目录
(一)前言
(二)categraf作为Daemonset的方式去运行监控k8s组件
(1)1.24版本以下的k8s集群部署方法:
①创建autu.yaml绑定权限
②Daemonset部署categraf采集监控kubelet,kube-proxy
③测试数据是否采集成功
(2)1.24版本以上的k8s集群部署方法:
①创建secret token 绑定sa账号
③测试认证
④Daemonset部署categraf采集监控kubelet,kube-proxy
⑤测试采集是否成功
(三)使用kube-state-metrics监控kubernetes对象
(1)下载配置kube-state-metrices
(2)抓紧KSM指标
①Prometheus-agent抓取
②categraf抓取
(3)监控大盘
(4)分片逻辑
(四)最后的最后
(一)前言
上一期我们讲了我们使用Prometheus-Agent的方式通过endpoint的服务发现功能来抓取metrics信息,但是Prometheus-agent的方式太重了,我们可以使用categraf作为Daemonset的方式去运行,使用categraf的input-Prometheus的插件方式直接填入url即可,相对来说比Prometheus-agent的方式轻,简单一点。
但是categraf的这个插件方式有个缺点就是如果k8s的pod如果物理机出现问题,他pod的IP地址就会飘走那么categraf的插件功能就会失效,如果你的pod的IP地址不稳定,可以使用Prometheus-agent的方式通过endpoint的服务发现功能稳定一点,不用担心物理机的问题。当然这个categraf的服务发现功能会在后面的版本更新出来,大家可以实时的关注夜莺的官网
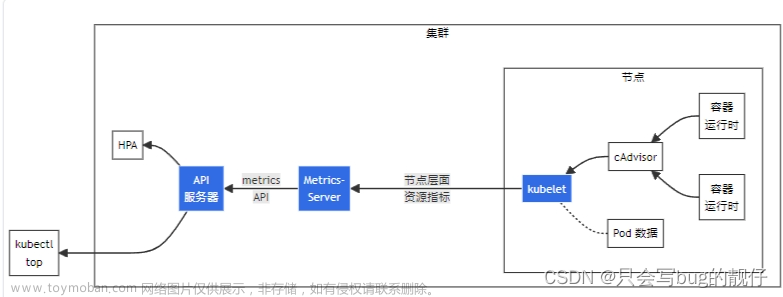
还要一点就是,我们使用daemonset的方式监控k8s组件的时候,只能监控kube-poxy,kubelet这两个组件,因为daemonset是每个节点都挂在pod 但是node节点没有apiserver etcd这些master节点独有的组件,所以只有监控kube-proxy,kubelet这两个node节点和master节点都有的组件。daemonset 监控node上的资源(物理机资源+pod资源(cadvisor)) 。
接下来,我们首先讲一下categraf-Daemonset的方式去运行监控k8s组件,然后我们再说一下使用kube-state-metrics(KSM)的方式去监控k8s的资源,在使用Daemonset和KSM的时候,我做的时候发现了有一些小坑,这篇文章都给大家一起解决
(二)categraf作为Daemonset的方式去运行监控k8s组件
当我们使用Daemonset方式去采集监控的时候,就设计到了kubelet需要认证权限的问题,这里要通过ServiceAccount账号绑定对应的权限给categraf使用,但是在部署的时候,因为我使用的k8s的版本是1.25,1.24的版本以上k8s取消了ServiceAccount账号自动绑定secrets的功能,如果需要给ServiceAccount绑定secrets,要自己手动去创建secrets token然后绑定给指定的sa

(1)1.24版本以下的k8s集群部署方法:
采集kube-proxy组件时,不需要额外的认证权限,采集kubelet的时候则需要。这里我们可以先做个测试不通过认证直接访问,看看能不能查看到metrics的信息
## Kubelet 监听两个固定端口(我的环境,你的环境可能不同),一个是10248,一个是10250,通过下面的命令可以知道,10248是健康检查的端口:
[root@k8s-master ~]# ss -ntpl | grep kubelet
LISTEN 0 128 127.0.0.1:10248 *:* users:(("kubelet",pid=1935,fd=24))
LISTEN 0 128 [::]:10250 [::]:* users:(("kubelet",pid=1935,fd=30))
[root@k8s-master ~]# curl localhost:10248/healthz
ok
## 我们再看一下 10250,10250实际是Kubelet的默认端口
[root@k8s-master ~]# curl https://localhost:10250/metrics
curl: (60) Peer's certificate issuer has been marked as not trusted by the user.
More details here: http://curl.haxx.se/docs/sslcerts.html
curl performs SSL certificate verification by default, using a "bundle"
of Certificate Authority (CA) public keys (CA certs). If the default
bundle file isn't adequate, you can specify an alternate file
using the --cacert option.
If this HTTPS server uses a certificate signed by a CA represented in
the bundle, the certificate verification probably failed due to a
problem with the certificate (it might be expired, or the name might
not match the domain name in the URL).
If you'd like to turn off curl's verification of the certificate, use
the -k (or --insecure) option.
[root@k8s-master ~]# curl -k https://localhost:10250/metrics
Unauthorized
## 最后的命令可以看到返回了 Unauthorized,表示认证失败,我们先来解决一下认证问题。
最后的命令可以看到返回了 Unauthorized,表示认证失败,我们先来解决一下认证问题。
①创建autu.yaml绑定权限
下面的信息可以保存为 auth.yaml,创建了 ClusterRole、ServiceAccount、ClusterRoleBinding。
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: categraf-daemonset
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
- nodes/stats
- nodes/proxy
verbs:
- get
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: categraf-daemonset
namespace: flashcat
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: categraf-daemonset
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: categraf-daemonset
subjects:
- kind: ServiceAccount
name: categraf-daemonset
namespace: flashcatClusterRole是个全局概念,不属于任一个namespace,定义了很多权限点,都是读权限,监控嘛,读权限就可以了,ServiceAccount则是namespace颗粒度的一个概念,这里我们创建了一个名为categraf-daemonset的ServiceAccount,然后绑定到ClusterRole上面,具备了各种查询权限。apply一下即可:
[work@tt-fc-dev01.nj yamls]$ kubectl apply -f auth.yaml
clusterrole.rbac.authorization.k8s.io/categraf-daemonset created
serviceaccount/categraf-daemonset created
clusterrolebinding.rbac.authorization.k8s.io/categraf-daemonset created
[work@tt-fc-dev01.nj yamls]$ kubectl get ClusterRole | grep categraf-daemon
categraf-daemonset 2022-11-14T03:53:54Z
[work@tt-fc-dev01.nj yamls]$ kubectl get sa -n flashcat
NAME SECRETS AGE
categraf-daemonset 1 90m
default 1 4d23h
[work@tt-fc-dev01.nj yamls]$ kubectl get ClusterRoleBinding -n flashcat | grep categraf-daemon
categraf-daemonset ClusterRole/categraf-daemonset 91m我们已经成功创建了 ServiceAccount,把ServiceAccount的内容打印出来看一下,可以发现sa账号自动绑定了一个secrets文件:
[root@tt-fc-dev01.nj qinxiaohui]# kubectl get sa categraf-daemonset -n flashcat -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","kind":"ServiceAccount","metadata":{"annotations":{},"name":"categraf-daemonset","namespace":"flashcat"}}
creationTimestamp: "2022-11-14T03:53:54Z"
name: categraf-daemonset
namespace: flashcat
resourceVersion: "120570510"
uid: 22f5a785-871c-4454-b82e-12bf104450a0
secrets:
- name: categraf-daemonset-token-7mccq注意最后两行,这个ServiceAccount实际是关联了一个Secret,我们再看看这个Secret的内容:
[root@tt-fc-dev01.nj qinxiaohui]# kubectl get secret categraf-daemonset-token-7mccq -n flashcat -o yaml
apiVersion: v1
data:
ca.crt: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUMvakNDQWVhZ0F3SUJBZ0lCQURBTkJna3Foa2lHOXcwQkFRc0ZBREFWTVJNd0VRWURWUVFERXdwcmRXSmwKY201bGRHVnpNQjRYRFRJeU1ERXdPVEF4TXpjek9Gb1hEVE15TURFd056QXhNemN6T0Zvd0ZURVRNQkVHQTFVRQpBeE1LYTNWaVpYSnVaWFJsY3pDQ0FTSXdEUVlKS29aSWh2Y05BUUVCQlFBRGdnRVBBRENDQVFvQ2dnRUJBS2F1Ck9wU3hHdXB0ZlNraW1zbmlONFVLWnp2b1p6akdoTks1eUVlZWFPcmptdXIwdTFVYlFHbTBRWlpMem8xVi9GV1gKVERBOUthcFRNVllyS2hBQjNCVXdqdGhCaFp1NjJVQzg5TmRNSDVzNFdmMGtMNENYZWQ3V2g2R05Md0MyQ2xKRwp3Tmp1UkZRTndxMWhNWjY4MGlaT1hLZk1NbEt6bWY4aDJWZmthREdpVHk0VzZHWE5sRlRJSFFkVFBVMHVMY3dYCmc1cUVsMkd2cklmd05JSXBOV3ZoOEJvaFhyc1pOZVNlNHhGMVFqY0R2QVE4Q0xta2J2T011UGI5bGtwalBCMmsKV055RTVtVEZCZ2NCQ3dzSGhjUHhyN0E3cXJXMmtxbU1MbUJpc2dHZm9ieXFWZy90cTYzS1oxYlRvWjBIbXhicQp6TkpOZUJpbm9jbi8xblJBK3NrQ0F3RUFBYU5aTUZjd0RnWURWUjBQQVFIL0JBUURBZ0trTUE4R0ExVWRFd0VCCi93UUZNQU1CQWY4d0hRWURWUjBPQkJZRUZLVkxrbVQ5RTNwTmp3aThsck5UdXVtRm1MWHNNQlVHQTFVZEVRUU8KTUF5Q0NtdDFZbVZ5Ym1WMFpYTXdEUVlKS29aSWh2Y05BUUVMQlFBRGdnRUJBSm5QR24rR012S1ZadFVtZVc2bQoxanY2SmYvNlBFS2JzSHRkN2dINHdwREI3YW9pQVBPeTE0bVlYL2d5WWgyZHdsRk9hTWllVS9vUFlmRDRUdGxGCkZMT08yVkdLVTJBSmFNYnVBekw4ZTlsTFREM0xLOGFJUm1FWFBhQkR2V3VUYXZuSTZCWDhiNUs4SndraVd0R24KUFh0ejZhOXZDK1BoaWZDR0phMkNxQWtJV0Nrc0lWenNJcWJ0dkEvb1pHK1dhMlduemFlMC9OUFl4QS8waldOMwpVcGtDWllFaUQ4VlUwenRIMmNRTFE4Z2Mrb21uc3ljaHNjaW5KN3JsZS9XbVFES3ZhVUxLL0xKVTU0Vm1DM2grCnZkaWZtQStlaFZVZnJaTWx6SEZRbWdzMVJGMU9VczNWWUd0REt5YW9uRkc0VFlKa1NvM0IvRlZOQ0ZtcnNHUTYKZWV3PQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==
namespace: Zmxhc2hjYXQ=
token: ZXlKaGJHY2lPaUpTVXpJMU5pSXNJbXRwWkNJNklqRTJZVTlNU2pObFFVbEhlbmhDV1dsVmFIcEVTRlZVWVdoZlZVaDZSbmd6TUZGZlVWUjJUR0pzVUVraWZRLmV5SnBjM01pT2lKcmRXSmxjbTVsZEdWekwzTmxjblpwWTJWaFkyTnZkVzUwSWl3aWEzVmlaWEp1WlhSbGN5NXBieTl6WlhKMmFXTmxZV05qYjNWdWRDOXVZVzFsYzNCaFkyVWlPaUptYkdGemFHTmhkQ0lzSW10MVltVnlibVYwWlhNdWFXOHZjMlZ5ZG1salpXRmpZMjkxYm5RdmMyVmpjbVYwTG01aGJXVWlPaUpqWVhSbFozSmhaaTFrWVdWdGIyNXpaWFF0ZEc5clpXNHROMjFqWTNFaUxDSnJkV0psY201bGRHVnpMbWx2TDNObGNuWnBZMlZoWTJOdmRXNTBMM05sY25acFkyVXRZV05qYjNWdWRDNXVZVzFsSWpvaVkyRjBaV2R5WVdZdFpHRmxiVzl1YzJWMElpd2lhM1ZpWlhKdVpYUmxjeTVwYnk5elpYSjJhV05sWVdOamIzVnVkQzl6WlhKMmFXTmxMV0ZqWTI5MWJuUXVkV2xrSWpvaU1qSm1OV0UzT0RVdE9EY3hZeTAwTkRVMExXSTRNbVV0TVRKaVpqRXdORFExTUdFd0lpd2ljM1ZpSWpvaWMzbHpkR1Z0T25ObGNuWnBZMlZoWTJOdmRXNTBPbVpzWVhOb1kyRjBPbU5oZEdWbmNtRm1MV1JoWlcxdmJuTmxkQ0o5Lm03czJ2Z1JuZDJzMDJOUkVwakdpc0JYLVBiQjBiRjdTRUFqb2RjSk9KLWh6YWhzZU5FSDFjNGNDbXotMDN5Z1Rkal9NT1VKaWpCalRmaW9FSWpGZHRCS0hEMnNjNXlkbDIwbjU4VTBSVXVDemRYQl9tY0J1WDlWWFM2bE5zYVAxSXNMSGdscV9Sbm5XcDZaNmlCaWp6SU05QUNuckY3MGYtd1FZTkVLc2MzdGhubmhSX3E5MkdkZnhmdGU2NmhTRGthdGhPVFRuNmJ3ZnZMYVMxV1JCdEZ4WUlwdkJmVXpkQ1FBNVhRYVNPck00RFluTE5uVzAxWDNqUGVZSW5ka3NaQ256cmV6Tnp2OEt5VFRTSlJ2VHVKMlZOU2lHaDhxTEgyZ3IzenhtQm5Qb1d0czdYeFhBTkJadG0yd0E2OE5FXzY0SlVYS0tfTlhfYmxBbFViakwtUQ==
kind: Secret
metadata:
annotations:
kubernetes.io/service-account.name: categraf-daemonset
kubernetes.io/service-account.uid: 22f5a785-871c-4454-b82e-12bf104450a0
creationTimestamp: "2022-11-14T03:53:54Z"
name: categraf-daemonset-token-7mccq
namespace: flashcat
resourceVersion: "120570509"
uid: 0a228da5-6e60-4b22-beff-65cc56683e41
type: kubernetes.io/service-account-token我们把这个token字段拿到,然后base64转码一下,作为Bearer Token来请求测试一下:
[root@tt-fc-dev01.nj qinxiaohui]# token=`kubectl get secret categraf-daemonset-token-7mccq -n flashcat -o jsonpath={.data.token} | base64 -d`
[root@tt-fc-dev01.nj qinxiaohui]# curl -s -k -H "Authorization: Bearer $token" https://localhost:10250/metrics > aaaa
[root@tt-fc-dev01.nj qinxiaohui]# head -n 5 aaaa
# HELP apiserver_audit_event_total [ALPHA] Counter of audit events generated and sent to the audit backend.
# TYPE apiserver_audit_event_total counter
apiserver_audit_event_total 0
# HELP apiserver_audit_requests_rejected_total [ALPHA] Counter of apiserver requests rejected due to an error in audit logging backend.
# TYPE apiserver_audit_requests_rejected_total counter
apiserver_audit_requests_rejected_total 0通了!
这就说明我们创建的ServiceAccount是好使的,后面我们把 Categraf 作为采集器搞成 Daemonset,再为 Categraf 这个 Daemonset 指定 ServiceAccountName,Kubernetes就会自动把 Token 的内容挂到 Daemonset 的目录里
②Daemonset部署categraf采集监控kubelet,kube-proxy
首先我们先创建categraf的配置文件comfigmap,配置我们的n9e的地址和input-Prometheus插件的配置。
vim categraf-configmap.yaml
---
kind: ConfigMap
metadata:
name: categraf-config
apiVersion: v1
data:
config.toml: |
[global]
hostname = "$HOSTNAME"
interval = 15
providers = ["local"]
[writer_opt]
batch = 2000
chan_size = 10000
[[writers]]
url = "http://10.206.0.16:19000/prometheus/v1/write"
## 这里配置的是你n9e的地址
timeout = 5000
dial_timeout = 2500
max_idle_conns_per_host = 100
---
kind: ConfigMap
metadata:
name: categraf-input-prometheus
apiVersion: v1
data:
prometheus.toml: |
## 这里每一个instances表示一个字段,采集监控的目标
[[instances]]
urls = ["http://127.0.0.1:10249/metrics"]
labels = { job="kube-proxy" }
[[instances]]
urls = ["https://127.0.0.1:10250/metrics"]
bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token" ##这个是认证secrets token的地址
use_tls = true
insecure_skip_verify = true ## 是否跳过认证
labels = { job="kubelet" } ##打标签
[[instances]]
urls = ["https://127.0.0.1:10250/metrics/cadvisor"]
bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"
use_tls = true
insecure_skip_verify = true
labels = { job="cadvisor" } 然后apply一下 生成配置:
[work@tt-fc-dev01.nj yamls]$ kubectl apply -f categraf-configmap.yaml -n flashcat
configmap/categraf-config unchanged
configmap/categraf-input-prometheus configured接下来就是创建categraf的Daemonset了,需要添加上ServiceAccount我们创建的sa账号
vim categraf-daemonset.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app: categraf-daemonset
name: categraf-daemonset
spec:
selector:
matchLabels:
app: categraf-daemonset
template:
metadata:
labels:
app: categraf-daemonset
spec:
containers:
- env:
- name: TZ
value: Asia/Shanghai
- name: HOSTNAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
- name: HOSTIP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.hostIP
image: flashcatcloud/categraf:v0.2.18
imagePullPolicy: IfNotPresent
name: categraf
volumeMounts:
- mountPath: /etc/categraf/conf
name: categraf-config
- mountPath: /etc/categraf/conf/input.prometheus
name: categraf-input-prometheus
hostNetwork: true
serviceAccountName: categraf-daemonset ## sa账号
restartPolicy: Always
tolerations:
- effect: NoSchedule
operator: Exists
volumes:
- configMap:
name: categraf-config
name: categraf-config
- configMap:
name: categraf-input-prometheus
name: categraf-input-prometheusapply创建即可
[work@tt-fc-dev01.nj yamls]$ kubectl apply -f categraf-daemonset.yaml -n flashcat
daemonset.apps/categraf-daemonset created
# waiting...
[work@tt-fc-dev01.nj yamls]$ kubectl get pods -n flashcat
NAME READY STATUS RESTARTS AGE
categraf-daemonset-d8jt8 1/1 Running 0 37s
categraf-daemonset-fpx8v 1/1 Running 0 43s
categraf-daemonset-mp468 1/1 Running 0 32s
categraf-daemonset-s775l 1/1 Running 0 40s
categraf-daemonset-wxkjk 1/1 Running 0 47s
categraf-daemonset-zwscc 1/1 Running 0 35s③测试数据是否采集成功
测试指标:kubelet_running_pods 如果你还想知道其他的更改的指标,可以看一下我上一篇文件的kubele组件监控最后
列出了常规经常用的一些指标:夜莺(Flashcat)V6监控(五):夜莺监控k8s

当然监控大盘也有,对应的json文件也在我上一篇文章里,感兴趣的可以去导入kubelet监控仪表盘,怎么导入仪表盘也在上一篇讲解了:夜莺(Flashcat)V6监控(五):夜莺监控k8s组件(上)
这里pod容器相关的仪表盘的json文件地址:categraf/pod-dash.n · flashcatcloud/categraf · GitHub

(2)1.24版本以上的k8s集群部署方法:
①创建secret token 绑定sa账号
因为1.24版本以上k8s取消了sa账号自动绑定secrets token的功能,所以这里我们先创建一个sa然后再手动去绑定secret
kubectl create sa categraf-daemonset -n flashcat
##创建sa账号
kubectl create token categraf-daemonset -n flashcat
## 创建指定sa的token然后创建secret指定我们的sa账号
vim categraf-daemonset-secre.yaml
apiVersion: v1
kind: Secret
metadata:
name: categraf-daemonset-secret
namespace: flashcat
annotations:
kubernetes.io/service-account.name: categraf-daemonset
type: kubernetes.io/service-account-token更改我们创建的sa账号指定我们的这个secret
[root@k8s-master ~]# kubectl edit sa categraf-daemonset -n flashcat
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: "2023-05-16T06:37:55Z"
name: categraf-daemonset
namespace: flashcat
resourceVersion: "521218"
uid: abd1736b-c12c-4e76-a752-c1dcca9b22be
secrets:
- name: categraf-daemonset-secret ##添加这两行 指定我们的secret
然后我们查看是否绑定成功
[root@k8s-master ~]# kubectl get sa -n flashcat
NAME SECRETS AGE
categraf-daemonset 1 2d23h
default 0 5d21h
## 这里secrets 有1 就说明绑定上了
## 我们可以通过命令查看
[root@k8s-master ~]# kubectl get sa categraf-daemonset -n flashcat -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: "2023-05-16T06:37:55Z"
name: categraf-daemonset
namespace: flashcat
resourceVersion: "521218"
uid: abd1736b-c12c-4e76-a752-c1dcca9b22be
secrets:
- name: categraf-daemonset-secret
[root@k8s-master ~]# kubectl get secrets categraf-daemonset-secret -o yaml -n flashcat
apiVersion: v1
data:
ca.crt: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUMvakNDQWVhZ0F3SUJBZ0lCQURBTkJna3Foa2lHOXcwQkFRc0ZBREFWTVJNd0VRWURWUVFERXdwcmRXSmwKY201bGRHVnpNQjRYRFRJek1ETXlNVEUxTVRRME9Wb1hEVE16TURNeE9ERTFNVFEwT1Zvd0ZURVRNQkVHQTFVRQpBeE1LYTNWaVpYSnVaWFJsY3pDQ0FTSXdEUVlKS29aSWh2Y05BUUVCQlFBRGdnRVBBRENDQVFvQ2dnRUJBTWlkCmNvUkRHTUsvZEcxSmRCVkZVbUxmZzF4YUs4SkxFOS9TTk5aTHYzUFYyWWdNQ3VuMExYSmEzdzV0STlNME04R2QKV3RaMnpsZW4rNWdTM3ZMbDVrd3piK1pla3I5TGpCQmN5ajczbW5lYVV4NW5SUlQvT085UERaVzBYaFNyenJ0QwpYQ3ZmNFJob05kRk1SWXlwSUF1VGFKNHhHQ2x4eU05cTlGaytreCtITGFPcnJVQ1ZUYk1wQXYyNm5DY1BjaWdrCjM3aXlnOEp5c3hXYk51UmhwYWp1Z2g3ODRsOHpNVHlidUdiNHZpMWFmQStGRXJtNGNWQnY5L0NqeDhvdFdlY1cKc1YxZW9VKzR2d2p4RFQwS1RuVHZ1cmdRTnpoVW5NcXRjcDZZdldGekpPSnE0SWs1RlM1d2ZaVVlCbGt2eGo0UQp3TmNaVGFGREVtTVFHdWY0NWNNQ0F3RUFBYU5aTUZjd0RnWURWUjBQQVFIL0JBUURBZ0trTUE4R0ExVWRFd0VCCi93UUZNQU1CQWY4d0hRWURWUjBPQkJZRUZNb3c5N3ZoTlNSVVJJV0VJWm0xSGRYR0ZjdEhNQlVHQTFVZEVRUU8KTUF5Q0NtdDFZbVZ5Ym1WMFpYTXdEUVlKS29aSWh2Y05BUUVMQlFBRGdnRUJBRTRJeHZ6OFVsWU9uZGVYRW9nWApsSE5QN0FsNno2QnZjRU54K1g5OVJrMDI2WGNaaUJqRmV0ZjhkMlhZWlhNSVVub3poSU5RNFNyRlpOR3lGeUtRCjZqelVUVjdhR2pKczJydnI1aDBJazFtTVU5VXJMVGJCSk5GOExqall2bVlyTEY5OTM4SldRRFVFSGhCaTJ0NW0KWFcyYS8vZkJ2ZHF3SkhPSDVIU082RUZFU2NjT05EZU5aQWhZTnJEMjZhZDU0c0U3Ti9adDcxenFjMHZ4SFdvRQpuQlZZOVBTcGRKTm1WWjgzL1FjbHViMWRhREpzR1R2UDJLdU1OTy9EcEQwa0Q2bHFuQmR1VndubHp2cFlqYXhUCnFXVCs0UHJ2OXM5RE91MXowYlMzUW1JM0E0cGtFM1JYdFBZUXN0Vmw1OXg1djM4QjI5U0lnNGl1SU1EZ1JPcXkKSzNJPQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==
namespace: Zmxhc2hjYXQ=
token: ZXlKaGJHY2lPaUpTVXpJMU5pSXNJbXRwWkNJNklrZ3hhVlpXUkhacVMyOUhNSFpNWTAxVFVFeFhOa3hFUkhoWlFYTjJia1l3WVVKWU1HMWpTRGhLT1VVaWZRLmV5SnBjM01pT2lKcmRXSmxjbTVsZEdWekwzTmxjblpwWTJWaFkyTnZkVzUwSWl3aWEzVmlaWEp1WlhSbGN5NXBieTl6WlhKMmFXTmxZV05qYjNWdWRDOXVZVzFsYzNCaFkyVWlPaUptYkdGemFHTmhkQ0lzSW10MVltVnlibVYwWlhNdWFXOHZjMlZ5ZG1salpXRmpZMjkxYm5RdmMyVmpjbVYwTG01aGJXVWlPaUpqWVhSbFozSmhaaTFrWVdWdGIyNXpaWFF0YzJWamNtVjBJaXdpYTNWaVpYSnVaWFJsY3k1cGJ5OXpaWEoyYVdObFlXTmpiM1Z1ZEM5elpYSjJhV05sTFdGalkyOTFiblF1Ym1GdFpTSTZJbU5oZEdWbmNtRm1MV1JoWlcxdmJuTmxkQ0lzSW10MVltVnlibVYwWlhNdWFXOHZjMlZ5ZG1salpXRmpZMjkxYm5RdmMyVnlkbWxqWlMxaFkyTnZkVzUwTG5WcFpDSTZJbUZpWkRFM016WmlMV014TW1NdE5HVTNOaTFoTnpVeUxXTXhaR05qWVRsaU1qSmlaU0lzSW5OMVlpSTZJbk41YzNSbGJUcHpaWEoyYVdObFlXTmpiM1Z1ZERwbWJHRnphR05oZERwallYUmxaM0poWmkxa1lXVnRiMjV6WlhRaWZRLkFnTmwyNkMzUHg4ekE1Z0tGRDJya0N3Vzl6aS11ZzBQdnFMSnBUNEZ4QmFyTTVtSmE1VGlpQ1o5RzNKQmgtMm4tcTcwbHBPMVZLSUQzaGJMNzBIV3p6cEdKdThTUEZNeFN3OVRYTjhleFp3ZFVmcGVtbXF6azZvV3owRzBNbXVJSHFpRWJIVHNOZnluNEhDWHhHZmJRX0tmaDNEaURESThkYTBRdldLaWd0NTBMS0lRQlVFT3ZwSnpURVh1YmFxWHExbFdnV1VBQ0VPTktYZmxzbWEweDEwdUExY1JkOXF1UzdEWE93cWRnLUF1NGZVb0lmTTdRcTZyeEFFT2pXQnJWbmNYV1VzSnlNbk5uM0xQMXBWVUFCa21wQzFjYVJkSVB5bHBLYnpHaVlwSlloRjJKT3BwRWU2SUZsYTNwX1NHeVp5WUV2UkpPNXJNVVhTSWZJTnZMZw==
kind: Secret
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","kind":"Secret","metadata":{"annotations":{"kubernetes.io/service-account.name":"categraf-daemonset"},"name":"categraf-daemonset-secret","namespace":"flashcat"},"type":"kubernetes.io/service-account-token"}
kubernetes.io/service-account.name: categraf-daemonset
kubernetes.io/service-account.uid: abd1736b-c12c-4e76-a752-c1dcca9b22be
creationTimestamp: "2023-05-16T06:39:26Z"
name: categraf-daemonset-secret
namespace: flashcat
resourceVersion: "520851"
uid: 1095820e-c420-47c4-9a52-c051c19b9f17
type: kubernetes.io/service-account-token
②给sa账号权限
然后创建我们的权限绑定我们的sa账号,让我们的sa账号有对我们k8s集群查看采集metrices的权限
vim categraf-daemonset-rbac.yaml
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: categraf-daemonset
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/metrics
- nodes/stats
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
- networking.k8s.io
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics", "/metrics/cadvisor"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: categraf-daemonset
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: categraf-daemonset
subjects:
- kind: ServiceAccount
name: categraf-daemonset ##这里是我们绑定的sa
namespace: flashcat
kubectl apply -f categraf-daemonset-rbac.yaml③测试认证
创建完成后,我们base64转码测试一下我们创建绑定的secrets token是否生效
[root@k8s-master daemonset]# token=`kubectl get secret categraf-daemonset-secret -n flashcat -o jsonpath={.data.token} | base64 -d`
[root@k8s-master daemonset]# curl -s -k -H "Authorization: Bearer $token" https://localhost:10250/metrics > aaaa
[root@k8s-master daemonset]# head -n 5 aaaa
# HELP apiserver_audit_event_total [ALPHA] Counter of audit events generated and sent to the audit backend.
# TYPE apiserver_audit_event_total counter
apiserver_audit_event_total 0
# HELP apiserver_audit_requests_rejected_total [ALPHA] Counter of apiserver requests rejected due to an error in audit logging backend.
# TYPE apiserver_audit_requests_rejected_total counter
最后把我们的token通过base64永久保存到一个指定的文件里面,这样我们我在categraf的input-Prometheus的配置文件里面可以直接引用我们的token采集metrices
kubectl get secret categraf-daemonset-secret -n flashcat -o jsonpath='{.data.token}' | base64 -d > /var/run/secrets/kubernetes.io/serviceaccount/token④Daemonset部署categraf采集监控kubelet,kube-proxy
接下来的操作就跟上面1.24版本以下一样了,配置categraf的配置文件,然后启动categraf-daemonset就可以了
首先创建配置我们的categraf的配置文件的configmap
---
kind: ConfigMap
metadata:
name: categraf-config
apiVersion: v1
data:
config.toml: |
[global]
hostname = "$HOSTNAME"
interval = 15
providers = ["local"]
[writer_opt]
batch = 2000
chan_size = 10000
[[writers]]
url = "http://192.168.120.17:17000/prometheus/v1/write"
timeout = 5000
dial_timeout = 2500
max_idle_conns_per_host = 100
---
kind: ConfigMap
metadata:
name: categraf-input-prometheus
apiVersion: v1
data:
prometheus.toml: |
[[instances]]
urls = ["http://127.0.0.1:10249/metrics"]
labels = { job="kube-proxy" }
[[instances]]
urls = ["https://127.0.0.1:10250/metrics"]
bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"
use_tls = true
insecure_skip_verify = true
labels = { job="kubelet" }
[[instances]]
urls = ["https://127.0.0.1:10250/metrics/cadvisor"]
bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"
## 这里的token地址就是我们上面base64转码后把token放在的那个文件里面的路径
use_tls = true
insecure_skip_verify = true
labels = { job="cadvisor" }
kubectl apply -f categraf-configmap-v2.yaml -n flashcat
然后创建我们的daemonset的yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app: categraf-daemonset
name: categraf-daemonset
spec:
selector:
matchLabels:
app: categraf-daemonset
template:
metadata:
labels:
app: categraf-daemonset
spec:
containers:
- env:
- name: TZ
value: Asia/Shanghai
- name: HOSTNAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
- name: HOSTIP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.hostIP
image: flashcatcloud/categraf:v0.2.18
imagePullPolicy: IfNotPresent
name: categraf
volumeMounts:
- mountPath: /etc/categraf/conf
name: categraf-config
- mountPath: /etc/categraf/conf/input.prometheus
name: categraf-input-prometheus
hostNetwork: true
serviceAccountName: categraf-daemonset
restartPolicy: Always
tolerations:
- effect: NoSchedule
operator: Exists
volumes:
- configMap:
name: categraf-config
name: categraf-config
- configMap:
name: categraf-input-prometheus
name: categraf-input-prometheus
kubectl apply -f categraf-daemonset-v2.yaml -n flashcat然后都apply 一下,让配置生成就可以了
[root@k8s-master daemonset]# kubectl get pod -n flashcat
NAME READY STATUS RESTARTS AGE
categraf-daemonset-26rsz 1/1 Running 0 3h36m
categraf-daemonset-7qc6p 1/1 Running 0 3h36m
⑤测试采集是否成功
测试指标:kubelet_running_pods 如果你还想知道其他的更改的指标,可以看一下我上一篇文件的kubele组件监控最后
列出了常规经常用的一些指标:夜莺(Flashcat)V6监控(五):夜莺监控k8s
当然监控大盘也有,对应的json文件也在我上一篇文章里,感兴趣的可以去导入kubelet监控仪表盘,怎么导入仪表盘也在上一篇讲解了:夜莺(Flashcat)V6监控(五):夜莺监控k8s组件(上)
这里pod容器相关的仪表盘的json文件地址:categraf/pod-dash.n · flashcatcloud/categraf · GitHub
(三)使用kube-state-metrics监控kubernetes对象
kube-state-metrics Github地址:kubernetes/kube-state metrics. (github.com)
前面的系列文章我们花费了大量篇幅介绍了 Kubernetes 各个组件的监控指标,Node 节点上的 Kube-Proxy、Kubelet,Master 节点的 APIServer、Controller-manager、Scheduler、ETCD。但是,如果我想知道总共有几个 Namespace,有几个 Service、Deployment、Statefulset,某个 Deployment 期望有几个 Pod 要运行,实际有几个 Pod 在运行,这些既有的指标就无法回答了。
这些信息需要读取 Kubernetes 的 Metadata 才可以,有需求就有解,KSM就是专门解决这个需求。KSM 会调用 kube-apiserver 的接口,监听各个 Kubernetes 对象的状态,生成指标暴露出来。
Kube-state-metrics 提供了以下功能:
- 实时监控集群状态,包括资源使用情况、网络性能和安全性等指标。
- 自动收集和存储数据,无需手动重启节点或应用程序。
- 通过扩展点,可以在集群中添加更多的节点,以提高监控覆盖率。
- 提供报警功能,以及通过图表和警报等可视化工具来可视化监控数据。
- 支持多种数据格式和频率,以适应不同的需求
下面我们部署测试一下。
(1)下载配置kube-state-metrices
KSM 既然要访问 APIServer,读取相关的信息,那就需要有权限控制,需要有 ServiceAccount、ClusterRole、ClusterRoleBinding 这些东西。在 KSM 的代码仓库中可以直接找到这些 yaml,而且还有 deployment 和 service 相关的 yaml,一步到位:
这里我们可以直接把包全部下到本地然后把examples文件导入我们的linux里 也可以直接在GitHub里面把examples文件的standard目录下的yaml文件都复制到我们linux

把standard文件夹传到我们linux服务器里面


这里需要配置我们的时区还有镜像,这里默认的镜像- image: registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.8.2 这个镜像用的k8s的官方的镜像站,在我们国内根本拉不下来,这里我们可以通过kube-state-metrices的GitHub项目自己构建一个镜像站来生成kube-state-metrices镜像
这里我自己构建了一个,大家可以拿来直接使用 :
registry.cn-qingdao.aliyuncs.com/dream-1/dream-ksm:v2.8.2
也可以自己构建,手把手的构建方式我在我的一篇博客里写出来了,大家可以参考一下:
(一) Docker Hub网站仓库国内进不去了?手把手教你通过GitHub项目构建自己的镜像仓库站!_Dream云原生梦工厂的博客-CSDN博客
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.8.2
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: kube-state-metrics
template:
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.8.2
spec:
automountServiceAccountToken: true
containers:
- image: registry.cn-qingdao.aliyuncs.com/dream-1/dream-ksm:v2.8.2
## 这里为我们自己构建的kube-state-metrices镜像地址
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
name: kube-state-metrics
env:
- name: TZ
value: Asia/Shanghai ## 这里三行的时区要同步加上去
ports:
- containerPort: 8080
name: http-metrics
- containerPort: 8081
name: telemetry
readinessProbe:
httpGet:
path: /
port: 8081
initialDelaySeconds: 5
timeoutSeconds: 5
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
readOnlyRootFilesystem: true
runAsUser: 65534
nodeSelector:
kubernetes.io/os: linux
serviceAccountName: kube-state-metrics
然后apply一下这个文件夹里面所有的yaml文件就可以了
kubectl apply -f standard/细心的小伙伴肯定发现了,ksm在service文件中暴露了两个http端口8081,8080:
vim service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.8.2
name: kube-state-metrics
namespace: kube-system
spec:
clusterIP: None
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
- name: telemetry
port: 8081
targetPort: telemetry
selector:
app.kubernetes.io/name: kube-state-metrics
8080 端口返回的内容就是各类 Kubernetes 对象信息,比如 node 相关的信息;
8081 端口,暴露的是 KSM 自身的指标,KSM 要调用 APIServer 的接口,watch 相关数据,需要度量这些动作的健康状况
这里我们也可以直接curl测试一下,这里的IP地址必须是你pod暴露出来的IP地址才能采集查看到。
[root@k8s-master ~]# kubectl get pod -A -o wide | grep kube-state
kube-system kube-state-metrics-58b98984fc-nk9rm 1/1 Running 2 (4h14m ago) 18h 10.95.156.119 k8s-node1 <none> <none>
[root@k8s-master ~]# kubectl get endpoints -A | grep kube-state
kube-system kube-state-metrics 10.95.156.119:8081,10.95.156.119:8080 21h
[root@k8s-master ~]#curl 10.95.156.119:8080/metrics
# HELP kube_certificatesigningrequest_annotations Kubernetes annotations converted to Prometheus labels.
# TYPE kube_certificatesigningrequest_annotations gauge
# HELP kube_certificatesigningrequest_labels [STABLE] Kubernetes labels converted to Prometheus labels.
# TYPE kube_certificatesigningrequest_labels gauge
# HELP kube_certificatesigningrequest_created [STABLE] Unix creation timestamp
# TYPE kube_certificatesigningrequest_created gauge
# HELP kube_certificatesigningrequest_condition [STABLE] The number of each certificatesigningrequest condition
# TYPE kube_certificatesigningrequest_condition gauge
# HELP kube_certificatesigningrequest_cert_length [STABLE] Length of the issued cert
# TYPE kube_certificatesigningrequest_cert_length gauge
# HELP kube_configmap_annotations Kubernetes annotations converted to Prometheus labels.
# TYPE kube_configmap_annotations gauge
kube_configmap_annotations{namespace="kube-system",configmap="extension-apiserver-authentication"} 1
kube_configmap_annotations{namespace="kube-system",configmap="kube-proxy"} 1
kube_configmap_annotations{namespace="flashcat",configmap="categraf-config"} 1
[root@k8s-master ~]#curl 10.95.156.119:8081/metrics
kube_state_metrics_watch_total{resource="*v1.Deployment",result="success"} 14567
kube_state_metrics_watch_total{resource="*v1.Endpoints",result="success"} 14539
kube_state_metrics_list_total{resource="*v1.VolumeAttachment",result="error"} 1
kube_state_metrics_list_total{resource="*v1.VolumeAttachment",result="success"} 2(2)抓紧KSM指标
这里指标的抓取,我们也可以使用两种方式,一种是categraf的input-Prometheus 的插件来采集抓取,还有一种是通过Prometheus-agent的endpoint的服务发现采集抓取指标。
两者的区别就是如果你的kubernetets集群如果物理机关机重启后,pod的IP地址就会飘走,变,如果你使用categraf的方式的话那么每次你都要去检查你的pod状态,查看url的地址。而如果你使用的Prometheus-agent的方式他就不会出现这种问题,因为你的endpoint的端口一直都是8081 8080,不会发生变化,所以不会飘走。但是Prometheus-agent的方式比较重消资源,categraf比较轻一点,但是在后续的版本里面,categraf也会增加服务发现功能,那个时候直接使用categraf即可,这次我两种都给大家配置一遍。
①Prometheus-agent抓取
只需要在我们之前采集的Prometheus-agent的configmap里面增加一行scrape规则即可,如果不知道Prometheus-agent方式怎么部署的,也可以查看我上一篇博客,里面详细讲解了,这里添加两个job name即可
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-agent-conf
labels:
name: prometheus-agent-conf
namespace: flashcat
data:
prometheus.yml: |-
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'kube-state-metrics'
kubernetes_sd_configs:
- role: endpoints
scheme: http
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-state-metrics;http-metrics
- job_name: 'kube-state-metrics-self'
kubernetes_sd_configs:
- role: endpoints
scheme: http
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-state-metrics;telemetry
remote_write:
- url: 'http://192.168.120.17:17000/prometheus/v1/write'
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: categraf
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/metrics
- nodes/stats
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
- networking.k8s.io
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics", "/metrics/cadvisor"]
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: categraf
namespace: flashcat
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: categraf
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: categraf
subjects:
- kind: ServiceAccount
name: categraf
namespace: flashcat
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-agent
namespace: flashcat
labels:
app: prometheus-agent
spec:
replicas: 1
selector:
matchLabels:
app: prometheus-agent
template:
metadata:
labels:
app: prometheus-agent
spec:
serviceAccountName: categraf
containers:
- name: prometheus
image: prom/prometheus
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--web.enable-lifecycle"
- "--enable-feature=agent"
ports:
- containerPort: 9090
resources:
requests:
cpu: 500m
memory: 500M
limits:
cpu: 1
memory: 1Gi
volumeMounts:
- name: prometheus-config-volume
mountPath: /etc/prometheus/
- name: prometheus-storage-volume
mountPath: /prometheus/
volumes:
- name: prometheus-config-volume
configMap:
defaultMode: 420
name: prometheus-agent-conf
- name: prometheus-storage-volume
emptyDir: {}
②categraf抓取
categraf抓取也很简单,因为ksm不需要认证权限,我们直接在categraf-input-Prometheus的配置文件里面添加一个instances是ksm的
---
kind: ConfigMap
metadata:
name: categraf-config
apiVersion: v1
data:
config.toml: |
[global]
hostname = "$HOSTNAME"
interval = 15
providers = ["local"]
[writer_opt]
batch = 2000
chan_size = 10000
[[writers]]
url = "http://192.168.120.17:17000/prometheus/v1/write"
timeout = 5000
dial_timeout = 2500
max_idle_conns_per_host = 100
---
kind: ConfigMap
metadata:
name: categraf-input-prometheus
apiVersion: v1
data:
prometheus.toml: |
[[instances]]
urls = ["http://127.0.0.1:10249/metrics"]
labels = { job="kube-proxy" }
[[instances]]
urls = ["https://127.0.0.1:10250/metrics"]
bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"
use_tls = true
insecure_skip_verify = true
labels = { job="kubelet" }
[[instances]]
urls = ["https://127.0.0.1:10250/metrics/cadvisor"]
bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"
use_tls = true
insecure_skip_verify = true
labels = { job="cadvisor" }
[[instances]] ##这里开始添加
urls = ["http://10.95.156.119:8080/metrics"]
use_tls = true
insecure_skip_verify = true
labels = { job="kube-state-metrics" }
[[instances]]
urls = ["http://10.95.156.119:8081/metrics"]
use_tls = true
insecure_skip_verify = true
labels = { job="kube-state-metrics-self" }
然后重启apply生成配置文件,重启categra的daemonset就可以了。
(3)监控大盘
夜莺提供的监控大盘json文件:categraf/inputs/kube_state_metrics at main · GitHub
里面的dashboard.json

(4)分片逻辑
KSM 要从 Kubernetes 中读取所有对象的信息,量是很大的,稍微大点的集群,调用 8080 端口拉取的数据会特别大,可能需要拉取十几秒甚至几十秒。最近发现 KSM 支持了分片逻辑,上面的例子我们使用单副本的 Deployment 来做,分片的话使用 Daemonset,每个 Node 上都跑一个 KSM,这个 KSM 只同步与自身节点相关的数据,KSM 的官方 README 里说的很清楚了,Daemonset 样例如下,不做过多介绍了:
apiVersion: apps/v1
kind: DaemonSet
spec:
template:
spec:
containers:
- image: registry.k8s.io/kube-state-metrics/kube-state-metrics:IMAGE_TAG
name: kube-state-metrics
args:
- --resource=pods
- --node=$(NODE_NAME)
env:
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeNameKSM 自身运行是否健康,也需要有告警规则来检测,官方也提供了相关的alerting rule:
groups:
- name: kube-state-metrics
rules:
- alert: KubeStateMetricsListErrors
annotations:
description: kube-state-metrics is experiencing errors at an elevated rate in list operations. This is likely causing it to not be able to expose metrics about Kubernetes objects correctly or at all.
summary: kube-state-metrics is experiencing errors in list operations.
expr: |
(sum(rate(kube_state_metrics_list_total{job="kube-state-metrics",result="error"}[5m]))
/
sum(rate(kube_state_metrics_list_total{job="kube-state-metrics"}[5m])))
> 0.01
for: 15m
labels:
severity: critical
- alert: KubeStateMetricsWatchErrors
annotations:
description: kube-state-metrics is experiencing errors at an elevated rate in watch operations. This is likely causing it to not be able to expose metrics about Kubernetes objects correctly or at all.
summary: kube-state-metrics is experiencing errors in watch operations.
expr: |
(sum(rate(kube_state_metrics_watch_total{job="kube-state-metrics",result="error"}[5m]))
/
sum(rate(kube_state_metrics_watch_total{job="kube-state-metrics"}[5m])))
> 0.01
for: 15m
labels:
severity: critical
- alert: KubeStateMetricsShardingMismatch
annotations:
description: kube-state-metrics pods are running with different --total-shards configuration, some Kubernetes objects may be exposed multiple times or not exposed at all.
summary: kube-state-metrics sharding is misconfigured.
expr: |
stdvar (kube_state_metrics_total_shards{job="kube-state-metrics"}) != 0
for: 15m
labels:
severity: critical
- alert: KubeStateMetricsShardsMissing
annotations:
description: kube-state-metrics shards are missing, some Kubernetes objects are not being exposed.
summary: kube-state-metrics shards are missing.
expr: |
2^max(kube_state_metrics_total_shards{job="kube-state-metrics"}) - 1
-
sum( 2 ^ max by (shard_ordinal) (kube_state_metrics_shard_ordinal{job="kube-state-metrics"}) )
!= 0
for: 15m
labels:
severity: critical
KSM 提供了两种方式来过滤要 watch 的对象类型,一个是白名单的方式指定具体要 watch 哪类对象,通过命令行启动参数中的 --resources=daemonsets,deployments 表示只 watch daemonsets 和 deployments,虽然已经限制了对象资源类型,如果采集的某些指标仍然不想要,可以采用黑名单的方式对指标做过滤:--metric-denylist=kube_deployment_spec_.* 这个过滤规则支持正则写法,多个正则之间可以使用逗号分隔。文章来源:https://www.toymoban.com/news/detail-491379.html
(四)最后的最后
相信如果你把我这两篇关于夜莺监控k8s组件的文章读完,一定可以更好的了解夜莺的监控功能,因为这都是我这一周来慢慢排错,慢慢排坑做的经历,属实创造不易!创造不易!点点赞收藏一下下就行,有问题评论区留言,看见都会解答! 文章来源地址https://www.toymoban.com/news/detail-491379.html
到了这里,关于夜莺(Flashcat)V6监控(五):夜莺监控k8s组件(下)---使用kube-state-metrics监控K8s对象的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!