载均衡,例如nova-scheduler,fc-nova-compute通过CPS与其维持心跳主备部署,gaussDB、NTP、DNS也是主备,CPS自身的由ZK实现高可用)。
扩展性:支持对接FusoinCompute、FusionStorage 等,社区版只能通过Drive去对接FC和FS。
引申:优势补充:FSO有多个网络平面保证系统的安全性和隔离性。还有华为的FSO支持商务支持,也就是可以打华为的400企业客服电话支持帮助解决问题。
8.原生openstack和FSO对比有什么有缺点?
1、版本迭代升级慢。2、命令行在Web界面不能全部实现(比如排障时,有些故障需要去底层用命令行才能实现)。3、兼容性没有源生好,源生兼容更多厂家。
9.FSO对比OPS增加了什么?
新增了3大组件
1、CBS:云启动服务,作用:
a、基础设施安装
b、启动主机操作系统
2、CPS:云部署服务,作用:提供基础设施云化能力,将openstack服务的各个组件部署到不同的主机上。
3、OM:资源管理和运维服务。作用:
a、资源管理:将整个云系统中,对用户可见的资源统一管理,提供一体化的资源管理体验。
b、运维:提供报表、权限、用户管理、维护、故障管理等管理功能
10.Storage-data?
FSO使用KVM时需要使用的平面。
引申:KVM访问存储的存储平面,和cinder对接存储没有关系
FSO对接IPSAN默认使用storage data0和storage data1
对接fs默认使用storage data0
为什么KVM需要使用存储平面(storage_date)?
KVM使用后端存储时,Cinder-volume所在的CPS节点原有的IP接口无法与存储设备的业务接口通讯,会导致无法接入存储资源,所以需要storage_date平面。
11.服务器虚拟化和私有云的区别?
服务器虚拟化主要是fusionsphere,私有云是fusioncloud
1、关注点
1)fusionsphere服务器虚拟化关注的是基础设施层、虚拟化层、资源管理层、并未考虑过多的云服务层。
2)fusioncloud除了fusionsphere关注点之外还重点关注云服务层,提供云服务,如:ECS、EVS等
2、价值
1)fusionsphere通过服务器虚拟化技术实现资源复用,提高资源利用率,缩短业务上线周期,降低能耗。
2)fusioncloud基于fusionsphere价值之上,实现业务自动化,服务化。
3、应用场景
1)fusionsphere有单虚拟化,多虚拟化和(私有云(私有云更多指的是自己建设,自己使用))慎答
2)fusioncloud有融合资源池,托管云,混合云。
4、兼容性
1)fusionsphere对接的hypervisor只有fc和vmware
2)fusioncloud可以对接kvm和hyper-v和vmware和fc
5、架构
1)fusionsphere
a、fusioncompute
云操作系统软件,主要负责硬件资源虚拟化,对虚拟机资源、业务资源和用户资源进行管理。
b、fusionmanager
对云计算的软件和硬件进行全面的监控和管理
实现同构和异构虚拟化资源池管理
软硬件统一告警监控
自主服务及流程审批
c、esdk
服务器虚拟化北向统一接口,和第三方平台无缝对接。第三方网关系统和其他运营平台可以通过eSDK轻松完成无缝对接。eSDK开放了FusionSphere服务器虚拟化的全部能力
d、ebackup
备份软件,实现虚拟机数据备份
e、bcmanager(选答)
容灾软件,利用存储设备远程复制能力,完成虚拟机关键数据保护和容灾恢复
2)fusioncloud
1)基础设施层:
由构建数据中心所需需要的硬件服务器,存储设备,网络设备组成
2)资源池层:
由fusionsphere openstack对接计算资源池、存储资源池和网络资源池等资源池实现,提供资源池管理能力
3)云服务层:
云服务层统一管理多个数据中心资源池层提供的资源,提供云服务,如ECS,EVS等
4)应用域
由第三方提供应用,基于FusionCloud提供的云服务,构建用户的业务系统,满足各行业用户业务需求。
5)管理域
管理域由ManageOne提供对多个云数据中心的统一管理调度能力
12.私有云的三种类型区别?
Type 1
1)支持级联架构,分为级联层和被级联层
2)支持软件SDN,在两台服务器(用于部署网络节点),部署Vrouter、L3NAT、VPN等组件
3)支持混合云
TYPE 2
1)不支持级联架构
2)支持硬件SDN架构,在3台服务器上部署华为AC-DCN,配套Agile Controller-DCN的网络设备,例如:
1.核心/汇聚交换机(CloudEngine 12800)
2.接入交换机(CloudEngine 6800)
3.防火墙(USG9500系列、Eduemon 8000E-X系列)
3)不支持混合云
TYPE 3
1)不支持级联架构
2)不支持SDN
3)不支持混合云
引申:
由此可知1支持大规模环境,2支持中小规模环境,3只能支持小环境。
哪个成本高?
type2,因为要额外部署CE交换机和AC控制器。
为什么我们现在用type2比较多,type1不好吗?
因为type1设计比较复杂,网络功能需要通过neutron+设计和实现二层、三层、NAT、VLB、VPN等功能,type2直接在AC上操作就可以。
解释一下这两个SDN?
硬SDN是通过AC完成网络功能。软SDN通过neutron功能实现的。
13.LVS、Nginx、Console
LVS四层负载,性能好,颗粒度不是很细
NGINX七层负载,性能不是很好,但是负载颗粒度细
console连接后端的云服务
LVS:一级负载均衡,所有云服务console访问的入口。主备部署,向下一级Nginx集群转发请求。
Nginx:二级负载均衡,对所有云服务console提供反向代理服务。集群部署。
14.FSO网络平面
15.FSO流量交互讲解
引申:API网关:
API网关的主要功能是提供API的管理以及API的内外网隔离。用户访问各服务的API
时,不是通过直接调用各服务的API接口,而是各服务的API先在API网关上进行注
册,通过API网关将服务API暴露给用户访问。这样可以屏蔽一些非法请求,并防止内
部的管理API暴露。
组合API为弹性云服务器后台服务,可以理解为ECS_UI的服务端,支持调用FusionSphere OpenStack组件。ECS在前台发出的请求,经ECS_UI转发至组合API,组合API处理完后将结果返回ECS_UI。
16.POD有哪几种?
3种,openstack\cascaded\cascading
17.云磁盘可靠性由谁保证?
由后端底层存储、VBS、VHA、快照等保证,后端存储有高可靠性机制(如FS有多副本和数据重构,传统存储有RAID机制,热备盘等等),VBS也就是备份,VHA是2个双活的磁盘,快照可以定格数据。
18.VBD模式的云硬盘不支持锁机制,但是可以作为共享盘,如何保证不会出现写冲突?
VBD共享盘锁机制由上层应用实现。
19.云硬盘快照定义
云硬盘快照(简称快照)是对云硬盘数据在某一时刻的状态记录,是一种重要的数据恢复手段。通过对云硬盘在某个时刻创建快照,使该快照独立于云硬盘的生命周期,可通过快照回滚操作将云硬盘数据恢复到快照时间点。
引申:后端存储快照实现是基于什么原理?
V3/V5:cow
Dodro:row
FS:DHT
20.Server om为啥有ext-api和ext-om两个平面?
内部管理通过external-om,外部管理用external-api
21.Global、Region、AZ(可用分区)、POD(OpenStack被级联层)
Global:全局概念,即一套分布式云数据中心解决方案内唯一部署。
Region:区域概念,即地理上完全独立的区域。划分:Region是一个以时延为半径的圈:Region内用户获得的前端服务的时延小于100ms。如果大于100ms则要再划分一个region。一般一个region对应一个物理的数据中心。
各个Region通常在不同的地理位置,具有地理容灾等级。
可用分区:Available Zone,简称AZ,是一个物理资源(计算、存储、网络)的分区。
可用分区中的计算、存储、网络资源全互通,用户可以在可用分区(不能跨可用分区)内不受限制地绑定虚拟机与磁盘、网络的关系。
Region可以包含多个AZ。AZ包含于Region,AZ不可跨越Region。一个Region的多个AZ间通过高速光纤相连,以满足用户跨AZ构建高可用性系统的需求。
POD:Type I 专有概念。一个POD是一个OpenStack被级联层,以及被级联层下面的所有资源。
AZ的划分:
不同的虚拟化类型划分成不同的AZ
同一虚拟化划分成几个AZ采用计算池和存储池最小原则,即如果有2个计算池都连接同1套存储池,划分成1个AZ;如果有1个计算池连接了3套存储池,划分成1个AZ
主机组的划分原则是同一虚拟化下具有某些相同特质的主机的集合,例如,主机组中的主机都是KVM虚拟化和高性能CPU
引申:AZ与AZ能否互通?
能
22.为什么会有不同类型的云硬盘?
1、客户的需求
2、后端存储的不同介质
引申:为什么有了SCSI类型的云硬盘还要有VBD类型的云硬盘?
1.因为某些操作系统不支持SCSI的云硬盘。2.即使操作系统支持SCSI类型的云硬盘,还需要安装驱动并且重启,增加了复杂性,对客户来说是不方便的。
对于我的windows来说有装驱动吗?
有。Windows操作系统需要安装UVP VMTools才能支持SCSI。
那对于Linux来说有装驱动吗?
没有。Linux操作系统的SCSI特性不是由UVP VMTools提供,而是操作系统自带的驱动。
24.私有云安装流程
安装前准备:
1、文档:
1)集成设计套件,完成LLD填写(集成套件现在用不了,可以用edesginer)
2)硬件checklist,完成硬件初始配置及检查项
3)fusioncloud6.3产品文档
2、工具:
1)Putty
2)Winscp
3)浏览器
3、软件包
1)FCD.iso
2)FCD工具安装包
3)各组件、云服务软件包(云计算大数据信息服务平台>华为stack软件下载)
安装原理:
FCD自动化安装fusioncloud6.3原理:
1、FCD节点和执行机节点网络互通(通过external-api)
2、FCD节点和待部署环境网络互通(通过internal-base)
3、执行机通过挂载IOS的方式安装FCD节点
4、执行机上传软件包到FCD节点
5、FCD节点自动部署基础管理节点
6、FCD节点自动部署扩展管理节点
7、FCD节点自动部署KVM节点
8、释放FCD节点到KVM计算节点中
1、安装FCD节点
1)安装FCD节点主机操作系统及软件
a、通过BMC登录FCD节点主机
b、挂载FCD.iso镜像
c、重启FCD节点,并进入操作系统安装界面
d、配置external-api网口的IP、vlan、网关和掩码
e、配置时区、主机名和密码
f、重启执行操作系统安装
2)配置FCD节点虚拟网络
a、SSH登录FCD操作系统
b、cd /opt/fusionclouddeploy/fcdscript
c、vim fcd_config.ini
d、修改internal_base和external_om平面的IP地址和vlan,保存退出
e、执行脚本(sh config_fcd_net.sh),部署虚拟网络
f、验证测试网络能否互通
2、安装global和首个AZ
1)使用浏览器登录FCD自动化部署调测工具界面
2)点击工程管理>新建工程
a、填写工程基本信息:
工程名称
业务场景
工程类型
b、部署场景选择(配置基础场景)
部署场景:type类型
region类型:首个region/N个region
是否启动CSDR/CSHA/VHA特性
c、部署场景选择(部署场景和后端存储信息)
管理存储/业务存储
全局业务模型/级联层业务模型/被级联层业务模型
高级选项
d、基础云服务选择
底座:openstack/om
运维运营组件
公共组件
计算服务
基础存储服务
网络服务
e、高级云服务选择
管理服务
混合云
高级存储服务
paas服务
容灾服务
数据服务
安全服务
f、单机创建,进入工程信息页面,核对信息是否一致
3、配置部署参数
1)工程管理>参数配置
2)参数上传,上传填写好的LLD
3)参数汇总导出
4、上传和校验软件包
1)使用winscp工具登录FCD节点操作系统
2)将软件包上传至 /home/pkg目录
3)工程管理>软件包校验界面,软件包检验
检验成功:表示软件包齐全,继续执行安装部署操作
检验失败:表示软件包缺失,上传缺失的软件包
4)工程管理>组件安装界面
单机安装,开始组件安装
5)工程管理>计算节点安装界面
单机全部安装,开始安装计算节点
5、安装完成后调测
使用FCD工具进行自动化调测
6、释放FCD节点到计算节点池
引申:手动安装怎么装?
FusionCloud手动安装:
手动配置PXE服务
手动配置磁盘配置:调整逻辑磁盘所属卷组
手动调整存储资源池:对接存储
手动调整网络配置:
(1)配置业务网络平面,包括:物理网络、网口映射、网络平面
(2)配置存储网络平面,storage_date平面。
引申:我的基础云服务和高级云服务分别有什么?
23.私有云规划部署流程
1、客户调研、需求分析
1)调研客户当前系统中现有的情况,包括当前使用的系统的厂家、版本,以及当前的虚拟化平台等。
2)了解客户现在遇到的问题,并期望达到什么样的目标,比如希望实现分级管理、对原有虚拟化平台的统一接管等要求
2、解决方案选型
1)虚拟化
2)桌面云
3)私有云
a、type1
b、type2
c、type3
3、基础设施配置:
1)涉及管理服务器的设计
a、type1
3个控制节点+两个网络节点+云服务节点
b、type2
3控制节点+3网络节点+云服务节点
c、type3
3控制节点+云服务节点
2)涉及存储的设计
a、管理存储
使用对象:云服务、公共组件使用(manage one、lvs、nginx等等)
存储类型:FS融合部署、IPSAN、FCSAN
b、业务存储
对接计算节点,发布云硬盘、云主机
存储类型:FS、FusionCube(融合一体机,使用的也是FS)、IPSAN、FCSAN)
3)涉及网络的设计
a、type2需要配套的网络设备(SDN)
b、冗余(设备冗余、链路冗余)
4、云服务部署方案设计
根据type类型中支持的基础、高级云服务进行选择,决定部署哪些组件以及如何部署管理虚拟机,公共组件等。
5、资源池规划设计:
1)openstack逻辑拓扑设计:
单region
多region
2)资源池接入设计
是否需要KVM、BMS、计算资源池接入方式
3)管理存储接入方案:
4)计算存储接入方案
5)AZ规划设计(一个AZ中只能够有一种虚拟化类型)
6)网络设计
6、云管理层设计:manageone、oc
7、云备份设计
8、实施部署
9、测试验收
25.磁盘升降配置原理?
变更磁盘类型采用的是后端存储SmartMigration特性实现的。基本流程是:在目标存储上创建一个目标LUN,源LUN和目标LUN之间建立数据迁移关系,迁移分为初始数据同步和变更数据同步,两个过程是独立的。在变更过程中磁盘有数据写入时,源LUN和目标LUN都会写入。数据迁移完成后,交换两个LUN的信息,后续主机的业务只会写入目标LUN。
变更磁盘类型不会中断客户业务,但是迁移过程中对应磁盘可提供的性能会下降,因此建议在业务空闲时执行该操作。
26.SNM是什么?
即消息通知服务,是可靠、可扩展和海量的消息通知服务。
27.HAProxy有什么好处?
1、隐藏内部细节
2、提高安全性,安全隔离
3、内部服务连通到外部
4、高可靠性
5、增加节点效率
28.Region、AZ、VDC比列关系?
region:az=1:m(az和region实际可以m:n,但是华为并没有那么做,原因是因为时延问题)
az:vdc=m:n
一个az可以有多个主机组,也就是1:m
引申:Region可以包含多个AZ。AZ包含于Region,AZ不可跨越Region。一个Region的多个AZ间通过高速光纤相连,以满足用户跨AZ构建高可用性系统的需求。每个AZ包括一个或多主机组。
资源池类型:不同类型计算资源池要划分为不同AZ ,例如裸金属服务器资源池、虚拟机资源池、异构资源池。
可靠性方面:可用分区内的物理资源共享了可靠性故障点,比如共享相同的电源供应、磁盘阵列、交换机等,如果希望业务应用实现跨AZ的可靠性(例如业务应用的VM部署在两个AZ内),需要划分为多个AZ。
云服务器高可用服务(CSHA)为跨AZ容灾,使用云服务器高可用服务时需要规划为主AZ和容灾AZ。
vpc和network可以1:n或者1:1或者没有关系。
29.external_api正反向代理的解释?
在FusionSphere OpenStack中,也采用了正向代理和反向代理的功能。AZ内划分为内部网络区域,AZ外划分为外部网络区域。从AZ内部访问外部,使用的代理方式为正向代理,从外部访问AZ内部,使用的代理方式为反向代理。在正向代理场景下,通过在Apache Httpd程序上配置正向代理功能(下图中标识为ApacheProxy),来提供代理服务。正向代理场景下,AZ内的组件对AZ外的网络访问请求,会发送到ApacheProxy的本地IP,ApacheProxy再将请求通过公共IP转发出去。在反向代理场景下,外部对OpenStack服务的请求,则会先发送到HAProxy的外部公共IP上,HAProxy再通过本地IP,将请求转发到对应服务的相关组件上。其中,AZ内的组件之间的内部互通,也是通过HAProxy进行转发的。哪些服务用到?例如cps使用api反向代理去访问。更换地址,通过反向代理去访问。还有添加OM的反向代理,对接Openstack的keystone或者nova,使用反向代理的地址去访问。
引申:配置“cps_web”后可以通过反向代理登录FusionSphere OpenStack的安装部署界面,配置“vnc”后可以通过反向代理VNC方式登录虚拟机,“system”代表可以通过反向代理访问除了“cps_web”和“vnc”之外的其他剩余服务。
30.运营面是用的什么认证?openstack内部用的什么认证?
运营用的是IAM,openstack用的是keystone
31.Nova-Compute个数?
32.FusionCloud微服务云应用平台是什么?
servicestage,是新一代软件开发、集成、管理和运维的PaaS平台。
33.装OPENSTACK的时候是使用了那个网络平面?
internal-base平面
引申:安装时,FCD作为DHCP服务器,发出的internal-base数据是带tag的(原因是在配置FCD时就已配置好),服务器安装系统时,服务器需要设置为PXE启动,发出的包是不带tag的,所以交换机就要设置为Trunk(原因是后期有多个VLAN需要通过)且PVID为internal-base平面的VLAN ID,FCD会把安装系统的ISO上传到第一台服务器,且自动安装,等第一台服务器安装完成后,那么就由第一台服务器安装后续的控制节点和计算节点,且第一台服务器作为DHCP服务器给其他服务器分配地址,后续其他组件安装是由DMK去做。
引申:那么2个DHCP服务器会不会冲突?
不会,因为FCD安装好第一台节点后,FCD的DHCP服务器不使用了,由第一台服务器的DHCP接替FCD的DHCP继续工作。
34.Service OM和Storage_date都对接存储,对接的存储有什么不同?
Service-OM对接管理接口,storage-data 对接业务接口。
35.DMK?
每个组件都会到dmk上注册一个账号,之后上传软件包,dmk主备部署到控制节点上,其他节点安装组件时由dmk去部署。
36.私有云网口规划问题?
2个网口情况下,可以使用2个网口将管理、业务、存储平面合一部署。
4个网络情况下,可以使用2个网口作为管理和业务平面,2个网口作为我的存储平面。
6个网口情况下,可以使用2个网口作为管理平面,2个网口作为业务平面,2个网口作为存储平面。
37.FM和FSO有什么不同?
兼容性:FM只能对接FC好Vmware,而我们的FSO可以除了FM对接的之外还支持对接hyper-v和kvm
场景上,FM用于云数据中心,FSO用于私有云场景
功能上,我的FSO相对于FM更多的是提供了很多的云服务功能
有待补充。。。
38.SCSI类型的云硬盘支持哪些高级指令?
比如SCSI锁机制,但是SCSI锁需要配合主机组的反亲和性来实现。具体实现原理可以看Huawei Cloud Stack文档的共享盘的SCSI锁机制。
39.FSO中级联故障,被级联有影响吗?
没有,只是不能再发放新业务了,原有业务不会受影响?
40.FSO中的虚拟机有没有VMtools?
有,是在Server OM中发放一台虚拟机并且安装好VMtools,之后将这台虚拟机导出为模版,格式为qcow2,再将该qcow2格式的镜像导入致Server OM中,这样后续发出的ECS就有VMtools了。
41.FusionCare可以检查那些组件?
FusionCompute,FusionManager, FusionStorage,FusionSphereOpenStack和FusionAccess。
42.对接FusionStorage需要填写什么?
FS的URL、存储池名称、复用比、块客户端IP(VBS地址)(看是否启用ISCSI协议)、存储池ID (fusionstorage界面有)、可用分区和节点。
43.Cinder支持什么类型的存储?
目前支持T系列、18000系列、Dorada系列和V3及以上系列存储。
45.管理节点和计算节点需要哪些平面?
管理节点需要哪些网络平面:所有
计算节点:internal-base、external-om 业务平面storage-data。
44.华为云Stack模拟环境链接,感兴趣的可以点击看看。
http://support-it.huawei.com/fusiondeploy/index.html
45.云硬盘的类型有哪些?
1)普通性能:适用于大容量、读写速率要求不高、事务性处理较少的应用场景,例如部署开发测试应用程序等。SATA盘。
2)中等性能:适用于对性能要求不高,但是要求具有丰富的企业级特性场景,适用于普通数据库、应用VM、中间件VM。SAS盘。
3)高性能:适用于对读写速率和带宽吞吐能力要求高的场景,例如数据仓库。普通SSD盘。
4)超高性能:适用于对IO性能密度要求极高,数据密集型的场景,例如NoSQL/SQL数据库。NVMe SSD。
46.manila介绍
47.裸金属服务申请详解:
48.什么是IMS?
镜像是一个包含了软件及必要配置的弹性云服务器模板,至少包含操作系统,还可以包含应用软件(例如,数据库软件)和私有软件。镜像分为公共镜像、私有镜像和共享镜像。
镜像服务(Image Management Service,以下简称IMS)提供简单方便的镜像自助管理功,能。用户可以灵活便捷的使用公共镜像、私有镜像或共享镜像申请弹性云服务器。同时,用户还能通过弹性云服务器或外部镜像文件创建私有镜像。
引申:3种镜像有什么区别?
公共镜像
公共镜像是云平台系统提供的标准镜像,包含常见的标准操作系统和预装的公共应用,能够提供简单方便的镜像自助管理功能,对所有用户可见。用户可以便捷的使用公共镜像创建弹性云服务器或裸金属服务器。
私有镜像
私有镜像是用户基于云服务器创建的个人镜像,仅用户自己可见。包含操作系统、预装的公共应用以及用户的私有应用。通过私有镜像创建云服务器,可以节省您重复配置云服务器的时间。私有镜像分为通过云服务器创建的私有镜像和通过外部镜像文件创建的私有镜像。
通过弹性云服务器创建新的私有镜像。
通过注册外部镜像文件创建新的私有镜像。
共享镜像
当用户将自己的私有镜像共享给其他用户使用时,可以使用镜像服务的共享镜像功能。对于多项目用户,共享镜像功能可以方便用户在同一个区域内的多个项目间使用镜像。
当用户作为共享镜像的提供者时,可以共享指定镜像、取消共享镜像、添加或删除镜像的共享租户。当用户作为共享镜像的接受者时,可以选择接受或者拒绝其他用户提供的共享镜像,也可以移除已经接受的共享镜像。
镜像怎么得到的?
镜像根据创建方式分为以下两种:(1)通过弹性云服务器创建。(2)通过外部镜像文件创建。
- MQ干什么用的,为什么用MQ?
- 可以避免同步通信因某节点瓶颈造成整体性能瓶颈
- 解耦组件间的关系,有利于对各组件之间扩展和增减
- 每个组件可以独立运行一些修订而不影响其他组件间的工作
50.云硬盘的来源有哪些?
4种:
volume -> volume
snapshot -> volume
image -> volume
blank -> volume文章来源:https://www.toymoban.com/news/detail-491269.html
就是云硬盘就到云硬盘、快照到云硬盘、镜像到云硬盘、无(空白)到云硬盘。
具体资料看下面链接:
https://docs.openstack.org/nova/latest/user/block-device-mapping.html
作者:小叶文章来源地址https://www.toymoban.com/news/detail-491269.html
到了这里,关于云计算(虚拟化)面试宝典的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!