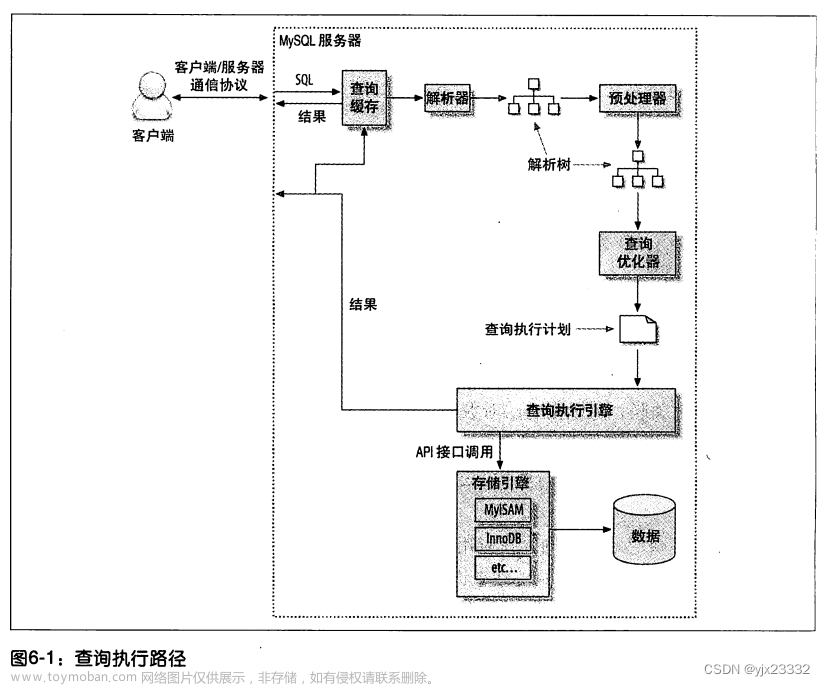
这里的深度优化是指,除了建索引、左匹配索引等等其他的优化手段。
文章涉及到操作系统连接数、IO、Mysql本身的某些参数设置,值得记录下来。
一.数据库服务器配置
- CPU:48C
- 内存:128G
- DISK:3.2TSSD
二.CPU的优化
innodb_thread_concurrency=32
表示SQL经过解析后,允许同时有32个线程去innodb引擎取数据,如果超过32个,则需要排队;
值太大会产生热点数据,global锁争用严重,影响性能
三.内存的优化
query_cache_type=0
query_cache_size=0
缓存查询,5.6默认关闭,在应用层实现,比如MC、redis
四.IO的优化
- 1.innodb_buffer_pool_size=50G
类似SGA,衡量总的IO处理能力上限,一般为物理内存的60%-70%,这里128G部署2个实例,剩下28G分配给OS和mysql连接等使用 - 2.innodb_io_capacity=20000
每秒后台进程处理IO数据的上限,一般为IO QPS总能力的75%
比如SSD是3W QPS,75%大概是2W,双实例减半,为1W,几个实例除以几 - 3.innodb_log_files_in_group=4
几个innodb redo log日志组 - 4.innodb_log_file_size=1000M
redo log日志循化写,生产必须大于1G,
如果太小,那么innodb_buffer_pool_size的数据有可能不能及时写入redo log造成halt等待;查看是否够用?如果value大于0,则提高改参数或者增加日志组
root@master 12:51: [(none)]> show global status like '%log_wait%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_log_waits | 0 |
+------------------+-------+
1 row in set (0.00 sec)
root@master 12:54: [(none)]> show global status like '%Innodb_os_log_written%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Innodb_os_log_written | 1024 |
+-----------------------+-------+
1 row in set (0.00 sec)
#此参数大小可作为设置日志文件size大小参考值
- 5.innodb_flush_method=O_DIRECT
SSD直接写硬盘,不写硬盘cache,也就是绕过fsync()刷硬盘 - 6.innodb_max_dirty_pages_pct=50
当脏块达到innodb_buffer_pool_size的50%时,触发检查点,写磁盘 - 7.innodb_file_per_table=on
一表一文件,可以避免共享表空间的IO竞争 - 8.innodb_page_size=4k
默认是16K,这里是SSD,写SSD前要擦除,擦除单位是extent,一个extent有128个page组成,16128 > 4128 ,效率会更高 - 9 innodb_flush_neighbors=0
SSD设置为0,SAS打开刷新相邻块,随机访问转换为顺序访问
五.连接的优化
- 1.back_log=300
默认是50,TCP/IP的连接数量,一个连接占用256KB内存,最大是64MB,256 * 300 =75MB内存和三次握手有关系
syn_queue取64和tcp_max_sync_backlog最大者,默认是1024,当瞬时很多连接进来这个参数会进行限制,否则太大容易消耗资源
accept queue取back_log和somaxconn最小者,用来防止丢包,当瞬时很多连接进来达到上限后,后来连接将超时触发重传机制
当有3000个连接进来,将队列accept queue占满,应用还没来得及将请求从队列中取出,剩下的2700个连接将被拒绝,每取走一个请求(一个连接,mysql一个线程一个连接),将创建一个thread线程
net.ipv4.tcp_max_sync_backlog= 8192 类似活动场所
sync接收队列的长度,默认是1024,当mysql在很短时间内得到很多的请求,需要增加,太大会消耗资源,太小的话会在show processlist出现未认证错误
net.core.somaxconn=1024 类似活动场所中的座位数
尽可能防止丢包,超过这个值会触发超时或者重传,限制在net.ipv4.ip_local_port_range这个范围之内
- 2.max_connections=3000
连接的创建和销毁都需要系统资源,比如内存、文件句柄
业务说的支持多少并发,指的是每秒请求数,也就是QPS
同一时刻并行的SQL由innodb_thread_concurrency决定,最大不能超过该值
如果一个用户的请求数据超过64MB(比如排序),就会申请临时空间,放到硬盘上
如果3000个用户同时连上mysql,最小需要内存3000256KB=750M,最大需要内存300064MB=192G,如果innodb_buffer_pool_size是80GB,可用内存不到48G,192GB>48GB,将会产生SWAP,此时将会影响性能
连接数过高,不一定带来吞吐量的提高,而且可能占用更多的系统资源
一个DB 3W QPS计算,前端有100个web服务器,每个web服务器需要300个QPS,每个QPS占用时间=网络来回时间+SQL执行时间,以20ms计算,需要6个连接数(300/1000/20ms=6)
示例1:有100台web服务器,PHP/JAVA的最大连接数可设置为:3000/100=30
示例2:有30台web服务器,要扩容到60台,web服务器连接数怎么配置?web服务器最大连接数:之前是3000/30=100,现在3000/60=50即可
- 3.max_user_connections=2980
剩余连接数用作管理 - 4.table_open_cache=1024
打开表的缓存,跟表数量没关系
1000个连接上来,都需要访问A表,那么会打开1000个表,打开1000个表是指mysql创建1000个这个表的对象,连接直接访问表对象,类似会把这张表做一个class,1000个连接都访问这个表对象,当表对象没了,重新new一个,不需要每次都打开物理表
root@master 14:44: [(none)]> show variables like '%table_open_cache';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| table_open_cache | 1024 |
+------------------+-------+
1 row in set (0.00 sec)
root@master 14:46: [(none)]> show global status like 'open%tables%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Open_tables | 19 |
| Opened_tables | 113 |
+---------------+-------+
2 rows in set (0.00 sec)
可以考虑设置为max_connections或者max_connections*查询同时用到的表个数或者
- 5.thread_cache_size=512
都是短连接进来容易产生短连接风暴
会话层:事务状态、认证会话
连接层:网络连接、包传输
一个用户 对应 一个session 对应 一个connection
connection - thread:操作系统调用
3000个用户进来使用cache的512个线程,用完就放回去,避免创建、销毁线程的开销 - 6.wait_timeout=120
指的是app应用连接mysql进行操作完毕后,空闲120秒后断开 - 7.interactive_timeout=120
指的是mysql client连接mysql进行操作完毕后,空闲120秒后断开
六.数据一致性的优化
1.innodb_flush_log_at_trx_commit=1
0,不管有没有提交,每秒钟都写到binlog日志里
1,每次提交事务,都会把log buffer的内容写到磁盘里去,对日志文件做到磁盘刷新,安全最好
2,每次提交事务,都写到操作系统缓存,由OS刷新到磁盘,性能最好
https://blog.csdn.net/zengxuewen2045/article/details/51476186
2.sync_binlog=1
0,事务提交后,mysql不做fsync之类的刷盘,由文件系统来决定什么落盘
n,多少次提交,每n次提交持久化磁盘
生产设为1
3.日志写盘过程
1)三个update会话,三个线程都会产生的操作日志
2 )commit后提交到公共的cache中,三个进程之间不能相互看到对方的操作内容
3)经过write写入到标准I/O cache中,也就是文件系统句柄,线程缓存
4)如果需要让其他线程看到文件句柄内容,就需要通过flush刷新到全局可见文件系统缓存
5)最后最重的一步是将内存数据sync落盘文章来源:https://www.toymoban.com/news/detail-492079.html
原文链接
https://www.cnblogs.com/jenvid/p/8994831.html文章来源地址https://www.toymoban.com/news/detail-492079.html
到了这里,关于MySQL性能深度优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!