Mysql数据库锁(Innodb)
数据库锁是Mysql实现数据一致性的基础之一,是在事务的基础之上,基于Mysql Server层或存储引擎层实现的。
锁日志
前置条件:
set GLOBAL innodb_status_output=ON;
set GLOBAL innodb_status_output_locks=ON;
查看语句:
show engine innodb status\G;
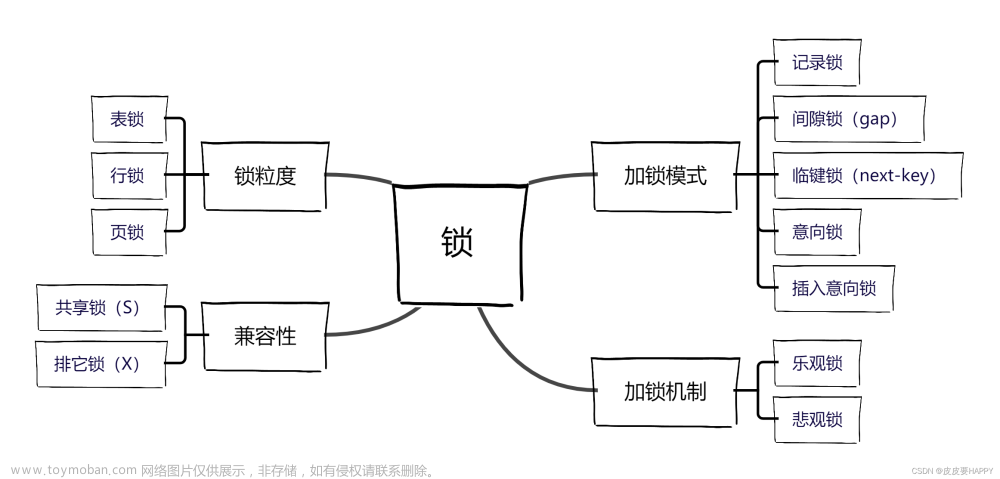
锁分类
表锁与行锁
按照锁的粒度,可以分为表锁和行锁
共享锁与排他锁
-
共享锁
1. select *** lock in share mode 2. Lock Table *** read -
排他锁
1. select *** for update 2. Lock Table *** write
意向锁
-
意向锁是表级的
-
同样具有意向共享锁(IS)、意向排他锁(IX)
-
TABLE LOCK table *** trx id *** lock mode IX、TABLE LOCK table *** trx id *** lock mode IS -
意向锁不会与行级锁冲突,并且意向锁之间没有互斥关系
-
意向锁的意义是用于协调表锁与行锁之间的互斥关系,确保事务可以正确的请求和释放锁。如果没有意向锁,当对全表加锁时,需要遍历全表,判断是否存在某些行记录被加了行锁,那么这个加表锁的操作的性能会差很多。有了意向锁,A事务对某行记录加锁时会先申请意向锁,申请成功后再加行锁,加锁成功后,B事务申请表级锁时会先判断表上面的意向锁是否兼容。
-
意向共享锁(IS锁):事务在请求S锁之前,先获取IS锁
意向排他锁(IX锁):事务在请求X锁之前,先获取IX锁
-
兼容性:
意向共享锁(IS) 意向排他锁(IX) 意向共享锁(IS) 兼容 兼容 意向排他锁(IX) 兼容 兼容 意向共享锁(IS) 意向排他锁(IX) 表级共享锁(S) 兼容 互斥 表级排他锁(X) 互斥 互斥
记录锁(Record Lock)
-
RECORD LOCKS *** index uniq_idx of table *** trx id *** lock_mode X locks rec but not gap、RECORD LOCKS *** index uniq_idx of table *** trx id *** lock_mode S locks rec but not gap - 基于索引创建的,受索引的影响
- 同样具有共享、排他的区别
间隙锁(Gap Lock)
- 间隙锁是RR模式避免幻读的基础
- 顾名思义,锁住的是范围,比如(-∞,10),(10,15)等开区间
RECORD LOCKS *** index idx_c of table *** trx id *** lock_mode X locks gap before rec
临键锁(Next-Key Locks)
- 记录锁、间隙锁的组合就是临键锁
- 临键锁是申请锁时,默认先申请的锁类型,如果申请失败,则进行降级,将为间隙锁或记录锁
- 不仅锁住记录,还会锁住间隙,比如(-∞,10],(10,15]等区间,前开后闭区间
RECORD LOCKS *** index idx_c of table *** trx id *** lock_mode X
插入意向锁(Insert Intention Locks)
-
RECORD LOCKS *** index PRIMARY of table *** trx id *** lock_mode X insert intention waiting -
插入意向锁可以理解为特殊的Gap锁的一种,用来提高并发写的性能。当遇到主键或唯一键冲突时,会退化为读锁
-
插入意向锁和插入意向锁之间不会互斥(只要记录本身唯一键、主键不冲突)。
示例:
事务A插入数据27时,获取到的是(25,30)的间隙锁和27的行锁,事务B插入数据28时,获取到的也是(25,30)的间隙锁和28的行锁。
因为行锁27和行锁28不是同一行,所以不会冲突,然后两个事务获取到的插入意向锁不会互相排斥,所以可以插入成功。
自增锁(AUTO-INC Locks)
TABLE LOCK table *** trx id *** lock mode AUTO-INC waiting- 自增锁处于表级别的锁
元数据锁(metadata lock)
-
Server层实现的锁,与引擎层无关
-
执行select时,如果有ddl语句,那么ddl会被阻塞(非online ddl),因为select语句有metadata lock,防止元数据被改掉。
非online ddl的问题:
select操作会先获取 元数据共享锁(shared MDL),而DDL 操作会先获取元数据排他锁(exclusive MDL), 而且不仅仅是先select后ddl 导致ddl阻塞,
而且ddl后面的select也会被阻塞,因为ddl申请元数据排他锁的优先级要比select操作的优先级要高,只有ddl操作完成后,后面的select才会顺利获取元数据共享锁,才能继续执行,因此ddl操作的花费是昂贵的,因此才出现online DDL;
锁解读
RR下的有二级索引的情况
CREATE TABLE `a` (
`a` int(11) NOT NULL,
`b` int(11) DEFAULT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
`aaa` bigint(20) DEFAULT '0',
PRIMARY KEY (`a`),
UNIQUE KEY `idx_b` (`b`),
KEY `idx_c` (`c`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;

select * from a WHERE c = 7 for UPDATE;
MySQL thread id 10, OS thread handle 139897622177536, query id 377 172.18.0.1 wss
对a表添加意向排他锁
TABLE LOCK table `demo`.`a` trx id 480393 lock mode IX
对a表的idx_c二级索引加临键锁
RECORD LOCKS space id 97 page no 5 n bits 72 index idx_c of table `demo`.`a` trx id 480393 lock_mode X
Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
二级索引idx_c的7加锁
0: len 4; hex 80000007; asc ;;
主键索引上的3也会被加锁
1: len 4; hex 80000003; asc ;;
对主键索引加记录锁,对3进行加锁
RECORD LOCKS space id 97 page no 3 n bits 72 index PRIMARY of table `demo`.`a` trx id 480393 lock_mode X locks rec but not gap
Record lock, heap no 3 PHYSICAL RECORD: n_fields 7; compact format; info bits 0
第一个字段是主键,被加锁
0: len 4; hex 80000003; asc ;;
最近一次被更新的事务id
1: len 6; hex 000000009c29; asc );;
回滚指针
2: len 7; hex be00000147011c; asc G ;;
该行第2、3、4、5个字段
3: len 4; hex 80000005; asc ;;
4: len 4; hex 80000007; asc ;;
5: len 4; hex 80000009; asc ;;
6: len 8; hex 8000000000000000; asc ;;
对idx_c索引树上加间隙锁
RECORD LOCKS space id 97 page no 5 n bits 72 index idx_c of table `demo`.`a` trx id 480393 lock_mode X locks gap before rec
Record lock, heap no 4 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
二级索引idx_c上对9加锁
0: len 4; hex 80000009; asc ;;
主键索引上的5也会被锁住
1: len 4; hex 80000005; asc ;;
RR下的无二级索引的情况
CREATE TABLE `tm` (
`i` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;

SELECT * FROM tm WHERE i = 1 FOR UPDATE;
MySQL thread id 25, OS thread handle 139897622718208, query id 556 172.18.0.1 wss
对tm表添加意向排他锁
TABLE LOCK table `demo`.`tm` trx id 480412 lock mode IX
由于表定义没有显示的索引,而InnoDB又是索引组织表,会自动创建一个索引,这里面叫index GEN_CLUST_INDEX
由于没有索引,那么会对每条记录都加上临键锁
RECORD LOCKS space id 110 page no 3 n bits 80 index GEN_CLUST_INDEX of table `demo`.`tm` trx id 480412 lock_mode X
supremum 指的是页里面的最后一条记录(伪记录,通过select查不到,并不是真实记录);还有Infimum表示页面中的第一个记录(伪记录)
通过supremum 锁住index GEN_CLUST_INDEX的最大值到正无穷大的区间,这样就可以锁住全部记录,以及全部间隙,相当于表锁
Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 0
0: len 8; hex 73757072656d756d; asc supremum;;
Record lock, heap no 2 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 6; hex 000000000300; asc ;;
1: len 6; hex 00000007548e; asc T ;;
2: len 7; hex ea000001960110; asc ;;
3: len 4; hex 80000001; asc ;;
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 6; hex 000000000301; asc ;;
1: len 6; hex 00000007548e; asc T ;;
2: len 7; hex ea00000196011e; asc ;;
3: len 4; hex 80000002; asc ;;
Record lock, heap no 4 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 6; hex 000000000302; asc ;;
1: len 6; hex 00000007548e; asc T ;;
2: len 7; hex ea00000196012c; asc ,;;
3: len 4; hex 80000003; asc ;;
Record lock, heap no 5 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 6; hex 000000000303; asc ;;
1: len 6; hex 00000007548e; asc T ;;
2: len 7; hex ea00000196013a; asc :;;
3: len 4; hex 80000004; asc ;;
Record lock, heap no 6 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 6; hex 000000000304; asc ;;
1: len 6; hex 00000007548e; asc T ;;
2: len 7; hex ea000001960148; asc H;;
3: len 4; hex 80000005; asc ;;
Record lock, heap no 7 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 6; hex 000000000305; asc ;;
1: len 6; hex 00000007548e; asc T ;;
2: len 7; hex ea000001960156; asc V;;
3: len 4; hex 80000005; asc ;;
Record lock, heap no 8 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 6; hex 000000000306; asc ;;
1: len 6; hex 00000007548e; asc T ;;
2: len 7; hex ea000001960164; asc d;;
3: len 4; hex 80000005; asc ;;
Record lock, heap no 9 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 6; hex 000000000307; asc ;;
1: len 6; hex 00000007548e; asc T ;;
2: len 7; hex ea000001960172; asc r;;
3: len 4; hex 80000005; asc ;;
锁算法
自增锁
自增列的维护与数据的新增有关,任何产生新数据的语句都可以称为”Insert like“,大致分3种,分别是simple insert、bulk inserts、mixed-mode inserts
simple insert:插入记录的行数时确定的,比如:insert into values、replace
bulk inserts:插入的记录行数不能马上确定的,比如:insert ... select ... ,replace ... select 和load data
mixed-mode inserts:部分自增列的值给定或者不给定,比如INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (5,'c'), (NULL,'d');和INSERT ... ON DUPLICATE KEY UPDATE
死锁
自增锁死锁常常出现在数据迁移过程中。常见的数据迁移大多以双写来实现,类似一个进程负责从旧表往新表写(insert ... select ...),而应用程序则继续往新表写,此时新表可能会发生死锁。
锁模式
-
innodb_autoinc_lock_mode = 0 (“traditional” lock mode)
任何一种insert-like语句,都会产生一个表级的自增锁,性能差,但是足够安全
-
innodb_autoinc_lock_mode = 1 (“consecutive” lock mode)
这是默认的锁模式,当发生bulk inserts时,会产生一个表级的自增锁直到语句执行结束,注意不是事务结束。对于simple insert,则使用轻量锁,只要获取相应的auto increment就释放锁,不会等待语句结束。当表被加上自增锁后,这种轻量锁不会加锁成功,会等待。
优点是性能较好,缺点还是会产生表级的自增锁,因为要保证自增id的连续性,防止bulk inserts时,被其他insert 语句抢走 auto increment值。
- innodb_autoinc_lock_mode = 2 (“interleaved” lock mode)
当进行bulk insert 时,不会产生表级别的自增锁,因为他是允许其他insert 插入的,新增一条记录,插入分配一个auto increment值,不会预分配。
优点是性能较好,缺点是一次bulk inserts 产生的自增列并不是连续的,同时SBR模式下的主从复制可能会产生数据不一致错误,该错误可以通过将主从复制改为RBR模式。
PS:SBR模式的主从复制:binlog格式以statement的日志格式;RBR模式的主从复制:binlog格式以基于行(Row)的日志格式(推荐)。
优化
如果binlog-format是row模式的,而且不关心一条bulk insert的自增列的值连续且提交顺序与自增列值大小的顺序一致,那么可以设置innodb_autoinc_lock_mode = 2 来提高性能
一条bulk insert 自增列是否连续有时候会影响分页查询,有时候为了解决深分页查询问题,会采用每次分页查询的最大值来进行分页,比如
select * from xx where id>1 limit N
select * from xx where id>1+N limit N
select * from xx where id>1+N+N limit N
当id=101的记录先提交,该记录的值刚好是当前页的最大值,此时id=100数据被提交,那么下次分页查询会从101开始查询,就会造成这次翻页的数据存在缺失的情况。如果分页查询中包含oder by id的查询或者有and create_time < (now() - INTERVAL 5 second),那么可以通过往前翻页来找到,但是归根结底当前分页的数据需要等待100数据被提交后刷新分页来解决。
通用锁
-
锁是在索引上实现的
-
假设有一个key,有5条记录, 1,3,5,7,9. 如果where id<5 , 那么锁住的区间不是(-∞,5),而是(-∞,1],(1,3],(3,5] 多个区间组合而成;如果where id =5,那么锁住的区间是(3,5],(5,9]
-
next-key lock 降级为 record lock的情况:
如果是唯一索引,且查询条件得到的结果集是1条记录(等值,而不是范围),那么会降级为记录锁
典型的案例:where primary_key = 1 (会降级), 而不是 where primary_key < 10 (由于返回的结果集不仅仅一条,那么不会降级)
-
上锁,不仅仅对辅助索引加锁,还需要对主键索引加锁;不仅仅对主键索引加锁,还需要对辅助索引加锁
RR下的Update锁机制
如果
- select * from xx where col <比较运算符> M for update
- M->next-rec: 表示M的下一条记录
- M->pre-rec: 表示M的前一条记录
第一轮总结
- 等值查询M,非唯一索引的加锁逻辑
(M->pre-rec,M],(M,M->next-rec]
- 等值查询M,唯一键的加锁逻辑
[M], next-lock 降级为 record locks
- >= ,非唯一索引的加锁逻辑
(M->pre_rec,M],(M,M->next-rec]....(∞]
-
>= ,唯一索引的加锁逻辑
(M->pre_rec,M],(M,M->next-rec]....(∞] -
<= , 非唯一索引的加锁逻辑
(-∞] ... (M,M->next-rec] -
<= , 唯一索引的加锁逻辑
(-∞] ... (M,M->next-rec] -
>, 非唯一索引的加锁逻辑
(M,M->next-rec] ... (∞] -
>, 唯一索引的加锁逻辑
(M,M->next-rec] ... (∞] -
< , 非唯一索引的加锁逻辑
(-∞] ... (M->pre_rec,M] -
< , 唯一索引的加锁逻辑
(-∞] ... (M->pre_rec,M]
第二轮总结合并
- 等值查询M,非唯一索引的加锁逻辑
(M->pre-rec,M],(M,M->next-rec] - 等值查询M,唯一键的加锁逻辑
[M], next-lock 降级为 record locks
这里大家还记得之前讲过的通用算法吗:
next-key lock 降级为 record lock的情况:
如果是唯一索引,且查询条件得到的结果集是1条记录(等值,而不是范围),那么会降级为记录锁 - >= ,加锁逻辑
(M->pre_rec,M],(M,M->next-rec]....(∞] - >, 加锁逻辑
(M,M->next-rec] ... (∞] - <= , 加锁逻辑
(-∞] ... (M,M->next-rec] - < , 加锁逻辑
(-∞] ... (M->pre_rec,M]
最后的疑问和总结
为什么要对M->next-rec 或者 M->pre-rec ?
因为为了防止幻读。
 文章来源:https://www.toymoban.com/news/detail-493762.html
文章来源:https://www.toymoban.com/news/detail-493762.html
RR下的Insert锁机制
Insert 的流程(没有唯一索引的情况): insert N
- 找到大于N的第一条记录M
- 如果M上面没有gap , next-key locking的话,可以插入 , 否则等待 (对其next-rec加insert intension lock,由于有gap锁,所以等待)
Insert 的流程(有唯一索引的情况): insert N
- 找到大于N的第一条记录M,以及前一条记录P
- 如果M上面没有gap , next-key locking的话,进入第三步骤 , 否则等待(对其next-rec加insert intension lock,由于有gap锁,所以等待)
- 检查p:
判断p是否等于n:
如果不等: 则完成插入(结束)
如果相等:
再判断P 是否有锁,
如果没有锁:
报1062错误(duplicate key) --说明该记录已经存在,报重复值错误
加S-lock --说明该记录被标记为删除, 事务已经提交,还没来得及purge
如果有锁: 则加S-lock --说明该记录被标记为删除,事务还未提交.
- insert intension lock 有什么用呢?锁的兼容矩阵是啥?
- insert intension lock 是一种特殊的Gap lock,记住非常特殊哦
- insert intension lock 和 insert intension lock 是兼容的,其次都是不兼容的
- Gap lock 是为了防止insert, insert intension lock 是为了insert并发更快,两者是有区别的
- 什么情况下会出发insert intension lock ?
当insert的记录M的 next-record 加了Gap lock才会发生,record lock并不会触发
参考资料文章来源地址https://www.toymoban.com/news/detail-493762.html
- http://keithlan.github.io/2017/06/05/innodb_locks_1/
- https://www.hhcycj.com/post/item/441.html
- https://baijiahao.baidu.com/s?id=1744632613955812703&wfr=spider&for=pc
到了这里,关于InnoDB锁初探(一):锁分类和RR不同场景下的锁机制的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!