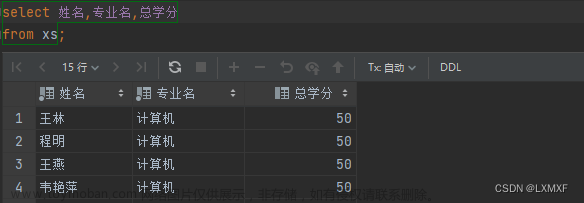
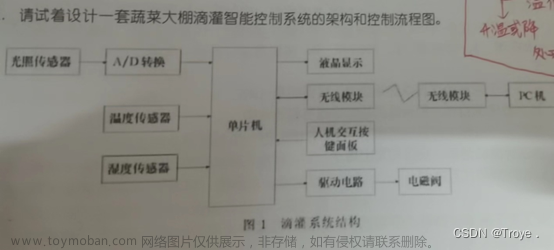
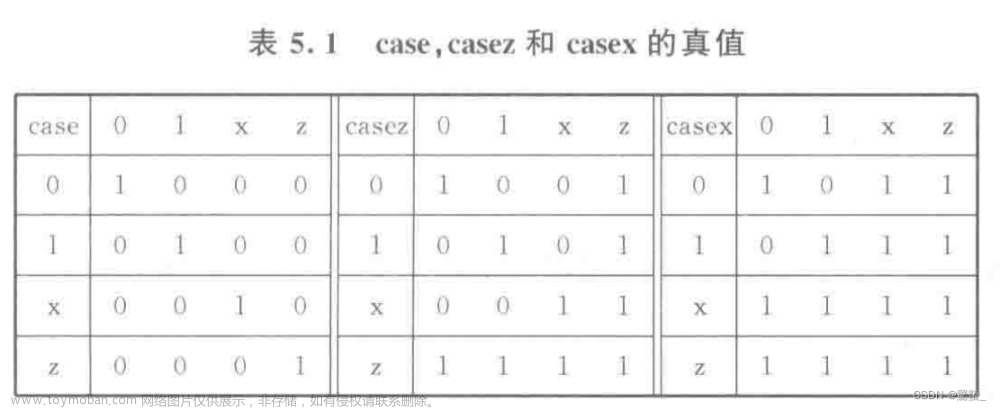
目录
1、解释估计量和估计值。
2、简述评价估计量好坏的标准。
3、怎样理解置信区间?
4、解释 95%的置信区间。
5、的含义是什么?
6、解释独立样本和匹配样本的含义。
7、在对两个总体均值之差的小样本估计中,对两个总体和样本都有哪些假定?
8、简述样本量与置信水平、总体方差、估计误差的关系。文章来源:https://www.toymoban.com/news/detail-491492.html
1、解释估计量和估计值。
在参数估计中,用来 估计总体参数 的统计量称为 估计量 ,用符号 表示。样本均值、样本比例、样本方差等都可以是一个估计量。根据一个具体的样本计算出来的估计量的数值称为 估计值 。
2、简述评价估计量好坏的标准。
评价估计量好坏的标准主要有以下三个:( 1 ) 无偏性无偏性是指估计量抽样分布的 数学期望等于被估计的总体参数 。设总体参数为 θ,所选择的估计量为 ,如果 E( )=θ,则称 为 θ 的无偏估计量。(2) 有效性一个无偏的估计量并不意味着它就非常接近被估计的参数,它还必须与总体参数的离散程度比较小。有效性是指对同一总体参数的两个无偏估计量, 有更小标准差的估计量更有效 。(3) 一致性一致性是指随着样本量的增大, 点估计量的值越来越接近被估总体的参数 。换言之,一个大样本给出的估计量要比一个小样本给出的估计量更接近总体的参数。
3、怎样理解置信区间?
在区间估计中,由 样本统计量 所构造的 总体参数的估计区间 称为 置信区间 ,其中区间的最小值称为置信下限,最大值称为置信上限。由于统计学家在 某种程度上确信这个区间会包含真正的总体参数 ,所以给它取名为置信区间。原因是, 如果抽取了许多不同的样本,比如说抽取 100 个样本,根据每个样本构造一个置信区间,这样,由 100 个样本构造的总体参数的 100 个置信区间中,有 95%的区间包含总体参数的真值,有 5%没包含。 对置信区间的理解,有以下几点需要注意:( 1 )如果用某种方法构造的所有区间中有 95% 的区间包含总体参数的真值, 5% 的区间不包含总体参数的真值,那么,用该方法构造的区间称为置信水平为 95% 的置信区间。同样,其他置信水平的区间也可以用类似的方式进行表述。(2)总体参数的真值是固定的、未知的,而用样本构造的区间则是不固定的。若抽取不同的样本,那么可以得到不同的区间,从这个意义上说,置信区间是一个随机区间,它会因样本的不同而不同,而且不是所有的区间都包含总体参数的真值。一个置信区间就像是为捕获未知参数而撒出去的网,不是所有撒网的地点都能捕获到参数。(3)在实际问题中,进行估计时往往只抽取一个样本,此时所构造的是与该样本相联系的一定置信水平(比如 95% )下的置信区间。由于用该样本所构造的区间是一个特定的区间,而不再是随机区间,所以无法知道这个样本所产生的区间是否包含总体参数的真值。我们只能希望这个区间是大量包含总体参数真值的区间中的一个,但它也可能是少数几个不包含参数真值的区间中的一个。置信区间是一个随机区间,1-α 的置信区间意味着,随着样本观察值的不同置信区间也不同,但 100 次运用这个区间,约有 100(1-α)个区间能包含参数,也就是说,大约有 100α 个区间不能包含参数。
4、解释 95%的置信区间。
95% 的置信区间的含义为抽取 100 个样本,根据每一个样本构造一个置信区间,这样, 由100 个样本构造的总体参数的 100 个置信区间中,95%的区间包含了总体参数的真值,而 5%则没有包含。
5、的含义是什么?
z α/2 是 标准正态分布 侧面积为 α/2 时的 z 值 是 估计总体均值时的估计误差 。
6、解释独立样本和匹配样本的含义。
如果两个样本是从两个总体中独立抽取的,即一个样本中的元素与另一个样本中的元素相互独立,则称为 独立样本 。匹配样本 是指一个样本中的数据与另一个样本中的数据相对应。
7、在对两个总体均值之差的小样本估计中,对两个总体和样本都有哪些假定?
在对两个总体均值之差的小样本估计中,对两个总体和样本需要作出以下假定: 文章来源地址https://www.toymoban.com/news/detail-491492.html
( 1 )两个总体都服从 正态分布 。(2)两个随机样本 独立地分别抽自两个总体 。
8、简述样本量与置信水平、总体方差、估计误差的关系。
( 1 )样本量与 置信水平 成 正比 ,在其他条件不变的情况下,置信水平越大,所需的样本量也就越大。(2)样本量与 总体方差 成 正比 ,总体的差异越大,所要求的样本量也越大。(3)样本量与 估计误差的平方 成 反比 ,即可以接受的估计误差的平方越大,所需的样本量就越小。
到了这里,关于《统计学》——思考题第七章参数估计(贾俊平)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!