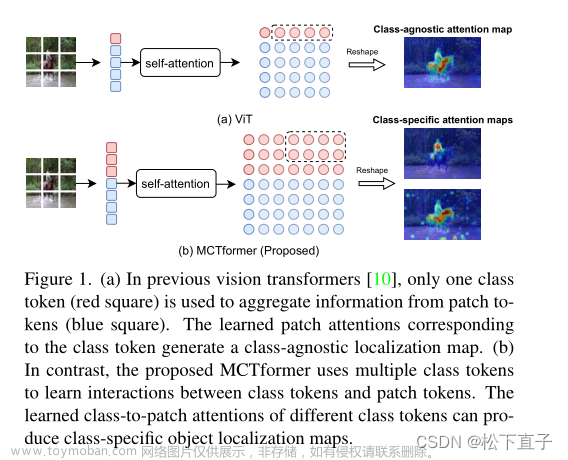
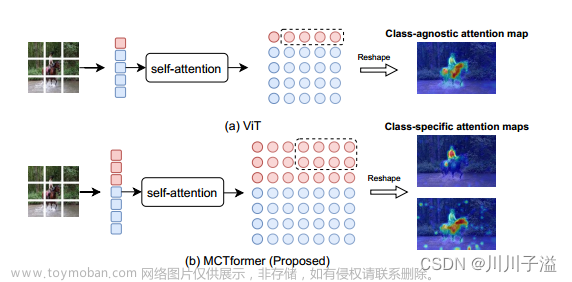
语义分割(Semantic Segmentation)
语义分割是指将图像中的每个像素分类为一个实例,其中每个实例都对应于一个类。
这项技术一直是计算机视觉图像领域的主要任务之一。而在实际应用中,由于能准确地定位到物体所在区域并以像素级的精度排除掉背景的影响,一直是精细化识别、图像理解的可靠方式。
而构建语义分割数据集需要对每张图像上的每个像素进行标注,所需要的人力物力让实际业务项目投入产出比极低。(像素级标注)
针对这个问题,仅需图像级标注即可达到接近的分割效果的弱监督语义分割是近年来语义分割相关方向研究的热点。
弱监督语义分割(Weakly-Supervised Semantic Segmentation)
弱监督语义分割通过利用更简单易得的图像级标注,以训练分类模型的方式获取物体的种子分割区域并优化,从而实现图像的像素级、密集性预测。
在训练深度分割模型时,可以使用不同级别的监督,从像素级的注释(监督学习)、图像级和边界框注释(半监督学习)到完全无注释的对象(无监督学习),其中最后两个级别的注释属于弱监督[9,38]。训练该架构依赖于大量的像素级标记数据,这是耗时和昂贵的,特别是医学图像中的像素级标签。然而,可以以相对快速和廉价的方式获得大量具有图像级标签的图像。近年来出现了许多弱监督语义分割方法,以减轻了像素级标注的巨大负担,并取得了惊人的性能,甚至接近于监督学习
常见的弱监督语义分割可分为以下四类(:
① 图像级标注:仅标注图像中相关物体所属的类别,是最简单的标注;
② 物体点标注:标注各个物体上某一点,以及相应类别;
③ 物体框标注:标注各个物体所在的矩形框,以及相应类别;
④ 物体划线标注:在各个物体上划一条线,以及相应类别。
WSSS的一般过程如下:首先需要生成像素级伪掩模,然后由弱监督算法生成伪掩模。然后通过一个深度卷积神经网络来训练这些图像。最后,对输出结果和伪掩模进行了反向传播,使损失函数最小化,提高了模型的性能。可见:这些技术依赖于较弱的监督形式,如边界框、点或弯弯曲曲的线、图像级标签等。
其中,图像级标签是最简单的弱标签形式,相对容易获得。训练图像只根据它们所属的类来标记,而不是根据它们在图像中的位置。然而,这也使得使用图像级标签来训练分割网络具有挑战性,因此许多研究者开始考虑建立图像级标签和像素级标签之间的相关性。
在这里说明一下图像级标注的处理:
基于图像级标注的弱监督语义分割大多采用多模块串联的形式进行。
首先,利用图像级标注的图像类别标签,通过单标签或多标签分类的方式,训练出一个分类模型。该分类模型通过计算图像中相应类别的类别特征响应图 CAM[3]来当作分割伪标签的种子区域;接着,使用优化算法(如 CRF[4]、AffinityNet[5]等)优化和扩张种子区域,获得最终的像素级的分割伪标签;最后,使用图像数据集和分割伪标签训练传统的分割算法(如 Deeplab 系列[6])。 文章来源:https://www.toymoban.com/news/detail-494025.html
文章来源:https://www.toymoban.com/news/detail-494025.html
有关CAM的介绍,将会在下一篇博文中介绍,感谢阅读!文章来源地址https://www.toymoban.com/news/detail-494025.html
到了这里,关于弱监督语义分割(Weakly-Supervised Semantic Segmentation)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!