进程/线程间的互斥相关背景概念
🚀 临界资源:多线程指行流共享的资源叫做临界资源。
🚀 临界区:每个线程内部访问临界资源的代码片段叫做临界区。
🚀 互斥:任何时刻,互斥保证只有一个指行流进入临界区,访问临界资源,通常是对临界区起保护作用。
🚀 原子性:不被任何调度所打断的操作,该类操作只有两态:完成,未完成。
临界资源与临界区
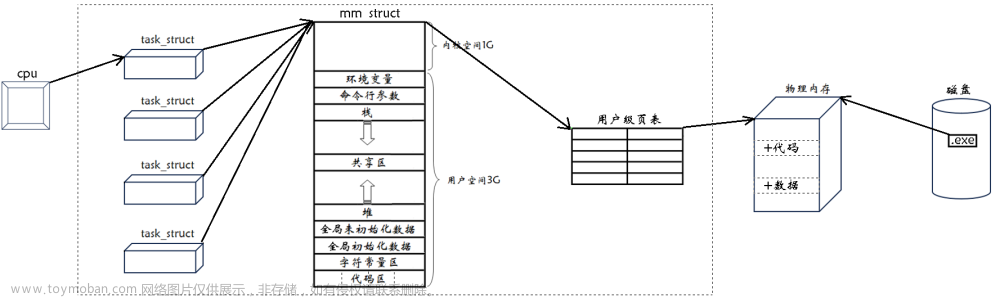
我们在实现多进程间通信的时候,首先面临的问题就是要让多个进程看到同一份资源,因为进程具有独立性,拥有自己的地址空间。所以,要让多进程实现通信,就要在内核中开辟特定的资源,使其对多个进程都是可见的,也就是说是被多个进程所共享的,通常实现进程间通信的方式:管道,消息队列,共享内存。这些被多进程所共享的资源就叫做临界资源,同时访问这些临界资源的代码片段就叫做临界区。
而对于多线程来说,其优势就是通信十分便利,因为多个执行流共享同一个地址空间,所以具有全局性质的数据都可以被多线程所访问。
#include <iostream>
#include <pthread.h>
#include <unistd.h>
int g_val = 0;
void *thread_run(void *args)
{
while (true)
{
std::cout << pthread_self() << " g_val : " << g_val++ << std::endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, thread_run, nullptr);
while (true)
{
std::cout << "main thread - g_val : " << g_val << std::endl;
sleep(1);
}
pthread_join(tid, nullptr);
return 0;
}

代码中g_val这个全局变量就是被多线程所共享的(新线程中对g_val++,对应主线程中打印出g_val的值也会发生改变),这种被多线程所共享的资源就叫做临界资源,而在主线程中打印语句,新线程中打印语句和对g_val++语句,这种访问临界资源的代码片段就叫做临界区。
互斥与原子性
当多执行流访问临界资源时,如果没有对临界资源加以保护,那么就可能出现数据不一致的情况。例如下面的多线程抢票逻辑:
int tickets = 10000;
void *thread_run(void *args)
{
while (true)
{
if (tickets > 0)
{
usleep(100); // 模拟抢票的时间
std::cout << pthread_self() << " got a ticket :" << tickets-- << std::endl;
usleep(100); // 模拟抢票后的处理动作
}
else
{
break;
}
}
}
const int NUM = 5;
int main()
{
pthread_t tids[NUM];
for (int i = 0; i < NUM; i++)
{
pthread_create(tids + i, nullptr, thread_run, nullptr);
}
for (int i = 0; i < NUM; i++)
{
pthread_join(tids[i], nullptr);
}
return 0;
}

可以发现票居然被抢到了负数,相当于多出了几张票,这与理论上票的数量是不一致的,那么造成这种情况的原因是什么呢?原因:
1,if (tickets > 0) 语句处发生问题:假设当票数只剩一张的时候,某个进程通过了if条件判断,但是在它抢到票之前因为时间片到了被挂起了,所以此时就会有别的线程也会通过了if条件判断,这时就会出现只剩最后一张票了,但是有多个线程通过了if判断,当它们在抢取票的时候,就会出现票数成负的情况。
2,由于tickets–,这条语句不是原子性的,因为一条–语句会被汇编成多条指令,那么就表示它可能被调度所打断,图示:


对一个数据–操作,主要由三步组成:
(1)先将数据从内存加载到某个寄存器中
(2)对寄存器的数据-1
(3)将寄存器的数据写回内存。
此条语句不是原子的,可能被调度所打断,可能会出现某个线程运行到了第2步的时候,还没来得及将寄存器中的值写回内存中,就被切换了,此时第二个线程从内存中读取到的tickets的数据就是错误的。
举一种极端情况,假设票总数为100,第一个线程将票数减到了99的时候,还没来得及将寄存器的值写回内存,就被切换了,此时第二个线程被调度,它一下子抢到了90张票,将tickets减到了10。当第一个线程被再次切换回来的时候,会从它保存的上下文继续运行,那么就将99写回内存,这就会造成数据的不一致。
所以,为了防止以上出现,就要保证执行临界区的代码得是互斥的,也就是任何止时刻只有一个线程能够访问临界区,对临界资源修改。
互斥量
🚀要解决上述的问题,需要做到三点:
1,代码必须要有互斥行为:当代码进入临界区执行时,不允许其他线程进入该临界区。
2,如果多个线程同时要执行临界区的代码,并且临界区内没有线程在执行,那么只能允许一个线程进入临界区。
3,如果线程不在临界区中执行,那么该线程不能阻止其他线程进入临界区。
🚀做到以上三点,那么就需要使用互斥量,本质就是一把锁。在访问临界区之前要先加锁,访问完临界区后要解锁,从而保证多线程访问临界区的代码时是互斥的。
🚀也就是说对于非临界区的代码允许多线程并发运行,但是临界区的代码是串行执行的。
互斥量接口
互斥量的初始化
🚀1,静态分配
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER
🚀2,动态分配
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrictattr);
//参数1:锁的地址
//参数2:锁的属性:通常置为nullptr即可。
互斥量的销毁
int pthread_mutex_destroy(pthread_mutex_t *mutex);
注意:
1,静态分配的互斥量是不需要被销毁的。
2,不要销毁一个正在加锁的互斥量。
3,已经销毁的互斥量,确保后面不会有线程再尝试加锁。
加锁和解锁
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
🚀在调用pthread_mutex_lock的时候有以下情况:
1,互斥量没有被其他线程占用,那么该函数就会锁定互斥量,返回成功。
2,互斥量已经被其他线程占用,或者同时多个线程竞争这个互斥量,但是没有竞争到互斥量,那么执行此函数的线程就会陷入阻塞状态,当互斥量被解锁时就会被唤醒。
改善抢票系统
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void *thread_run(void *args)
{
while (true)
{
// 进入临界区前要先加锁
pthread_mutex_lock(&mutex);
if (tickets > 0)
{
usleep(100); // 模拟抢票的时间
std::cout << pthread_self() << " got a ticket :" << tickets-- << std::endl;
pthread_mutex_unlock(&mutex);
usleep(100); // 模拟抢票后的处理动作
}
else // 出临界区时要解锁
{
pthread_mutex_unlock(&mutex);
break;
}
}
}

互斥量原理
🚀为了实现互斥操作,大多数的体系结构提供了swap或exchange指令,该指令的作用是把寄存器和内存单元的数据做交换,由于只有一条指令,所以保证了原子性,即使是多处理器平台,访问内存的总线周期一定有先后,一个处理器上的交换指令在执行时另一个处理器的交换指令只能等待总线周期。
🚀lock与unlock的伪代码:
//mutex的起始值为1
lock:
mov $0 , %al
xchgb %al , mutex
if(al寄存器的内容 > 0){
return 0;//表示加锁成功
} else {
挂起等待;
}
goto lock; //再次被唤醒的时候再去竞争锁
unlock:
mov $1 , mutex
唤醒等待mutex的线程
return 0;
🚀线程各自拥有一组寄存器,来保存自己的上下文,也就是说寄存器中的内容是属于线程的,当线程被切换出去的时候,寄存器中的内容会保存到该线程的上下文中。只要当某个线程运行时al寄存器中的值和mutex交换后为1,那么证明此线程抢到了锁,即使此线程此刻就被切换出去,其他线程也是抢不到锁的(此时mutex的值就为0),因为当此线程切换出去的时候al寄存器的内容被保存到线程的上下文中,当线程再次被调度的时候,它会恢复其上下文,此时al寄存器的值就会被重新置1,在向下执行if判断的时候,表示加锁成功。
🚀解锁的操作就是给mutex置为1,一条mov指令本身就是原子的。解锁只是给mutex置为1,那么意味着不仅可以加锁的线程给自己解锁,还可以其他线程对其解锁。
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void *thread_run(void *args)
{
pthread_mutex_lock(&mutex);
std::cout << "i got a mutex" << std::endl;
pthread_mutex_lock(&mutex);//由于自己第一次申请的锁没有释放,当第二次申请锁的时候就会被阻塞
std::cout << "i got a mutex again" << std::endl;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, thread_run, nullptr);
sleep(3);
pthread_mutex_unlock(&mutex);//主线程进行解锁,那么新线程再次申请锁的时候就能成功了。
std::cout << "main thread unlock the mutex" << std::endl;
pthread_join(tid, nullptr);
return 0;
}

可重入与线程安全
重入和线程安全的概念
🚀线程安全:多个线程并发访问同一段代码的时候,不会出现不同的结果。常见对全局变量,静态变量进行操作,在不加锁保护的情况下,会出现该问题。
🚀 重入:同一个函数被不同的执行流调用,当前一个执行流没有执行完,就会有其他的执行流再次进入,我们称之为重入。一个函数在重入的情况下,运行的结果不会出现任何问题,则该函数被称为可重入函数,否则,就是不可重入函数。
常见线程不安全情况
🚀不保护共享变量的函数
🚀 函数状态随着被调用而发生变化(例如,某个函数内部存在一个静态变量做计数器,每次调用就把计数器+1)
🚀 返回指向静态变量指针的函数
🚀 调用线程不安全函数的函数
常见线程安全的情况
🚀 每个线程对全局变量或静态变量只有读权限,而没有写入权限,一般来说这些线程时安全的。
🚀 类或者接口对线程来说都是原子操作(例如:加锁,解锁的接口)
🚀 多个线程之间的切换不会造成接口的执行结果有二义性。
常见不可重入情况
🚀 调用了malloc/free函数,因为malloc函数是用全局链表来管理堆的。
🚀 调用了标准I/O库函数,标准I/O库的很多实现都以不可重入的方式使用全局数据结构
🚀可重入函数体内使用了静态的数据结构
常见可重入情况
🚀不适用全局变量或者静态变量
🚀 不适用malloc/new开辟出的空间
🚀 不调用不可重入函数
🚀 不反回静态或者全局数据,所有数据都由函数调用者来提供
🚀 使用本地数据,或者通过制作全局数据的本地拷贝来保护全局数据
可重入与线程安全的关系
🚀函数是可重入的那么线程在调用此函数期间是线程安全的
🚀 函数是不可重入的,那么就不能被多个线程调用,有可能引发线程安全问题
🚀 如果一个函数中有全局变量,那么这个函数既不是线程安全也不是可重入的
可重入与线程安全的区别
🚀 可重入函数是线程安全函数的一种
🚀 可重入和不可重入是函数的一种属性没有好坏之分,而线程安全与线程不安全是由好坏之分的。
🚀 线程安全不一定是调用了可重入函数(例如多个线程分别执行不同的函数),而调用可重入函数的线程,在调用可重入函数的期间一定是线程安全的
🚀如果对临界资源加锁保护,那么这个函数是线程安全的函数,也是可重入的,但是如果这个重入函数没有对锁进行释放,那么就会产生死锁,就是不可重入的。
死锁
死锁概念
🚀死锁是指一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所占用的不会释放的资源而处于一种永久的等待状态。
死锁的四个必要条件
1,互斥:一个资源每次只能被一个指行流使用
2,请求与保持:一个执行流因请求资源而阻塞时,对已经获得的资源保持不妨
3,不剥夺:一个执行流已获得的资源,在未使用之前,不能强行剥夺
4,循环等待:若干执行流之间形成一种头尾相接的循环等待资源的关系
如何避免死锁
🚀破坏形成死锁四个必要条件之一即可。
1,不加锁
2,主动释放锁(申请锁时采用try lock,当多次不成功时,先不再申请并且将自己占有的资源释放)
3,按顺序加锁
4,控制线程统一释放锁
线程的同步
条件变量
🚀当一个线程互斥的访问一个临界资源时,他可能发现在其他线程改变状态之前,它什么也做不了。
🚀例如,将之前抢票的逻辑改一下,当线程发现tickets <= 0的时候,不break而是选择继续抢票,因为存在某个线程退票的情况,但是在没有其他线程退票之前,这个线程就会反复的申请锁-释放锁但申请锁之后什么都做不了,这就会导致其他线程的饥饿状态,并且反复的申请锁释放锁抢到锁后什么都不做是一种资源的浪费,这种情况就需要用到条件变量-当if判断tickets <= 0的时候,不选择继续去抢票而是进入到条件变量中等待,当临界资源满足条件时再通知其继续做相应得抢票操作。
void *thread_run(void *args)
{
while (true)
{
// 进入临界区前要先加锁
pthread_mutex_lock(&mutex);
std::cout << pthread_self() << " got the mutex" << std::endl;
if (tickets > 0)
{
usleep(100); // 模拟抢票的时间
std::cout << pthread_self() << " got a ticket :" << tickets-- << std::endl;
pthread_mutex_unlock(&mutex);
usleep(100); // 模拟抢票后的处理动作
}
else
{
pthread_mutex_unlock(&mutex);
}
}
}

可以看到,当票被抢光后由于没有其他线程退票,导致线程id后四位为1920的线程频繁申请和释放锁,但是它在申请到锁后并没有做任何事情。
线程同步
🚀在保证数据安全的情况下,让线程按照某种特定的顺序访问临界资源,从而避免饥饿问题,叫做同步。
条件变量操作
- 初始化
//动态分配
int pthread_cond_init(pthread_cond_t *restrict cond,const pthread_condattr_t *restrictattr);
//第一个参数为条件变量的地址
//第二个参数为条件变量的属性,通常置为nulltr
//静态分配
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
- 销毁
//如果动态分配就需要调用destroy销毁
int pthread_cond_destroy(pthread_cond_t *cond)
- 使线程在条件变量中等待条件满足
int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex);
//第一个参数表示在哪个条件变量中等待
//第二个参数为互斥锁
- 唤醒等待
int pthread_cond_broadcast(pthread_cond_t *cond);
//唤醒一个
int pthread_cond_signal(pthread_cond_t *cond);
//全部唤醒
🚀简单案例,让线程按一定顺序运行
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
void *thread_run(void *args)
{
while (true)
{
pthread_mutex_lock(&mutex);
// 保护的临界资源...
pthread_cond_wait(&cond, &mutex);
std::cout << pthread_self() << " 活动" << std::endl;
pthread_mutex_unlock(&mutex);
}
}
int main()
{
pthread_t tids[3];
for (int i = 0; i < 3; i++)
{
pthread_create(tids + i, nullptr, thread_run, nullptr);
}
sleep(1);
while (true)
{
pthread_cond_signal(&cond);
sleep(1);
}
for (int i = 0; i < 3; i++)
{
pthread_join(tids[i], nullptr);
}
return 0;
}

🚀条件变量的原理:实际上条件变量内部维护一个队列结构,当一个线程被wait的时候就会插入到队列的尾部等待,当唤醒等待时就是将队列头部的线程唤醒(指的是signal唤醒一个的时候)。
为什么pthread_cond_wait需要互斥量?
🚀使用条件变量是实现线程同步的一种手段,当临界资源不满足要求的时候就将此线程wait,放到条件变量中等待,等到临界资源满足要求的时候再将线程唤醒,所以使用条件变量一定是多线程对临界资源并发访问的情况,所以一定需要互斥量来对临界资源做保护,对临界资源做法判断是否满足要求一定是在加锁之后,在进入条件变量等待之前。所以,线程在进入条件变量中等待之前一定是持有锁的,但是这个线程进入条件变量中等待时,其他线程是可以工作的(也就是说可以去竞争锁的),所以在进入条件变量中等待的时候一定要将锁释放,某则就会造成死锁问题。
🚀并且当线程被唤醒,出条件变量之前一定要重新申请锁,因为线程被唤醒之后,会恢复其上下文继续运行,也就是说会继续在临界区内运行,为了保证临界资源的安全,在线程进入到临界区内的时候必须是持有锁的,所以线程出条件变量之前是要重新申请锁的。
条件变量错误设计
pthread_mutex_lock(&mutex);
while (condition_is_false) {
pthread_mutex_unlock(&mutex);
//解锁之后,等待之前,条件可能已经满足,信号已经发出,但是该信号可能被错过
pthread_cond_wait(&cond);
pthread_mutex_lock(&mutex);
}
pthread_mutex_unlock(&mutex);
🚀由于解锁和等待不是原子操作。当某个线程判断条件不满足时,首先要释放锁,在其进入条件变量中等待之前,可能有其他线程已经申请到了锁,并且给其发送了唤醒的信号,那么此线程就会错过此信号,可能导致线程永远阻塞在这个条件变量中。所以解锁和等待必须是原子操作。
基于阻塞队列的生产消费模型
🚀生产消费模型是多线程同步与互斥的典型例子,生产线程与消费线程通过一个缓冲区(交易场所)来进行数据的交互,并且生产消费模型是一个高效的,忙闲不均的,生产者与消费者解耦的模型。
🚀基于阻塞队列的生产消费模型指的是连接生产线程和消费线程的缓冲区是一个定长的队列,那么这个阻塞队列是被所有线程共享的,就是一份临界资源,那么就要用互斥量对齐保护,保证在任意时刻只有一个线程能够进入临界区,对临界资源修改,所以阻塞队列要配备一把互斥锁。
🚀生产消费模型的特点:
1,三种关系:
(1)生产者与生产者之间是互斥关系。
(2)消费者与消费者之间是互斥互斥关系。
(3)生产者与消费者之间是同步与互斥的关系。
生产者与消费者的同步关系体现在:
当阻塞队列为满的时候,生产者线程就不能再生产了,就要进入到条件变量中等待。
当阻塞队列为空的时候,消费者线程就不能再消费了,就要进入到条件变量中等待。
并且,消费者线程清楚此时缓冲区是否未满,所以消费线程可以根据一定的策略来唤醒生产线程。
同理,生产线程清楚此时缓冲区是否为空,所以生产线程可以根据一定的策略来唤醒等待中的消费线程。
所以,生产线程与消费线程是按照一定的顺序被调度运行的,避免了饥饿问题,所以说生产者与消费者之间存在同步的关系。
生产者与消费者的互斥关系体现在:
由于阻塞队列是一份临界资源,所以在任一时刻,只能有一个线程对临界资源作修改,所以生产者与消费者之间存在互斥关系。
2,两种角色:生产者与消费者
3,一个场所:指的是一个缓冲区
🚀所以,这个模型中不仅要存在一把互斥锁,还要有属于生产者线程的条件变量,属于消费者的条件变量。

🚀生产消费模型的高效体现在哪里?忙闲不均又是如何体现的?
缓冲区作为临界资源,对于生产线程和消费线程来说都是串行执行的,所以这里是体现不出高效性的。
高效性是体现在:当消费者在对数据做处理的时候,生产者此时可以生产数据,也可以将数据输送到缓冲区中。
同理,当生产者在生产数据的时候,消费者可以从缓冲区中取出数据,或者对数据做处理。
它们的忙闲不均也是体现在,如果缓冲区已满时,只有消费线程在工作,同理缓冲区为空的时候,只有生产者在工作。
并且,这个模型也做到了将生产线程与消费线程解耦。
代码实现
LockGuard.hpp
#pragma once
#include <pthread.h>
class Mutex
{
public:
Mutex(pthread_mutex_t *p) : _pmutex(p) {}
void lock() { pthread_mutex_lock(_pmutex); }
void unlock() { pthread_mutex_unlock(_pmutex); }
~Mutex() {}
private:
pthread_mutex_t *_pmutex;
};
class LockGuard
{
public:
LockGuard(pthread_mutex_t *p) : _mutex(p) { _mutex.lock(); }
~LockGuard() { _mutex.unlock(); }
private:
Mutex _mutex;
};
🚀这是对互斥锁的简单封装,创建的LockGuard对象在构造的时候就会加锁,出作用域析构的时候就会自动解锁,不用再去手动的解锁了。
BlockQueue.hpp
#pragma once
#include <queue>
#include <pthread.h>
#include <unistd.h>
#include "LockGuard.hpp"
template <typename T>
class BlockQueue
{
public:
BlockQueue(int capcity = 1) : _capcity(capcity)
{
// 对锁和条件变量初始化
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_cond_consumer, nullptr);
pthread_cond_init(&_cond_productor, nullptr);
}
~BlockQueue()
{
// 对锁和条件变量销毁
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_cond_consumer);
pthread_cond_destroy(&_cond_productor);
}
bool empty() const { return _q.empty(); }
bool full() const { return _capcity == _q.size(); }
void push(const T &t)
{
{
LockGuard guard(&_mutex);
while (full() == true)
{
pthread_cond_wait(&_cond_productor, &_mutex);
}
_q.push(t);
// 生产者生产完就可以唤醒消费者了
pthread_cond_signal(&_cond_consumer);
}
}
void pop(T &got)
{
{
LockGuard guard(&_mutex);
while (empty() == true)
{
pthread_cond_wait(&_cond_consumer, &_mutex);
}
got = _q.front();
_q.pop();
// 消费者消费完可以通知生产者进行生产
pthread_cond_signal(&_cond_productor);
}
}
private:
int _capcity;
std::queue<T> _q;
pthread_mutex_t _mutex;
pthread_cond_t _cond_productor;
pthread_cond_t _cond_consumer;
};

🚀截图中为什么使用while判断,而不是if判断的原因
因为,如果消费者取出数据后,队列中有一个空余的位置,但是生产者的条件变量中阻塞了多个生产者,而此时消费者是通过broadcast来唤醒生产的的话,那就会面临多个生产者而只有一个空位可供生产的问题。
同理,消费者那里也是用while判断。
mythread.cc文章来源:https://www.toymoban.com/news/detail-492723.html
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <cstdlib>
#include "BlockQueue.hpp"
#include "LockGuard.hpp"
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void *thread_productor(void *args)
{
BlockQueue<int> *bq = static_cast<BlockQueue<int> *>(args);
while (true)
{
int x = rand() % 100 + 1;
bq->push(x);
{
LockGuard guard(&mutex);
std::cout << pthread_self() << " push a data : " << x << std::endl;
}
}
return nullptr;
}
void *thread_consumer(void *args)
{
BlockQueue<int> *bq = static_cast<BlockQueue<int> *>(args);
while (true)
{
sleep(1);
int x;
bq->pop(x);
{
LockGuard guard(&mutex);
std::cout << pthread_self() << " pop a data : " << x << std::endl;
}
}
return nullptr;
}
int main()
{
srand((size_t)time(0));
pthread_t P[3];
pthread_t C[3];
BlockQueue<int> *bq = new BlockQueue<int>(3);
pthread_create(P, nullptr, thread_productor, bq);
pthread_create(P + 1, nullptr, thread_productor, bq);
pthread_create(P + 2, nullptr, thread_productor, bq);
pthread_create(C, nullptr, thread_consumer, bq);
pthread_create(C + 1, nullptr, thread_consumer, bq);
pthread_create(C + 2, nullptr, thread_consumer, bq);
for (int i = 0; i < 3; i++)
{
pthread_join(P[i], nullptr);
pthread_join(C[i], nullptr);
}
return 0;
}
 文章来源地址https://www.toymoban.com/news/detail-492723.html
文章来源地址https://www.toymoban.com/news/detail-492723.html
到了这里,关于Linux-线程的同步与互斥的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!