CVPR2022
Preliminary
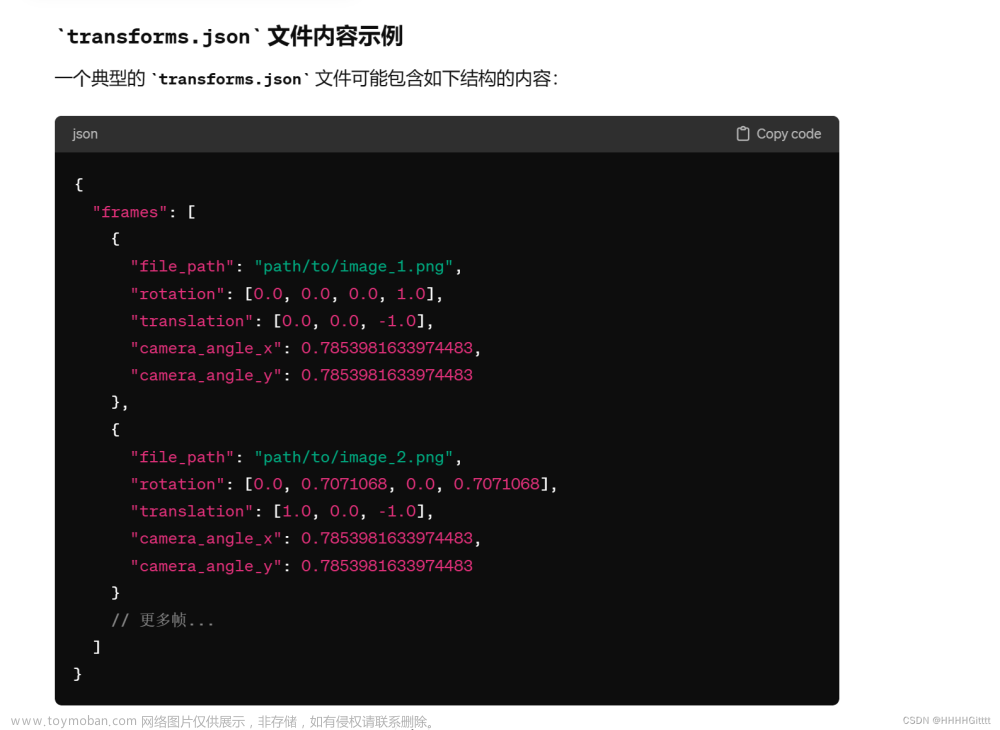
- 首先我们由一组室内的RGB图像 { I i } i = 0 N − 1 , I i ∈ [ 0 , 1 ] H × W × 3 \{I_i\}^{N-1}_{i=0}, I_i \in [0,1]^{H \times W \times 3} {Ii}i=0N−1,Ii∈[0,1]H×W×3。
- 通过SFM的方法,我们可以获得相机位姿 p i ∈ R 6 p_i \in \mathbb{R}^6 pi∈R6, 内参矩阵 K i ∈ R 3 × 3 K_i \in \mathbb{R}^{3 \times 3} Ki∈R3×3以及稀疏的深度图 Z i s p a r s e ∈ [ 0 , t f ] H × W Z^{sparse}_i \in [0,t_f]^{H \times W} Zisparse∈[0,tf]H×W。
Method
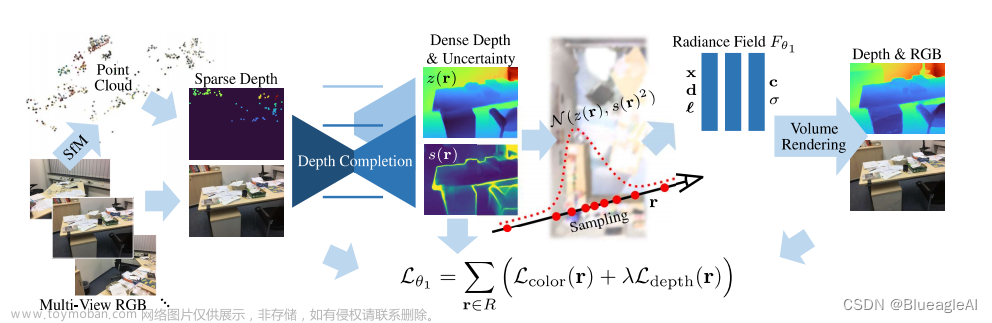
Depth Completion with Uncertainty
- 论文指出了稀疏深度重建过程中的两个问题,第一,稀疏点是由噪声以及离群点的。第二,稀疏深度点在不同图像上的数量以及位置都变化显著。
- 针对第一点,论文在预测稠密深度的同时预测方差,类似于Uncertainty的做法。简单来说,就是在进行深度补全过程中,针对离群点和噪声点的限制进行放缩并通过不确定性估计标记噪声和离群点位置,具体可以参考[1].
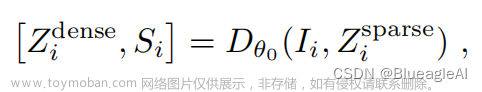
- 也就会形成这样的损失函数:
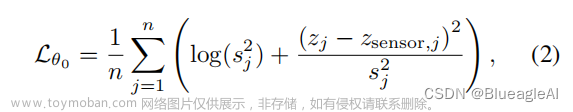
- 在训练过程中,训练数据的Sparse Depth是从 Sensor Dense Depth中采样来的,为了保证稀疏深度点的真实,会通过SIFT特征点匹配的方法决定深度点的位置。
Radiance Field with Dense Depth Priors
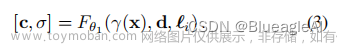 文章来源:https://www.toymoban.com/news/detail-493251.html
文章来源:https://www.toymoban.com/news/detail-493251.html
- 这里对NeRF的表示方法中嵌入了一个向量 l ∈ R e \mathscr{l} \in \mathbb{R}^e l∈Re。这使得网络能够补偿不一致的照明以及镜头阴影等。
- NeRF深度估计和方差可以通过以下公式获得:
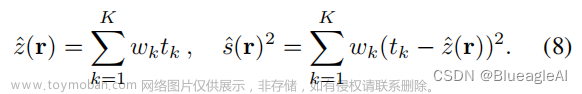
- 对于深度的监督Loss如下:

Reference
[1]Zhu Y, Dong W, Li L, et al. Robust depth completion with uncertainty-driven loss functions[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2022, 36(3): 3626-3634.文章来源地址https://www.toymoban.com/news/detail-493251.html
到了这里,关于论文阅读:Dense Depth Priors for Neural Radiance Fields from Sparse Input Views的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!