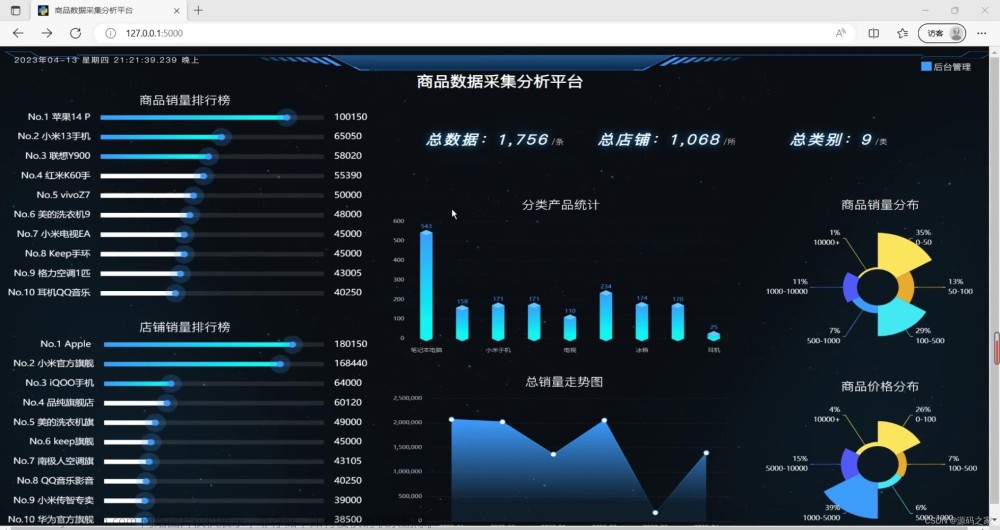
一、数据分析思路
大概可以分为下面这几个步骤:
- 数据采集;
- 原始数据完整性检查;
- 数据清洗、整理;
- 从不同角度对数据进行分析;
- 数据可视化;
- 总结;
主要使用 Python 来进行分析:
- 数据采集: 主要涉及的 python 库包括 requests,BeautifulSoup,csv,以及一些其他常用工具。
- 数据完整性检查: 包括不同数据来源的对比,以及其他一些常识性的知识。需要对比数据量的多少是否完整,以及有些数据是否缺失。
当然,在拿到数据的初期,其实只能做一个初步的判断,有些内容是在整个分析过程中发现的。
- 数据清洗与整理: 主要用到 Pandas、Numpy 以及其他常用库和函数。由于数据比较杂乱,数据清洗与整理涉及的内容比较多,可以说是整个福布斯系列的重点之一。
同时,这个也印证了通常我们所说的数据清洗与整理可能占整个分析的 50~80%。
- 数据分析与可视化: 经常是伴随在一起的。主要根据不同分析目的进行分析与可视化。用到的工具包括 Pandas、Numpy、Matplotlib、Seaborn 以及其他一些相关库。
二、数据分析案例
福布斯每年都会发布福布斯全球上市企业 2000 强排行榜(Forbes Global 2000),这个排行榜每年发布的时候,国内外总有新闻会热闹的讨论一番,但很少见到比较全面的分析。文章来源:https://www.toymoban.com/news/detail-493275.html
因此才有了这样一个想法,搜集近些年每年发布的排行榜,做一个进一步的分析。文章来源地址https://www.toymoban.com/news/detail-493275.html
1、数据采集
到了这里,关于Python 数据采集、清洗、整理、分析以及可视化实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!