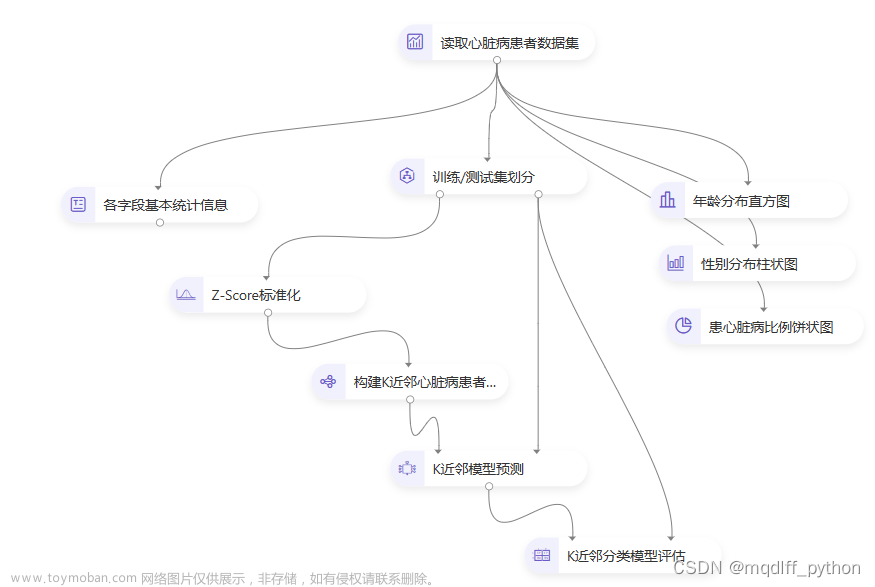
简介
背景
心脏病由心脏结构受损或功能异常引起包括先天性心脏病和后天性心脏病,不同类型的心脏病表现不同,轻重不一。
本报告是基于R语言对心脏研究的机器学习/数据科学调查分析。更具体地说,我们的目标是在心脏研究的数据集上建立一些预测模型,建立探索性和建模方法,并对其进行预测。这是心脏发生病变的疾病总称
因此通过实验总结为本次报告将有利于医疗工作者利用计算机科学进行相应的预测以及及时应对潜在的突发情况,一方面有利于减少医生的工作强调,为医生诊断工作进行辅助,另一方面更有利于患者的生命安全,以防止误诊的发生。
相关的文献回顾
阅读关于FHS的资料:心脏研究是对社区自由生活的人群中心血管疾病病因的长期前瞻性研究。心脏研究是流行病学的一个里程碑式的研究,因为它是第一个关于心血管疾病的前瞻性研究,并确定了风险因素的概念。
病因:心脏病往往受多种因素共同作用引起,包括先天因素和后天因素。先天因素包括家族遗传或自身先天缺陷、基因突变等;后天因素包括高血压、高血脂、糖尿病、慢性阻塞性肺气肿(COPD)、年龄增大、吸烟、不良生活习惯、感染史等。
预防:先天性心脏病的预防孕妇在怀孕期避免接触有毒物质、放射线,可以减少先天性心脏病的发生率;对于遗传导致的先天性心脏病,只能通过产前检查来预测。后天性获得性心脏病的预防可以通过改善日常生活方式(戒烟限酒、避免熬夜、劳累、调整情绪)预防心脏病的发生;如果患者存在慢性病,如糖尿病、高血压、高血脂,应通过药物、改善饮食和适当运动来控制这些慢性病对血管和心脏的损伤。
数据简介
Heart数据集,Age: 年龄,Sex: 性别,取值 1代表男性,0 代表女性,Pain: 胸痛的类型,取值 1、2、3、4代表 4 种不同类型,Bpress: 入院时的静息血压(单位:毫米汞柱),Chol: 血清胆固醇(单位:毫克/分升),Bsugar: 空腹血糖是否大于 120 毫克/分升,1代表是,0代表否,Ekg: 静息心电图结果,取值 0、1、2 代表 了种不同结果,Thalach: 达到的最大心率,Exang: 是否有运动性心绞痛,1代表是,0代表否,Oldpeak: 运动引起的 S工 段压低,Slope: 锻炼高峰期ST 段的斜率,取值.1 代表上斜,2 代表平坦,3 代表下斜,Ca: 荧光染色的大血管数目,取值为 0、1、2、3,Thal: 取值 3 代表正常,取值 6代表固定缺陷,取值 7代表可逆缺陷,Target1: 因变量,直径减少 50% 以上的大血管数目,取值为 0、1、2、3、4 ,Target2: 因变量,取值 1表示 target 大于0,取值0表示 target 等于0
数据
数据理解
通过对数据的可视化让我们初步了解数据情况
hist(train$age,xlab = "年龄",ylab = "人数",col = "yellow",main = '心脏病患者年龄分布',border = "blue",xlim = c(0,100))
通过上述心脏病患者的年龄分布让我们知道了主要集中在中老年人群。
hist(train$pain,xlab = "胸痛的类型",ylab = "人数",col = "yellow",main = '心脏病患者胸痛程度',border = "blue",xlim = c(0,5))
通过上述的心脏病患者胸痛程度表可以得知,往往心脏病发病的同时会伴随强烈的疼痛。
barplot(train$sex,main="男女患病对比",ylim = c(0,1),col = "blue")
通过分析上述男女患病面积对比图,可以轻松得知男性的患病率远远的大于女性,这可能是因为男性的日常不好的生活习惯和较重的生活压力所导致。
hist(train$bpress,xlab = "毫米汞柱",ylab = "人数",col = "yellow",main = '心脏病患者入院时的静息血压',border = "blue",xlim = c(80,180))
静息心率指在清醒、不活动的安静状态下,每分钟心跳的次数。
静息血压就是在此状态下的测量血压,大多数的心脏病患者都是集中在中高压这个范围,所以心脏病和高血压往往有着密不可分的关系。
hist(train$chol,xlab = "毫克/分升",ylab = "人数",col = "yellow",main = '心脏病患者入院时的血清胆固醇含量',border = "blue",xlim = c(0,500))
由此可见大多数心脏病患者刚入院时候的血清胆固醇含量很高,由此可见因身体发胖体重超标,出现血脂增高,而血脂增高是导致动脉硬化和心脑血管疾病的元凶。
barplot(train$bsugar,main="空腹血糖是否大于 120 毫克/分升对比",ylim = c(0,1),col = "blue")
通过上图的空腹血糖是否大于 120 毫克/分升对比分析得出,空腹血糖高的人数相对较少也就是说,心脏病的成因与胰岛素分泌所导致的血糖含量并无至关重要的关系。
hist(train$ekg,ylab = "人数",col = "yellow",main = '心脏病患者静息心电图结果',border = "blue",xlim = c(-1,3))
通过分析心脏病患者静息心电图结果分析来看,心脏病患者的静息心电图结果以0号和2号结果为主,1号结果几乎没有,所以由此可以推断,假如心电图结果为0号或者2号结果,那大概率上是属于心脏病患者。
hist(train$thalach,xlab = "年龄",ylab = "人数",col = "yellow",main = '心脏病患者达到的最大心率',border = "blue",xlim = c(0,250))
通过分析心脏病患者到达的最大心率进行分析,由此可见心脏病回应影响正常人的心率,而且会激增心率,这是很危险的事情,反之倘若有一个人的心率严重超过平均水平,我们由此可以推断其患有心脏病。
barplot(train$exang,main="是否有运动性心绞痛对比",ylim = c(0,1),col = "blue")
通过分析上图的是否有运动性心绞痛的对比图,让我们可以得出,是与否(0/1)的面积基本上属于对半分配,所以不好说此类因素是否影响和决定了心脏病的产生与发作。
hist(train$oldpeak,ylab = "人数",col = "yellow",main = '运动引起的S工段压低',border = "blue",xlim = c(-2,8))
ST段压低”最常见的原因是冠心病,即供应心脏血液的冠状动脉出现不同程度的堵塞,临床可表现为心绞痛,疼痛多于劳累后发生,为位于心前区的闷痛,持续几分钟至十几分钟,休息后可缓解。因此,首先要知晓“ST段压低”是哪种原因引起的,结合具体情况分析判断。先分析有无冠心病的危险因素,包括老年、吸烟、高血压、高血脂、糖尿病以及直系亲属有无冠心病史,然后在劳累(跑步、上楼、骑车等)或激动后有无上述的心绞痛症状。如果存在多个危险因素或有心绞痛症状,应该到医院进一步检查。明确有冠心病的患者,日常生活中除了坚持服药,控制冠心病危险因素也是十分重要的,包括戒烟,控制血压、血糖,低脂饮食。可以参加适量的运动,但以不引起胸闷、胸痛为限。如果不存在危险因素,也没有典型的心绞痛症状,那么“ST段压低”并不代表就是冠心病,不需要特别的治疗。当然培养良好的饮食和生活习惯还是必要的。
hist(train$slope,xlab = "取值1 代表上斜,2 代表平坦,3 代表下斜",ylab = "人数",col = "yellow",main = '锻炼高峰期ST段的斜率',border = "blue",xlim = c(1,3))
心电学指标:①ST段下移最大值;②ST段偏移的方式(下斜型、上斜型、水平型);③ST段抬高最大值;④出现ST段改变的导联数;⑤ST段改变回复至运动前水平的时间;⑥ST/HR指数;⑦运动诱发的室性心律失常;⑧ST段出现异常改变的起始时间。临床研究显示,在接近最大心率或靶心率条件下,冠心病者ECG ST段压低与心率变化通常呈线性相关,所有记录导联均应进行测算,ST/HR斜率≥2.4μV/bpm为阳性,被认为敏感性和特异性均高于单纯ST,特别是对于只能耐受低运动量水平者的冠心病诊断。不受药物、性别影响,尤其适宜于上斜型ST段下移和低水平负荷者,缺点在于计算繁琐,心肌梗死早期易致假阴性,而心肌病及主动脉瓣病变可出现假阳性。
hist(train$ca,xlab = "取值为 0、1、2、3",ylab = "人数",col = "yellow",main = '荧光染色的大血管数目',border = "blue",xlim = c(-1,4))
萤光显色的主要血管数目(0-3)彩色血管意味着医生可以看到血液通过血液运动越多越好(无凝块)由此可见患有心脏病的患者血液运动的相对较慢。
hist(train$thal,xlab = "取值 3 代表正常,取值 6代表固定缺陷,取值 7代表可逆缺陷",ylab = "人数",col = "yellow",main = '缺陷情况',border = "blue",xlim = c(2,8))
修复缺陷:曾经是缺陷,但是现在可以了,可逆缺陷:锻炼时没有适当的血液运动
数据准备
因为数据都是num类型的所以我们要把他转换成factor因子类型
train$sex<-as.factor(train$sex)
train$pain<-as.factor(train$pain)
train$bsugar<-as.factor(train$bsugar)
train$ekg<-as.factor(train$ekg)
train$target<-as.factor(train$target)
train$exang<-as.factor(train$exang)
train$slope<-as.factor(train$slope)
train$ca<-as.factor(train$ca)
train$thal<-as.factor(train$thal)
train$target2<-as.factor(train$target2)
test<- read.csv(file="E:\\R\\TEST\\heart_test.csv",header=T,fileEncoding = "utf-8")
test$sex<-as.factor(test$sex)
test$pain<-as.factor(test$pain)
test$bsugar<-as.factor(test$bsugar)
test$ekg<-as.factor(test$ekg)
test$target<-as.factor(test$target)
test$exang<-as.factor(test$exang)
test$slope<-as.factor(test$slope)
test$ca<-as.factor(test$ca)
test$thal<-as.factor(test$thal)
test$target2<-as.factor(test$target2)
由此可见我们的数据以及处理完毕了,接下来就开始数据建模
分析
建模过程(逻辑回归模型)
由于target不为二元分类所以无法使用逻辑回归,所以我们使用逻辑回归解决target2这个因变量的预测问题
首先先建模
result<-glm(target2~age+sex+pain+bsugar+ekg+exang+slope+ca+thal+oldpeak+thalach+chol+bpress,data = train,family="binomial")模型反映的结果(逻辑回归模型)
summary(result)
模型的预测(逻辑回归模型)
predResult<-round(predict(result,test,type="response"))
yuces= data.frame(test$target2,predResult)

数据分析及结果(逻辑回归模型)
由此可见预测的结果还是和真实值相比是十分准确的。
建模过程(决策树模型)
model<- rpart(target~age+sex+pain+bsugar+ekg+exang+slope+ca+thal+oldpeak+thalach+chol+bpress,train)
model<- rpart(target2~age+sex+pain+bsugar+ekg+exang+slope+ca+thal+oldpeak+thalach+chol+bpress,train)模型反映的结果(决策树模型)
summary(model)

根据交叉验证结果,找出估计误差最小时的cp值,并重新建立模型。
xerr <-model$cptable[,"xerror"]
minxerr <- which.min(xerr)选择交叉验证的估计误差最小时对应的cp
mincp <-model$cptable[minxerr, "CP"]
model.prune <- prune(model,cp=mincp)新模型
fancyRpartPlot(model.prune)

summary(model)

根据交叉验证结果,找出估计误差最小时的cp值,并重新建立模型。
xerr <-model$cptable[,"xerror"]
minxerr <- which.min(xerr)
选择交叉验证的估计误差最小时对应的cp
mincp <-model$cptable[minxerr, "CP"]
model.prune <- prune(model,cp=mincp)
新模型
fancyRpartPlot(model.prune)

模型的预测(决策树模型)
pred<-predict(model,test,type="class")
存为数据框
yucess= data.frame(test$target,pred)


数据分析及结果(决策树模型)
列出对应规则
rpart.plot(model)
asRules(model)


fancyRpartPlot(model) #更美观

model$cptable #查看交叉验证结果

plotcp(model) #查看交叉验证结果图

rpart.plot(model)
asRules(model) #列出对应规则


fancyRpartPlot(model) #更美观

model$cptable #查看交叉验证结果
plotcp(model) #查看交叉验证结果图

建模过程(随机森林模型)
pred <- data.frame() #存储预测结果
library(plyr)
library(randomForest)
m <- seq(50,1000,by = 10) #如果数据量大尽量间隔大点,间隔过小没有实际意义
for(j in m){ #j指的是随机森林的数量
progress.bar <- create_progress_bar("text") #plyr包中的create_progress_bar函数创建一个进度条,
progress.bar$init(10) #设置上面的任务数,几折就是几个任务
for (i in 1:10){
model <-randomForest(target~age+sex+pain+bsugar+ekg+exang+slope+ca+thal+oldpeak+thalach+chol+bpress,data = train,ntree = j) #建模,ntree=j 指的树数
prediction <- predict(model,subset(test,select = -target)) #预测
randomtree <- rep(j,length(prediction)) #随机森林树的数量
kcross <- rep(i,length(prediction)) #i是第几次循环交叉,共K次
temp <- data.frame(cbind(subset(test,select =target),prediction,randomtree,kcross))#真实值、预测值、随机森林树数、预测组编号捆绑在一起组成新的数据框tenp
pred <- rbind(pred,temp) #temp按行和pred合并
print(paste("进行到:",j)) #循环至树数j的随机森林模型
progress.bar$step() #输出进度条。告知完成了这个任务的百分之几
}
}
Temp
pred <- data.frame() #存储预测结果
library(plyr)
library(randomForest)
m <- seq(50,1000,by = 10) #如果数据量大尽量间隔大点,间隔过小没有实际意义
for(j in m){ #j指的是随机森林的数量
progress.bar <- create_progress_bar("text") #plyr包中的create_progress_bar函数创建一个进度条,
progress.bar$init(10) #设置上面的任务数,几折就是几个任务
for (i in 1:10){
model <-randomForest(target2~age+sex+pain+bsugar+ekg+exang+slope+ca+thal+oldpeak+thalach+chol+bpress,data = train,ntree = j) #建模,ntree=j 指的树数
prediction <- predict(model,subset(test,select = -target2)) #预测
randomtree <- rep(j,length(prediction)) #随机森林树的数量
kcross <- rep(i,length(prediction)) #i是第几次循环交叉,共K次
temp <- data.frame(cbind(subset(test,select =target2),prediction,randomtree,kcross))#真实值、预测值、随机森林树数、预测组编号捆绑在一起组成新的数据框tenp
pred <- rbind(pred,temp) #temp按行和pred合并
print(paste("进行到:",j)) #循环至树数j的随机森林模型
progress.bar$step() #输出进度条。告知完成了这个任务的百分之几
}
}
Temp
模型的预测(随机森林模型)
pred <- data.frame() #存储预测结果
temp <- data.frame(cbind(subset(test,select =target),prediction,randomtree,kcross))#真实值、预测值、随机森林树数、预测组编号捆绑在一起组成新的数据框tenp
pred <- rbind(pred,temp) #temp按行和pred合并

pred <- data.frame() #存储预测结果
temp <- data.frame(cbind(subset(test,select =target2),prediction,randomtree,kcross))#真实值、预测值、随机森林树数、预测组编号捆绑在一起组成新的数据框tenp
pred <- rbind(pred,temp) #temp按行和pred合并
 文章来源:https://www.toymoban.com/news/detail-492000.html
文章来源:https://www.toymoban.com/news/detail-492000.html
附录(核心代码)文章来源地址https://www.toymoban.com/news/detail-492000.html
train<- read.csv(file="E:\\R\\TEST\\heart_learning.csv",header=T,fileEncoding = "utf-8")
hist(train$age,xlab = "年龄",ylab = "人数",col = "yellow",main = '心脏病患者年龄分布',border = "blue",xlim = c(0,100))
Shist(train$pain,xlab = "胸痛的类型",ylab = "人数",col = "yellow",main = '心脏病患者胸痛程度',border = "blue",xlim = c(0,5))
barplot(train$sex,main="男女患病对比",ylim = c(0,1),col = "blue")
hist(train$bpress,xlab = "毫米汞柱",ylab = "人数",col = "yellow",main = '心脏病患者入院时的静息血压',border = "blue",xlim = c(80,180))
hist(train$chol,xlab = "毫克/分升",ylab = "人数",col = "yellow",main = '心脏病患者入院时的血清胆固醇含量',border = "blue",xlim = c(0,500))
barplot(train$bsugar,main="空腹血糖是否大于 120 毫克/分升对比",ylim = c(0,1),col = "blue")
hist(train$ekg,ylab = "人数",col = "yellow",main = '心脏病患者静息心电图结果',border = "blue",xlim = c(-1,3))
hist(train$thalach,xlab = "心率",ylab = "人数",col = "yellow",main = '心脏病患者达到的最大心率',border = "blue",xlim = c(0,250))
barplot(train$exang,main="是否有运动性心绞痛对比",ylim = c(0,1),col = "blue")
hist(train$oldpeak,ylab = "人数",col = "yellow",main = '运动引起的S工段压低',border = "blue",xlim = c(-2,8))
hist(train$slope,xlab = "取值1 代表上斜,2 代表平坦,3 代表下斜",ylab = "人数",col = "yellow",main = '锻炼高峰期ST段的斜率',border = "blue",xlim = c(1,3))
hist(train$ca,xlab = "取值为 0、1、2、3",ylab = "人数",col = "yellow",main = '荧光染色的大血管数目',border = "blue",xlim = c(-1,4))
hist(train$thal,xlab = "取值 3 代表正常,取值 6代表固定缺陷,取值 7代表可逆缺陷",ylab = "人数",col = "yellow",main = '缺陷情况',border = "blue",xlim = c(2,8))
train$sex<-as.factor(train$sex)
train$pain<-as.factor(train$pain)
train$bsugar<-as.factor(train$bsugar)
train$ekg<-as.factor(train$ekg)
train$target<-as.factor(train$target)
train$exang<-as.factor(train$exang)
train$slope<-as.factor(train$slope)
train$ca<-as.factor(train$ca)
train$thal<-as.factor(train$thal)
train$target2<-as.factor(train$target2)
test<- read.csv(file="E:\\R\\TEST\\heart_test.csv",header=T,fileEncoding = "utf-8")
test$sex<-as.factor(test$sex)
test$pain<-as.factor(test$pain)
test$bsugar<-as.factor(test$bsugar)
test$ekg<-as.factor(test$ekg)
test$target<-as.factor(test$target)
test$exang<-as.factor(test$exang)
test$slope<-as.factor(test$slope)
test$ca<-as.factor(test$ca)
test$thal<-as.factor(test$thal)
test$target2<-as.factor(test$target2)
str(train)
str(test)
#------------------------------------------------------------------------------------------------------------------------------
#逻辑回归
result<-glm(target2~age+sex+pain+bsugar+ekg+exang+slope+ca+thal+oldpeak+thalach+chol+bpress,data = train,family="binomial")
summary(result)
predResult<-round(predict(result,test,type="response"))
yuces= data.frame(test$target2,predResult)
#------------------------------------------------------------------------------------------------------------------------------
#决策树
model<- rpart(target~age+sex+pain+bsugar+ekg+exang+slope+ca+thal+oldpeak+thalach+chol+bpress,train)
#查看模型结果
summary(model)
rpart.plot(model)
asRules(model) #列出对应规则
fancyRpartPlot(model) #更美观
model$cptable #查看交叉验证结果
plotcp(model) #查看交叉验证结果图
#根据交叉验证结果,找出估计误差最小时的cp值,并重新建立模型。
xerr <-model$cptable[,"xerror"]
minxerr <- which.min(xerr)
#选择交叉验证的估计误差最小时对应的cp
mincp <-model$cptable[minxerr, "CP"]
model.prune <- prune(model,cp=mincp)
#新模型
fancyRpartPlot(model.prune)
#进行预测
pred<-predict(model,test,type="class")
#存为数据框
yucess= data.frame(test$target,pred)
model<- rpart(target2~age+sex+pain+bsugar+ekg+exang+slope+ca+thal+oldpeak+thalach+chol+bpress,train)
#查看模型结果
summary(model)
rpart.plot(model)
asRules(model) #列出对应规则
fancyRpartPlot(model) #更美观
model$cptable #查看交叉验证结果
plotcp(model) #查看交叉验证结果图
#根据交叉验证结果,找出估计误差最小时的cp值,并重新建立模型。
xerr <-model$cptable[,"xerror"]
minxerr <- which.min(xerr)
#选择交叉验证的估计误差最小时对应的cp
mincp <-model$cptable[minxerr, "CP"]
model.prune <- prune(model,cp=mincp)
#新模型
fancyRpartPlot(model.prune)
#进行预测
pred<-predict(model,test,type="class")
#存为数据框
yucess= data.frame(test$target2,pred)
#------------------------------------------------------------------------------------------------------------------------------
#随机森林
pred <- data.frame() #存储预测结果
library(plyr)
library(randomForest)
m <- seq(50,1000,by = 10) #如果数据量大尽量间隔大点,间隔过小没有实际意义
for(j in m){ #j指的是随机森林的数量
progress.bar <- create_progress_bar("text") #plyr包中的create_progress_bar函数创建一个进度条,
progress.bar$init(10) #设置上面的任务数,几折就是几个任务
for (i in 1:10){
model <-randomForest(target~age+sex+pain+bsugar+ekg+exang+slope+ca+thal+oldpeak+thalach+chol+bpress,data = train,ntree = j) #建模,ntree=j 指的树数
prediction <- predict(model,subset(test,select = -target)) #预测
randomtree <- rep(j,length(prediction)) #随机森林树的数量
kcross <- rep(i,length(prediction)) #i是第几次循环交叉,共K次
temp <- data.frame(cbind(subset(test,select =target),prediction,randomtree,kcross))#真实值、预测值、随机森林树数、预测组编号捆绑在一起组成新的数据框tenp
pred <- rbind(pred,temp) #temp按行和pred合并
print(paste("进行到:",j)) #循环至树数j的随机森林模型
progress.bar$step() #输出进度条。告知完成了这个任务的百分之几
}
}
temp
pred <- data.frame() #存储预测结果
library(plyr)
library(randomForest)
m <- seq(50,1000,by = 10) #如果数据量大尽量间隔大点,间隔过小没有实际意义
for(j in m){ #j指的是随机森林的数量
progress.bar <- create_progress_bar("text") #plyr包中的create_progress_bar函数创建一个进度条,
progress.bar$init(10) #设置上面的任务数,几折就是几个任务
for (i in 1:10){
model <-randomForest(target2~age+sex+pain+bsugar+ekg+exang+slope+ca+thal+oldpeak+thalach+chol+bpress,data = train,ntree = j) #建模,ntree=j 指的树数
prediction <- predict(model,subset(test,select = -target2)) #预测
randomtree <- rep(j,length(prediction)) #随机森林树的数量
kcross <- rep(i,length(prediction)) #i是第几次循环交叉,共K次
temp <- data.frame(cbind(subset(test,select =target2),prediction,randomtree,kcross))#真实值、预测值、随机森林树数、预测组编号捆绑在一起组成新的数据框tenp
pred <- rbind(pred,temp) #temp按行和pred合并
print(paste("进行到:",j)) #循环至树数j的随机森林模型
progress.bar$step() #输出进度条。告知完成了这个任务的百分之几
}
}
temp
到了这里,关于R语言关于心脏病相关问题的预测和分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!