在云原生计算时代,云存储使得海量数据能以低成本进行存储,但是这也给如何访问、管理和使用这些云上的数据提出了挑战。而 Iceberg 作为一种云原生的表格式,可以很好地应对这些挑战。本文将介绍火山引擎在云原生计算产品上使用 Iceberg 的实践,和大家分享高效查询、存储和治理 Iceberg 数据的方法。
Why Iceberg

Iceberg 是一种适用于 HDFS 或者对象存储的表格式,把底层的 Parquet、ORC 等数据文件组织成一张表,向上层的 Spark,Flink 计算引擎提供表层面的语义,作用类似于 Hive Meta Store,但是和 Hive Meta Store 相比:
-
Iceberg 能避免 File Listing 的开销;
-
也能够提供更丰富的语义,包括 Schema 演进、快照、行级更新、 ACID 增量读等。

Iceberg 相较于 Hive 表是基于设计的文件组织形式实现的上述优点,和 Hive Metastore 把元数据存在 MySQL 上的数据库不一样, Iceberg 是把元数据以文件的形式存在 HDFS 或对象存储上。最上层的 Catalog 也就是表的目录指向了每个表当前版本对应的 Metadata File,由于 Iceberg 使用 MVCC,所以每次对表的变更都会产生一个新版本的 Metadata File。这个 Metadata File 记录了 Schema 分区方式、快照列表等表级别的元数据,所以在这个 Metadata File 存的快照列表里面,每个快照下层对应的 Manifest List 文件中记录了这个快照的元数据信息,用于描述快照底下拥有的 Manifest File 及再下层的实际数据文件。
第一个优点是 Iceberg 适合对象存储。作为对比,我们首先看 Hive 表的文件结构。 Hive Metastore 只记录 Hive 表底下有哪些分区,但是它不记录分区底下有哪些数据文件,而需要通过文件系统的 File Listing 才能列出分区目录底下的实际的数据文件,这就导致 Hive 表在对象存储上的查询开销很大。
而 Iceberg 的文件组织形式,从 Metadata File 到 Manifest List,再到 Manifest File,最后到实际的 Data File,通过这种层级关系保存了一个从 Iceberg 表到底层所有数据文件的映射。因此只需要依靠读元数据文件就可以获取一张 Iceberg 表里面所有的数据文件而不需要做 File Listing,从而更适用于对象存储的场景。
第二个优点是文件组织形式更适合支持各种语义,例如 Schema、快照和增量读等。当需要支持 Schema 演进时,即对以前提交的数据使用旧的 Schema A,对以后的提交使用另一个 Schema B,在 Iceberg 中,每个 Manifest File 底下的 Data File 都是由唯一一次 Commit 产生的,因此在这个 Manifest File 底下的所有 Data File 的 Schema 都是相同的。所以我们只需要在 Manifest File 中记录哪些 Data File 使用了哪个 Schema 即可实现这个功能。
而对于快照功能而言,每个 Manifest List 底下的数据就对应着一个快照的数据。如果我们需要使用快照的 Time Travel 能力,可以直接读取快照对应的 Manifest List。如果需要回滚,则删除新的 Manifest List 即可。
对于增量读而言,只需要依次读取指定快照以后新产生的每个 Manifest File 即可获取新增的 Data File。
基于 Iceberg 的批流一体解决方案

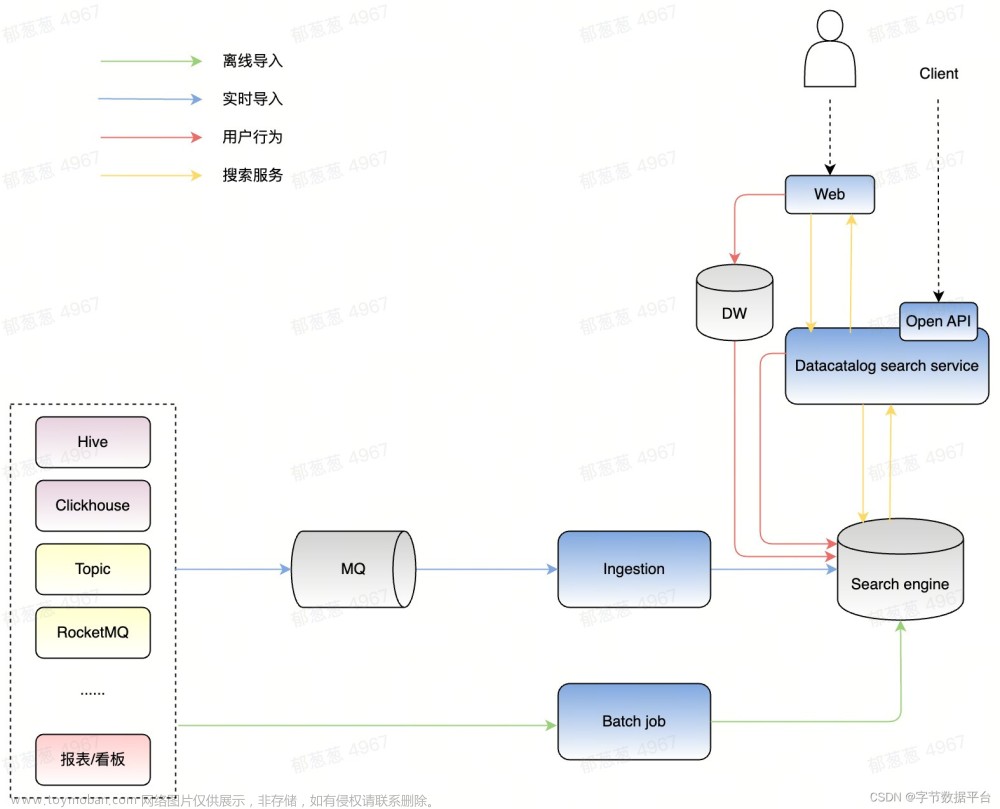
如上图 Iceberg 在火山引擎的解决方案中我们可以看到火山引擎基于 Iceberg 的批流一体的解决方案。底层存储使用的是字节跳动自研、兼容 HDFS 语义的 CloudFS,然后通过 Iceberg 提供的 Merge Read 还有 Upsert 这些语义,再结合平台的服务支持了数据在 Iceberg 上面批流一体的存储。
在数据入湖方面,我们支持从客户自建的数据库或 HDFS 中进行批式或流式导入到 Iceberg 中。在数据的计算方面,流式和批式等计算引擎可以使用 Iceberg 提供的近实时数据进行计算,并最终将计算结果展示在上层的销售大屏等应用程序上。
实践案例
流式入湖 + OLAP 场景

在流式入湖加 OLAP 的场景下,一边是 Flink 作业向 Iceberg 流式 Upsert 数据,另一边是 Flink 做批式的 OLAP 查询。这个场景的特点在于:
-
流式 Upsert 带来了分钟级的高频率 Commit;
-
OLAP 查询的并发度高、对响应时间的要求也高。
因此主要的挑战是高频率的 Commit 导致的小文件问题,以及如何保证 OLAP 查询的吞吐和响应时间。下面将详细介绍在该场景下的解决方案。
数据维护

首先我们来看数据维护的解决方案,在使用数据维护之前,出现的问题主要包括:
-
高频 Commit 导致的小文件需要合并;
-
及由于 Iceberg 的 MVCC 机制,在合并小文件后,原来的小文件仍然保留在历史快照中占用空间;
-
此外从业务角度分析,有些数据在一定时间后会失去业务上的价值,就需要将其操作清理。
为解决这些问题,平台会为每个表托管定时执行的 Spark 作业做数据维护,包括数据\元数据的小文件合并,数据过期、快照过期、孤儿文件清理等相关任务。

拥有了数据维护服务后,还有一些关键问题需要解决:
-
一个是合并小文件时,由于写入数据是按文件力度并行的,也就是一个 Subtask 写一个文件,如果生成的文件太少就会限制写入时的并行度;
-
另一个问题就是数据文件是 Parquet 格式的,那么读文件的并行度就取决于 Parquet Row Group 的大小,因为一个 Flink 的 Subtask 最少需要读一个 Row Group,当 Row Group 过大时就会限制读取的并行度。
因此针对以上问题的优化方向是根据用户对读写性能的要求,及可用的计算资源设置了一些对应的表属性,具体优化参考如下:
-
在写的并行度方面通过设置 write.target-file-size-bytes 参数调整合适的文件大小,让合并小文件的时候每个 Task Manager 都能在写文件,以此做到计算资源的充分利用。
-
在读的并行度方面通过以下两步设置保证每个 Task Manager 都能在读文件。
-
首先通过 write.parquet.row group size bytes,保证写下去的 Parquet 文件有一个合适的 Row Group 大小;
-
再设置 read.split.target size 保证后续读的时候 Flink 的每一个 Subtask 读的 Input Split 就对应一个 Row Group。
-
写入调优

接下来介绍 Flink 流式写入调优实践。在默认情况下, Flink 做流式写入时的 Task Manager 中执行的 Subtask 会分配写到多个 Iceberg 分区的数据,所以我们需要为每个 Iceberg 分区开一个对应的 Writer,然后以 Fanout 的方式同时去向多个分区写数据,而 Task Manager 同时需要写的分区数太多,进而会导致Writer 过多 Task Manager OOM 的情况。
这个问题的解决方法是在 Flink 侧按照 Iceberg 表的分区字段对数据做 Keyby 操作,然后把同一个分区的数据集中在同一个 Subtask 中写,从而把每一个 Task Manager 同时需要写的分区数控制在一个合理的范围避免 OOM 的问题。
物化视图

接下来介绍物化视图的解决方案,它解决的问题是:某些 OLAP 查询的计算量大、查询耗时长,而同一个查询的频次较高导致的大量重复、高负载计算。
针对这个问题,我们通过自研的物化视图存储 OLAP 查询的预计算结果,并通过增量计算刷新物化视图,以保证数据的新鲜度。从上图可以看出在使用物化视图之前,执行一次查询做的全量计算需要耗时 30 秒,而使用物化视图后的查询只需要 3 秒钟,并且对于重复的查询还能节省大量的计算时间及资源。

物化视图的实现过程是用户首先通过 Flink SQL 向平台发送创建物化视图的请求,平台负责创建实际的 Iceberg 物化视图,然后启动一个流式 Flink 作业刷新该物化视图,并通过托管作业保证它的持续运行。持续地从原表流读增量数据并将增量的计算结果写入物化视图的过程使用户能够直接通过物化视图获取到原本需要做全量计算才能获得的结果。目前 Iceberg 的物化视图还只是一个普通的 Iceberg 表,未来我们会在 Iceberg 层面记录更完善的元数据信息,用来支持判断数据的新鲜程度及基于已有的物化视图做自动重写、优化查询等能力。
多版本适配

在实践中我们为 Iceberg 做了 Flink 的多版本适配。背景是由于用户在查询的时候需要用到字节跳动内部 Flink 1. 11 的 OLAP 能力,但是 Flink 1. 11 最高只兼容 Iceberg 0.11,而 Iceberg 0.11 是不支持读 upsert 数据的。解决方式是通过新版的 Iceberg 1.0 兼容 Flink 1. 11,这样就实现了既支持读 Upsert 数据的能力,又能利用字节跳动内部 Flink OLAP 的能力。

在多版本适配中的具体实现目标是让 Flink 1.11 能够用 Iceberg 1.0 读 Upsert 的数据。在实践中发现 Iceberg 1.0 支持的最早 Flink 版本是 1.13,于是通过尝试把 Iceberg 1.0 的 Flink 1.13 Connector 代码迁移到 Flink 1.11 实现,在解决完一些小的兼容性问题后,我们遇到了一个大问题—— Iceberg 1.0 实现的是新版的 Flink Connector,即 Dynamic Table,而 Flink 1. 11 对 Dynamic Table 的支持不太完善,也不支持谓词下推,这就会对读性能造成很大的影响。因此我们的解决方式是通过让 Iceberg Table Source 部分使用 Iceberg 0.11 的代码实现旧版的 Flink Connector,这样我们在 Fink 1.11 里面就可以做谓词下推了,然后在这个基础上再做一些调整,保证它仍然调用底层 Iceberg 1.0 的核心逻辑支持读 Upsert 数据。
特征调研场景

特征调研场景的特点在于它的数据量,具体表现在于:
-
表很长,也就是行数多,每天要导入 TB 级的数据;
-
表很宽,也就是有很多列,大概有几千列的特征。
因此主要的挑战是数据量大使得水涨船高导致元数据的量也很大,而在读 Iceberg 表的时候,会导致 Spark Driver 解析元数据做 Planning 时解析元数据的性能成为瓶颈。下面详细介绍为了应对这个难点我们做的一些优化。
元数据瘦身

第一个优化点是元数据的瘦身。默认情况下,Manifest File 为每个 Data File 里的列数据记录统计信息,包括 Value Counts 和 Null Counts 等这些用来加速列过滤的信息。在特征调研的场景下,表内包含的几千列特征占了总文件的 70%- 80%,会导致 Planning 的耗时很长。从图中可以看出优化前 plan 4 天的数据需要耗时 50 秒。我们在实践中发现实际上不需要对特征列做过滤,可以直接把这些特征列的统计信息删除,做元数据的瘦身,从而可以看到 Planning 的耗时从 50 秒减到了 5 秒,大约可以减少消耗 90% 的时间。
Manifest 整理

第二个优化点是 Manifest 整理。主要针对的问题是特征调研场景下数据回流导致的一个日期数据多次写入产生多个对应 Manifest File ,后续数据的读取需要先读很多的 Manifest 的问题。比如图中 10 月 1 日的这个数据分区,在 10 月 1 日有大量的写入,之后在 10 月 2 日和 3 日又会有少量的数据回流到 10 月 1 日的分区中,这就导致了读 10 月 1 日的数据需要先去读三天的 Manifest。我们做的优化是利用 Iceberg 的 Rewrite Manifests 重写 Manifest,这个操作可以使同一个日期的数据集中在相同的 Manifest 里面,大幅减少了需要读的 Manifest 的量级。从图中可以看到这个优化在实践中为我们减少了大概 33% 的 Planning 时间。
File Skipping 优化

第三个优化点是 Iceberg File Skipping 机制。在特征调研场景下针对一个表最常见的查询就是针对日期过滤。比如左图中 “SELECT FROM table WHERE date < '2022-10-03'”,就是读 2022 年 10 月 3 日之前的全部数据做训练模型。问题是 Iceberg 中原来的 File Skipping 机制需要判断 Manifest 里面的每个 Data File 是否能够跳过。比如上图中的例子 Iceberg 会根据 Manifest 的日期下界小于 10 月 3 日判断出这个 Manifest 里有 Data File 需要读,接着去看 Manifest 里记录的每个 Data File 的日期下界判断这个 Data File 需不需要读。
由于在特征调研的场景下,我们每天会产生几千个 Data File,所以上述对每个 Data File 做判断带来的开销还是相对较大的,这就导致 Plan 一年的数据需要至少 50 分钟才能完成。我们的优化方式是通过增加判断来解决这个问题,以图中的情况为例,可以根据 Manifest 的日期上界小于 10 月 3 日判断出这个 Manifest 里所有的 Data File 都是需要读的,这样就不再需要对每个 Data File 做判断了。通过这个优化 Plan 一年数据的耗时从 50 分钟减少到了 5 分钟左右。
发展方向
最后介绍我们对 Iceberg 未来发展方向的规划。
-
首先在针对元数据的优化方面会做更多的 Data Skipping 优化,包括实现一级索引和二级索引等;
-
在针对数据的优化方面会支持更全面的谓词下推及更多自研的存储格式,用来提升压缩率和读写性能;
-
在自动优化方面做到自动统计用户查询,然后针对统计的结果自动优化性能和开销。比如自动创建物化视图、自动调优数据维护任务的参数\执行频率、合并文件大小等,以及实现通过利用统计结果指导数据的冷热分层等能力。
更多能力介绍与支撑产品请关注大数据文件存储 CloudFS https://www.volcengine.com/product/cfs文章来源:https://www.toymoban.com/news/detail-492610.html
火山引擎大数据文件存储是面向大数据和机器学习生态的统一存储服务。支持对接多云对象存储,并提供统一数据管理和数据缓存加速服务,具备低成本、高可靠、高可用等特性。加速大数据处理、数据湖分析、机器学习等场景下的海量数据的存储访问速度。文章来源地址https://www.toymoban.com/news/detail-492610.html
到了这里,关于火山引擎 Iceberg 数据湖的应用与实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!