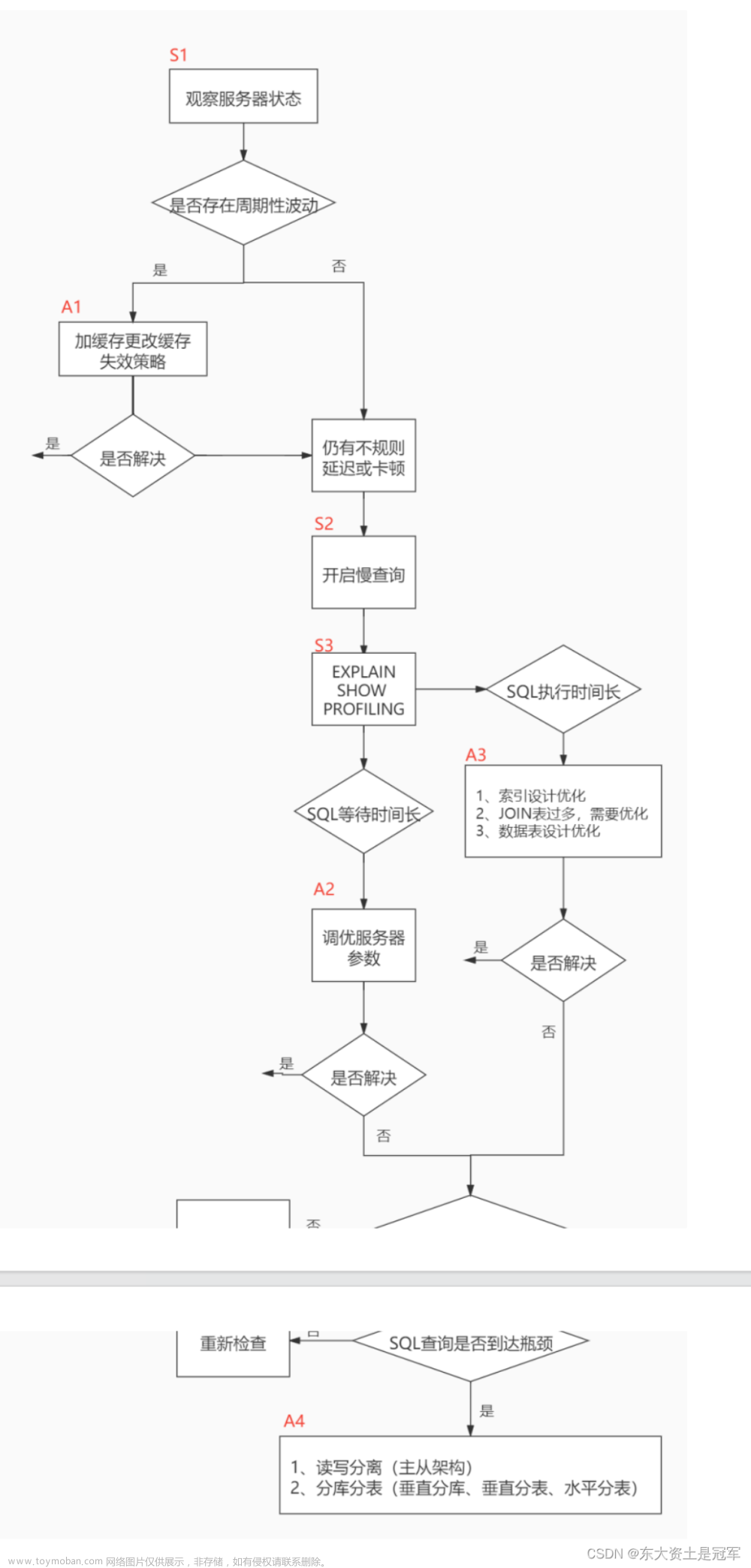
概述
前文我们写过简单SQL的性能分析和解读,简单SQL被归类为select-from-where型SQL语句,其主要特点是只有map阶段的数据处理,相当于直接从hive中取数出来,不需要经过行变化。在非多个节点的操作上,其性能甚至不比Tez和Spark差。
而这次我们主要说的是使用聚合类函数的hiveSQL,这类SQL需要完整的map阶段和reduce阶段才能完成数据处理。我们把它可以归类为select-aggr_function-from-where-groupby 类型SQL语句。
在生产环境中我们一般常用的聚合函数见如下列表:
| 函数 | 参数格式 | 解释 |
|---|---|---|
| count | count(*), count(expr),count(distinct expr) | 返回查找的总行数,count(*)返回的行数包括null值;count(expr)和count(distinct expr) 不包括null值 |
| sum | sum(col), sum(DISTINCT col) | sum(col)返回组内查询列元素的总和,sum(DISTINCT col)返回组内查询列列的不同值的总和 |
| avg | avg(col), avg(DISTINCT col) | sum(col)返回组内查询列元素的平均值,sum(DISTINCT col)返回组内查询列的不同值的平均值 |
| min | min(col) | 返回组内查询列的最小值 |
| max | max(col) | 返回组内查询列的最大值 |
| variance/var_pop | variance(col)/var_pop(col) | 返回组内查询列的方差(也可称为总体方差),也可写成var_pop(col) |
| var_samp | var_samp(col) | 返回组内查询列方差的无偏估计(方差无偏估计中,因为估计期望损失了一个自由度,估计的分母为n-1,也可称为样本方差) |
| stddev_pop | stddev_pop(col) | 返回组内查询列的标准差 |
| stddev_samp | stddev_samp(col) | 返回组内查询列标准差的无偏估计方差(无偏估计中,因为估计期望损失了一个自由度,估计的分母为n-1) |
| covar_pop | covar_pop(col1, col2) | 返回组内查询列col1和col2的总体协方差 |
| covar_samp | covar_samp(col1, col2) | 返回组内查询列col1和col2的样本协方差 |
| corr | corr(col1, col2) | 返回组内查询列col1和col2的相关系数 |
| percentile | percentile(BIGINT col, p) | 返回组内查询整数列col所在的分位数,p可以为浮点数或数组,且其中元素大小必须在0-1之间。若col不是整数,需使用percentile_approx |
| percentile_approx | percentile_approx(DOUBLE col, array(p1[, p2]…) [, B]) | 返回组内查询列col所在的分位数,p可以为浮点数或数组,且其中元素大小必须在0-1之间。B为可选参数,为精度控制参数 |
| regr_avgx | regr_avgx(independent, dependent) | 计算自变量的平均值。该函数将任意一对数字类型作为参数,并返回一个double。任何具有null的对都将被忽略。如果应用于空集:返回null。否则,它计算以下内容:avg(dependent) |
| regr_avgy | regr_avgy(independent, dependent) | 计算因变量的平均值。该函数将任意一对数字类型作为参数,并返回一个double。任何具有null的对都将被忽略。如果应用于空集:返回null。否则,它计算以下内容:avg(independent) |
| regr_count | regr_count(independent, dependent) | 返回independent和dependent都非空的对数 |
| regr_intercept | regr_intercept(independent, dependent) | 返回线性回归的截距项 |
| regr_r2 | regr_r2(independent, dependent) | 返回线性回归的判决系数(R方,coefficient of determination) |
| regr_slope | regr_slope(independent, dependent) | 返回线性回归的斜率系数 |
| regr_sxx | regr_sxx(independent, dependent) | 等价于regr_count(independent, dependent) * var_pop(dependent) |
| regr_sxy | regr_sxy(independent, dependent) | regr_count(independent, dependent) * covar_pop(independent, dependent) |
| regr_syy | regr_syy(independent, dependent) | regr_count(independent, dependent) * var_pop(independent) |
| histogram_numeric | histogram_numeric(col, b) | 用于画直方图。返回一个长度为b的数组,数组中元素为(x,y)形式的键值对,x代表了直方图中该柱形的中心,y代表可其高度。 |
| collect_set | collect_set(col) | 返回查询列col去重后的集合,与distinct不同,distinct查询结果为一列数据,collect_set查询后结果为一个集合形式的元素 |
| collect_list | collect_list(col) | 返回查询列col的列表 |
| ntile | ntile(INTEGER x) | 将有序分区划分为x个称为存储桶的组,并为该分区中的每一行分配存储桶编号。 (此方式存储可以快速计算分位数) |
对于带聚合函数的SQL逻辑,我们可以根据其执行过程的不同,将其分成三大类来进行分析:
- 仅在Reduce阶段聚合的SQL执行逻辑
- 在Map和Reduce阶段都有聚合操作的SQL执行逻辑
- 高级分组聚合的执行SQL逻辑
1.仅在Reduce阶段聚合的SQL执行逻辑
我们通过SQL执行计划来解读Reduce阶段聚合的SQL逻辑,如一下实例:
例1 在Reduce阶段进行聚合的SQL逻辑
set hive.map.aggr=false;
explain
-- 小于30岁人群的不同性别平均年龄
select gender,avg(age) as avg_age from temp.user_info_all where ymd = '20230505'
and age < 30
group by gender;
其执行结果如下内容:
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: user_info_all
Statistics: Num rows: 32634295 Data size: 783223080 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (age < 30) (type: boolean)
Statistics: Num rows: 10878098 Data size: 261074352 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: gender (type: int)
sort order: +
Map-reduce partition columns: gender (type: int)
Statistics: Num rows: 10878098 Data size: 261074352 Basic stats: COMPLETE Column stats: NONE
value expressions: age (type: bigint)
Reduce Operator Tree:
Group By Operator
aggregations: avg(VALUE._col0)
keys: KEY._col0 (type: int)
mode: complete
outputColumnNames: _col0, _col1
Statistics: Num rows: 5439049 Data size: 130537176 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: true
Statistics: Num rows: 5439049 Data size: 130537176 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
以上内容的具体关键字就不作解读了,在Hive执行计划之一文读懂Hive执行计划 中已经做了完整的解释,看不懂请回看。
从上述信息中可以看到Map阶段的解析被分解为常规的三大步骤。
- TableScan
- Filter Operator
- Reduce Output Operator
Reduce阶段的解析被分解为两步:
- Group By Operator
- File Output Operator
对比之前简单SQL执行步骤过程。

可以直观看出简单SQL的执行逻辑主要是在进行列投影后就直接将数据写入本地。而在聚合函数的SQL执行过程中使用到了Reduce阶段,多了输出到reduce阶段和分组聚合操作。
其中从map阶段输出到reduce阶段的这个流程,我们称之为数据的shuffle。后续有机会可以详细讲解其过程。
通过以上案例,可以直观的看出该SQL逻辑在map阶段没有计算的操作,只是对数据进行了一个重新组织,之后在写入reduce,即shuffle的过程进行排序,写内存,写磁盘,然后网络传输等工作。这块如果在map阶段的数据量很大,就会占用比较多的资源。
那么如何进行优化呢?
2.在map和reduce阶段聚合的SQL逻辑
以上例1,可以看到我设置了一个参数set hive.map.aggr=false;
该参数我的集群是默认开启的,为了演示我这里设置关闭。这参数本身开启后起到的作用是提前在map阶段进行数据汇总,即Combine操作。
map端数据过大一般的优化方式有两种:
- 启用Combine操作,进行提前聚合,进而减少shuffle的数据量,减少资源消耗。
- 启用数据压缩来减少Map和Reduce之间传输的数据量。
一般的数据压缩方式就是我们在hive上使用的数据存储格式和数据压缩方法。
启用Combine操作,在hive中提供了对应的参数,set hive.map.aggr=true;通过该配置可以控制是否启用Map端的聚合。
可以看如下例子:
例2 启用Map端聚合的SQL逻辑
同样的SQL逻辑
set hive.map.aggr=true;
explain
-- 小于30岁人群的不同性别平均年龄
select gender,avg(age) as avg_age from temp.user_info_all where ymd = '20230505'
and age < 30
group by gender;
其执行计划结果如下:
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: user_info_all
Statistics: Num rows: 32634295 Data size: 783223080 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (age < 30) (type: boolean)
Statistics: Num rows: 10878098 Data size: 261074352 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: avg(age)
keys: gender (type: int)
mode: hash
outputColumnNames: _col0, _col1
Statistics: Num rows: 10878098 Data size: 261074352 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 10878098 Data size: 261074352 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: struct<count:bigint,sum:double,input:bigint>)
Reduce Operator Tree:
Group By Operator
aggregations: avg(VALUE._col0)
keys: KEY._col0 (type: int)
mode: mergepartial
outputColumnNames: _col0, _col1
Statistics: Num rows: 5439049 Data size: 130537176 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: true
Statistics: Num rows: 5439049 Data size: 130537176 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
这里说明一下 value expressions: _col1 (type: struct<count:bigint,sum:double,input:bigint>)
在map阶段的最后map端最终输出的结果为一个结构体struct。其中map阶段不能计算平均值,只能计算总数和对应个数,这两者分别对应结构体中的sum和count。
将以上逻辑进行流程化。

对比例1 操作流程图,可以看出来例2 在map阶段多了一个分组聚合操作。
文字描述:先将本地节点的数据进行一个初步聚合,求出该性别的年龄相加总数和用户个数。这就已经极大的减少了数据量。之后再进行数据shuffle(分发)过程,将各个节点的数据进行汇总,之后在reduce阶段,再进行二次聚合。将各个节点的求和值和计数值汇总。在得到具体的平均值。该计算完成,输出。
以上,开启map端聚合,这也是hive在使用聚合函数过程中的最常用的一个优化方式。
hive.map.aggr=true;
那么,有一个问题,如何解决map端的数据倾斜问题?以下为常规手段。
-
在mr程序上我们可以说开启Combine模式,进行map端聚合,hive上我们可以说开启map端聚合参数。
-
还有,采用更优的压缩算法和数据存储格式。
思考一下,以上方式其实更多的是提供一个将大量数据变小的方式,那么map端真正的数据倾斜是什么造成的,核心该如何处理。
下一期:什么是hive的高级分组聚合,它的用法和注意事项有哪些
按例,欢迎点击此处关注我的个人公众号,交流更多知识。文章来源:https://www.toymoban.com/news/detail-493438.html
后台回复关键字 hive,随机赠送一本鲁边备注版珍藏大数据书籍。文章来源地址https://www.toymoban.com/news/detail-493438.html
到了这里,关于HiveSQL在使用聚合类函数的时候性能分析和优化详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!