urllib 是一个 python 内置包,不需要额外安装即可使用,包里面包含了以下几个用来处理 url 的模块:
-
urllib.request,用来打开和读取 url,意思就是可以用它来模拟发送请求,就像在浏览器里输入网址然后敲击回车一样,获取网页响应内容。
-
urllib.error,用来处理 urllib.request 引起的异常,保证程序的正常执行。
-
urllib.parse,用来解析 url,可以对 url 进行拆分、合并等。
-
urllib.robotparse,用来解析 robots.txt 文件,判断网站是否能够进行爬取。
掌握以上四个模块,你就能对网站进行简单的爬虫操作,下面我们逐个介绍。
1、urllib.request 模块
urllib.request 模块定义了以下几个函数。
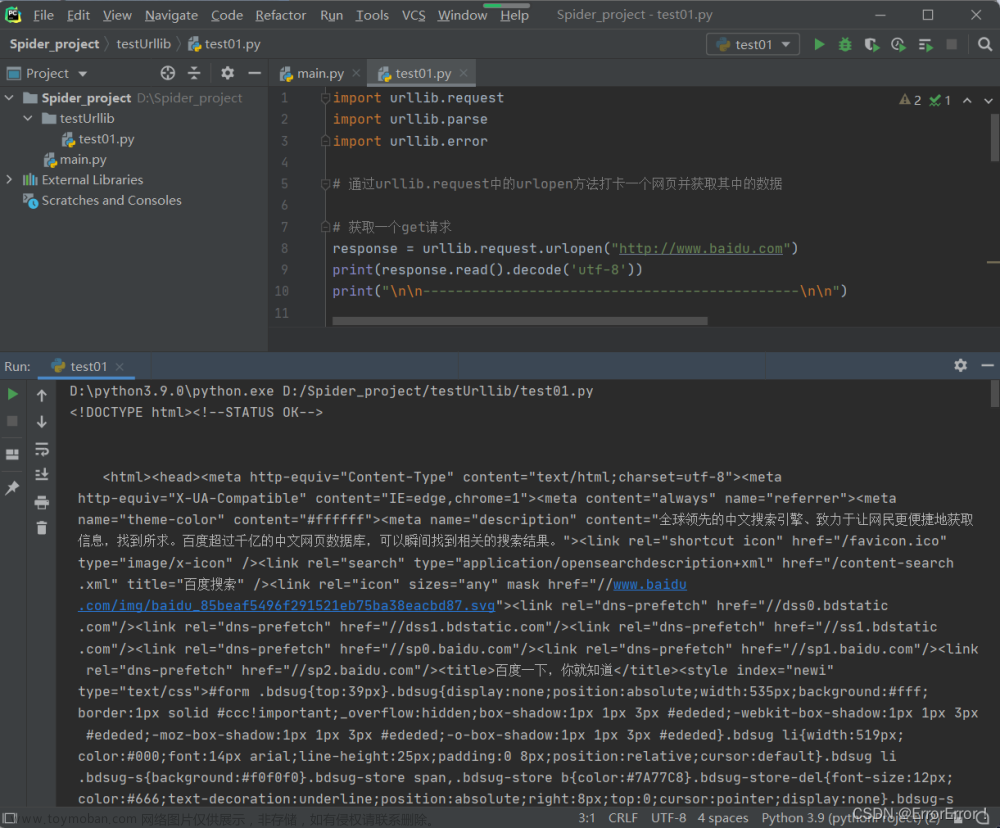
1.1 urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
该函数主要用于模拟网站请求,返回一个 HTTPResponse 类型的对象。
1.1.1 urlopen 函数中参数定义
-
url,必选参数,是一个 str 字符串或者 Request 对象(后面会介绍)。
-
data,bytes 类型的可选参数,如果传递的是字典型数据,可以用 urllib.parse.urlencode() 进行编码,返回 str 字符串,再将 str 转换成 bytes 字节流。如果传递 data 参数,urlopen 将使用 HTTP POST 方式请求,否则为 HTTP GET 请求。
-
timeout,可选参数,设置超时时间(未设置时使用全局默认超时时间),以秒为单位计时,如果 urlopen 请求超出了设置时间还未得到响应则抛出异常。
-
cafile 和 capath,可选参数,在 HTTPS 连接请求时指定已认证的 CA 证书以及证书路径。
-
cadefault,一般可忽略该参数。
-
context,ssl.SSLContext 类型的可选参数,用来指定 SSL 设置。
1.1.2 urlopen 函数返回类型
urlopen 函数请求返回一个 HTTPResponse 响应上下文,或者请求异常抛出 URLError 协议错误,一般有如下属性:
-
geturl(),返回检索的 url,通常用于判定是否进行了重定向。
-
info(),返回网页的头信息。
-
getcode(),返回 HTTPResponse 响应的状态码。
1.1.3 urlopen 函数的应用实例
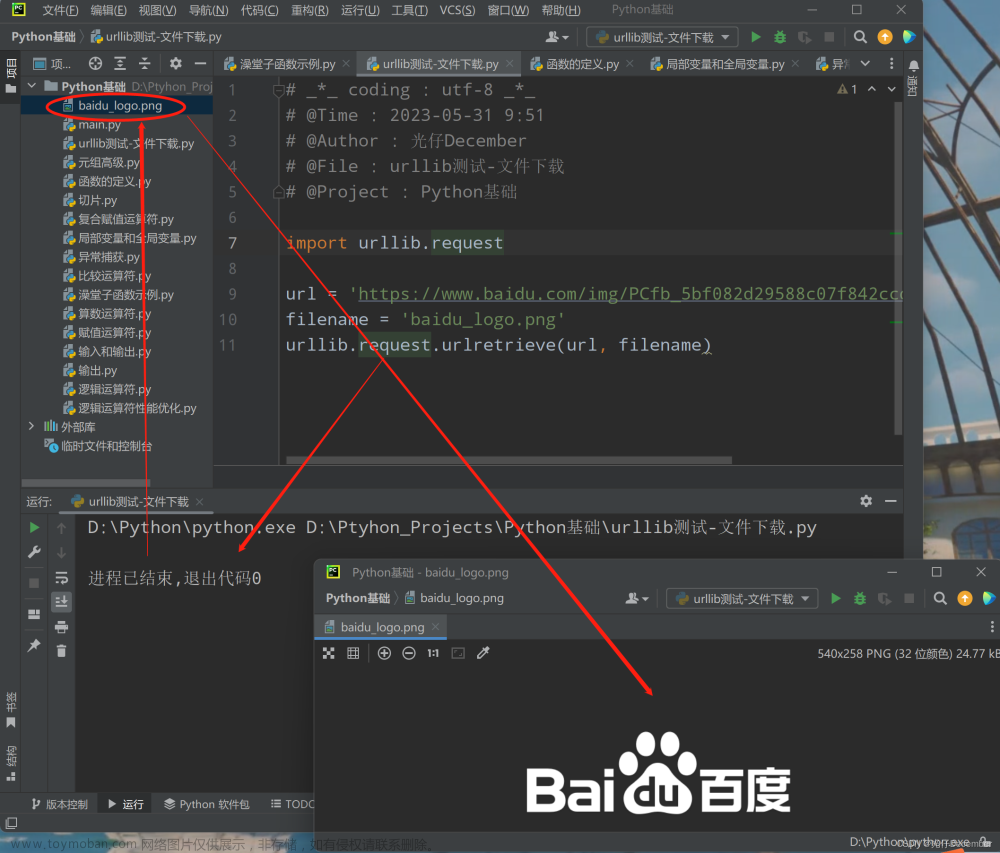
# 创建一个 HTTP GET 请求,输出响应上下文from urllib.request import urlopenresponse = urlopen("http://www.python.org")print(response.read())
# 创建一个 HTTP POST 请求,输出响应上下文from urllib.request import urlopenfrom urllib.parse import urlencodedata = {'kw' : 'python'}data = bytes(urlencode(data), encoding = 'utf-8')response = urlopen("https://fanyi.baidu.com/sug", data)print(response.read().decode('unicode_escape'))
# 创建一个 HTTP GET 请求,设置超时时间为0.1simport urllib.requestimport urllib.errortry:response=urllib.request.urlopen('http://www.python.org',timeout=0.1)print(response.read())except urllib.error.URLError as e:print(e.reason)
1.2 urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
该函数主要用于构造一个 url,返回一个 urllib.request.Request 对象。
1.2.1 Request 函数中参数定义
-
url,必选参数,请求的 url 地址。
-
data,bytes 类型的可选参数。
-
headers,字典类型,有些 HTTP 服务器仅允许来自浏览器的请求,因此通过 headers 来模拟浏览器对 url 的访问,比如模拟谷歌浏览器时使用的 headers:"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36"。可以通过调用 add_header() 来添加 headers 信息。
-
origin_req_host,请求方的 host 名称或者 IP 地址。
-
unverifiable,表示这个请求是否无法验证,默认为 False。比如请求一张图片,如果没有权限获取图片那它的值就是 true。
-
method,是一个字符串,用来指示请求使用的方法,如:GET,POST,PUT 等,默认是 GET 请求。
1.2.2 Request 函数返回类型
与 urlopen 函数请求返回一样,一般返回一个 HTTPResponse 响应上下文。
1.2.3 Request 函数的应用实例
# 采用 HTTP GET 请求的方法模拟谷歌浏览器访问网站,输出响应上下文from urllib import request,parseurl = 'http://www.python.org'headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}req = request.Request(url, headers = headers, method = 'GET')response = request.urlopen(req)print(response.read())
# 采用 HTTP POST 请求的方法模拟谷歌浏览器访问网站,输出响应上下文from urllib import requestfrom urllib import parseurl = 'https://fanyi.baidu.com/sug'data = {'kw' : 'python'}data = bytes(parse.urlencode(data), encoding = 'utf-8')headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}req = request.Request(url, data, headers, method = 'POST')response = request.urlopen(req)print(response.read().decode('unicode_escape'))
# 创建一个 HTTP GET 请求,通过 add_header 添加一个 UserAgentimport urllib.requestimport randomurl = 'http://www.python.org'headerUserAgentList = ['Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36','Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0']randomHeaderUserAgent = random.choice(headerUserAgentList) # 随机选取一个 UserAgentreq = urllib.request.Request(url)req.add_header('User-Agent', randomHeaderUserAgent) # 添加 UserAgentresponse=urllib.request.urlopen(req)print(req.get_header('User-agent'))print(req.headers) # 打印请求的 header 信息
2、 urllib.error 模块
urllib.error 模块定义了由 urllib.request 模块引发的异常,异常主要包含 URLError 和 HTTPError。
2.1 urllib.error.URLError 异常
URLError 类继承自 OSError 类,是 error 异常模块的基类,由request模块产生的异常都可以通过捕获这个类来处理。URLError 只有一个属性 reason,即返回错误的原因。
应用实例:
# 在请求连接时候捕获网址错误引发的异常from urllib import request, errortry:response = request.urlopen('https://www,baidu,com')except error.URLError as e:print(e.reason)
2.2 urllib.error.HTTPError 异常
HTTPError 是 URLError 的子类,专门用来处理 HTTP 请求错误,比如认证请求失败,包含以下三个属性:
-
code:返回 HTTP 响应的状态码,如404页面不存在等。
-
reason:返回错误的原因。
-
headers:返回 HTTP 响应头信息。
应用举例:
# 返回401未授权错误from urllib import request,errortry:response=request.urlopen('http://pythonscraping.com/pages/auth/login.php')print(response.getcode())except error.HTTPError as e:print('1.错误原因:\n%s\n2.状态码:\n%s\n3.响应头信息:\n%s' %(e.reason, e.code, e.headers))except error.URLError as e:print(e.reason)
3、 urllib.parse 模块
urllib.parse 模块定义了一个处理 url 的标准接口,用来实现 url 字符串的抽取、合并以及链接转换。该模块主要用到的函数如下。
3.1 urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)
用于实现 url 字符串的识别和分段,可以分为六个字符串,分别是 scheme (协议),netloc (域名),path (路径),params (参数),query (查询条件)和 fragment (锚点),其结构如下所示:“scheme://netloc/path;parameters?query#fragment”。实际上具体 url 某些字段可能会不存在,比如 “http://www.baidu.com” 只包含了协议和域名。
3.1.1 urlparse 函数中参数定义
-
urlstring,待解析的 url 字符串。
-
scheme,是默认的协议,比如 http 或者 https,url 字符串中如果不携带相关协议,可以通过 scheme 来指定,如果 url 中指定了相关协议则在 url 中生效。
-
allow_fragments,是否忽略锚点,设置为 False 即 fragment 部分会被忽略,反之不会忽略。
3.1.2 urlparse 的返回类型
函数返回的是一个 urllib.parse.ParseResult 对象,获取解析出来的 url 六个字段。
3.1.3 urlparse 应用举例
# 解析并输出 url 中每个字段的字符串import urlliburl = 'http://www.baidu.com/urllib.parse.html;python?kw=urllib.parse#module-urllib'result = urllib.parse.urlparse(url)print(result)print(result.scheme, result.netloc, result.path, result.params, result.query, result.fragment, sep = '\n')
3.2 urllib.parse.urlunparse(parts)
与 urlparse 相反,通过列表或者元祖的形式将分段的字符串组合成一个完整的 url 字符串。
3.2.1 urlunparse 函数中参数定义
-
parts,可以是列表或者元组。
3.2.2 urlunparse 的返回类型
urlunparse 函数返回一个构造好的 url 字符串。
3.2.3 应用举例
# 通过 data 列表或元组构造一个 url 并输出import urllibdataList = ['http', 'www.baidu.com', '/urllib.parse.html', 'python', 'kw=urllib.parse', 'modul-urllib'] # 六个字符串都必须填写,否则会出现 ValueError 错误,如果某一字符串不存在则填入空字符dataTuple = ('http', 'www.baidu.com', '/urllib.parse.html', '', 'kw=urllib.parse', 'modul-urllib') # 六个字符串都必须填写,否则会出现 ValueError 错误,如果某一字符串不存在则填入空字符urlList = urllib.parse.urlunparse(dataList)urlTuple = urllib.parse.urlunparse(dataTuple)print('1.urlList:%s\n2.urlTuple:%s' % (urlList, urlTuple))
3.3 urllib.parse.urlsplit(urlstring, scheme='', allow_fragments=True)
与 urlparse 函数类似,但它只返回 url 字符串的5个字段,把 params 合并到 path 中。
urlsplit 应用举例
# 解析并输出 url 中每个字段的字符串,params 会合并到 path 中。import urlliburl = 'http://www.baidu.com/urllib.parse.html;python?kw=urllib.parse#modul-urllib'result = urllib.parse.urlsplit(url)print(result)print(result.scheme, result.netloc, result.path, result.query, result.fragment, sep = '\n')
3.4 urllib.parse.urlunsplit(parts)
与 urlunparse 函数类似,它也是将 url 中各部分字段组合完整的 url 字符串的方法,唯一的区别是列表或元组的长度必须是5个,因为它把 params 省略了。
urlunsplit 应用举例
# 通过 data 列表或元组构造一个 url 并输出import urllibdataList = ['http', 'www.baidu.com', '/urllib.parse.html;python', 'kw=urllib.parse', 'modul-urllib'] # 五个字符串都必须填写,否则会出现 ValueError 错误,如果某一字符串不存在则填入空字符dataTuple = ('http', 'www.baidu.com', '/urllib.parse.html;python', 'kw=urllib.parse', 'modul-urllib') # 五个字符串都必须填写,否则会出现 ValueError 错误,如果某一字符串不存在则填入空字符urlList = urllib.parse.urlunsplit(dataList)urlTuple = urllib.parse.urlunsplit(dataTuple)print('1.urlList:%s\n2.urlTuple:%s' % (urlList, urlTuple))
3.5 urllib.parse.quote(string, safe='/', encoding=None, errors=None)
使用 %xx 转义字符替换字符串中的特殊字符,比如汉字。字母、数字和‘_.-~’字符不会被替换。
3.5.1 quote 函数中参数定义
-
string,可以是 str 字符串或 bytes 类型。
-
safe,可选参数,默认是'/',指明不应该被替换的附加 ASCII 字符。
-
encoding 和 errors,可选参数,用来定义如何处理 non-ASCII 字符。一般默认设置编码方法为 encoding='utf-8',errors='strict',这意味着编码错误将引发 UnicodeError。如果 string 是 bytes 类型,不能设置 encoding 和 errors,否则将引发 TypeError。
3.5.2 quote 函数的返回类型
quote 函数返回一个编码后的字符串。
3.5.3 应用举例
# 采用 quote 对 url 中的汉字进行编码,输出编码后的结果import urlliburl = 'http://www.baidu.com/爬虫'result = urllib.parse.quote(url)print(result)url = 'http://www.baidu.com/+爬虫'result = urllib.parse.quote(url, '+') # 更改 safe 参数print(result)
3.6 urllib.parse.unquote(string, encoding='utf-8', errors='replace')
与 quote 函数相反,把 %xx 转义字符替换成字符。
3.6.1 unquote 函数的参数定义
-
string,必须是 str 字符串。
-
encoding 和 errors,可选参数,定义如何将 %xx 转义字符解码为 Unicode 字符。encoding 默认为 'utf-8',errors 默认为 'replace',表示无效的转义字符将会用占位符替换。
3.6.2 unquote 函数的返回类型
unquote 函数返回一个解码后的字符串。
3.6.3 应用举例
# 解码经过 quote 函数处理后的 url,输出解码后的结果。import urlliburl = 'http://www.baidu.com/爬虫'result = urllib.parse.quote(url)print(result)result = urllib.parse.unquote(url)print(result)
3.7 urllib.parse.urljoin(base, url, allow_fragments=True)
该函数用来将基本 url 与另一个 url 组合,更新基本 url 字符串。它会使用 url 对基本 url 中缺失的部分进行补充,比如 scheme (协议)、netloc (域名)和 path (路径)。即根据 url 字符串中带有的字段,对基本 url 中没有的字段进行补充,已存在的字段进行替换。
3.7.1 urljoin 函数中参数定义
-
base,是一个基本 url。
-
url,将 scheme (协议)、netloc (域名)或 path (路径)字段组合进基本 url 的 url。
-
allow_fragments,是否忽略锚点,设置为 False 即 fragment 部分会被忽略,反之不会忽略。
3.7.2 urljoin 函数返回类型
返回组合成功的 url 字符串。
3.7.3 应用举例
# 基于 url 对 base_url 进行重新组合,并输出组合结果。import urllibbase_url = 'http://www.baidu.com'url = 'https://www.google.com/urllib.parse.html;python?kw=urllib.parse#module-urllib'result = urllib.parse.urljoin(base_url,url,False)print(result)
3.8 urllib.parse.urlencode(query, doseq=False, safe='', encoding=None, errors=None, quote_via=quote_plus)
urlencode 函数可以将字典转化为 GET 请求中的 query (查询条件),或者将字典转化为 POST 请求中需要上传的数据。
3.8.1 urlencode 函数中参数定义
-
query,字典类型。
-
doseq,允许字典中一个键对应多个值,编码成 query (查询条件)。
-
safe、encoding 和 errors,这三个参数由 quote_via 指定。
3.8.2 urlencode 函数返回类型
urlencode 函数返回 str 字符串。
3.8.3 应用举例
# 创建 GET 请求import urllibparams = {'username':'xxx','password':'123'}base_url='http://www.baidu.com'url=base_url + '?' + urllib.parse.urlencode(params)print(url)params = {'username':['xxx', 'yyy'], 'password':'123'} # username 键对应多个值base_url='http://www.baidu.com'url=base_url + '?' + urllib.parse.urlencode(params) # doseq 设置为 False,会解析成乱码print(url)url=base_url + '?' + urllib.parse.urlencode(params, True) # doseq 设置为 Trueprint(url)
4、 urllib.robotparse 模块
rebotparser 模块提供了一个 RobotFileParser 类,主要用来解析网站上发布的 robots.txt,然后根据解析内容判断爬虫是否有权限来爬取这个网页。
4.1 robots.txt 文件
robots.txt,存放于网站根目录下,采用 ASCII 编码的文本文件,记录此网站中的哪些内容是不应被爬虫获取的,哪些是可以被爬虫获取的。
robots.txt 文件内容举例
User-agent: * Disallow: / Allow: /public/
-
User-agent,爬虫的名称,将其设置为 * 代表协议对任何爬虫有效,如果设置为 Baiduspider 则代表协议仅对百度爬虫有效,要是有多条则对多个爬虫有效,至少需要指定一条。
-
Disallow,网页中不允许抓取的目录,上述例子中设置的 / 代表不允许抓取所有的页面。
-
Allow,一般和 Disallow 一起使用,用来排除单独的某些限制,上述例子中设置为 /public/ 表示所有页面不允许抓取,但可以抓取 public 目录。
4.2 urllib.robotparser.RobotFileParser(url='') 类及其常用方法
-
set_url(url),设置引用 robots.txt 文件的 url,如果在创建 RobotFileParser 对象时传入了 url,那么就不需要使用这个方法设置 url。
-
read(),读取 robots.txt 文件并将其提供给解析器,不返回任何内容。
-
parse(lines),用来解析 robots.txt 某些行的内容,并安装语法规则来分析内容。
-
can_fetch(useragent, url),传入两个参数,用户代理以及要爬取的网站,返回的内容是该用户代理否可以抓取这个网站,结果为 True 或 False。
应用举例文章来源:https://www.toymoban.com/news/detail-492875.html
# 使用两种爬虫代理分别查看是否可以对 'http://www.baidu.com' 网站进行爬取from urllib.robotparser import RobotFileParserrp = RobotFileParser()rp.set_url("http://www.baidu.com/robots.txt")rp.read()print(rp.can_fetch('Baiduspider', 'http://www.baidu.com'))print(rp.can_fetch('*', 'http://www.baidu.com'))
总结
本节给大家介绍了 Python 中 urllib 包的使用,为 Python 工程师对该包的使用提供了支撑,了解爬取网站所需的一些基本函数操作。文章来源地址https://www.toymoban.com/news/detail-492875.html
到了这里,关于Python 爬虫之 urllib 包基本使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[Python]爬虫基础——urllib库](https://imgs.yssmx.com/Uploads/2024/02/435181-1.png)







