前言
使用Python爬取指定电影的影评,
注意:本文仅用于学习交流,禁止用于盈利或侵权行为。
操作系统:windows10 家庭版
开发环境:Pycharm Conmunity 2022.3
解释器版本:Python3.8
第三方库:requests、bs4
第三方库的安装
需要安装 bs4 和 requests 库
你可以参考我的以下文章获取些许帮助:
Python第三方库安装——使用vscode、pycharm安装Python第三方库
Python中requests库使用方法详解
示例代码
#code:utf-8
import requests
from bs4 import BeautifulSoup
import time
# 如果想多爬几页可以将16修改为更大的偶数
for i in range(2,16,2):
url = 'https://movie.douban.com/subject/34841067/comments?start={}0&limit=20&status=P&sort=new_score'.format(i)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15'
}
# 请求
r=requests.get(url, headers=headers)
# 查看状态码
print(r.status_code)
# 获取标题
html = BeautifulSoup(r.text,"html.parser")
title = html.find("h1").text
# 获取用户名、评论、评分
divs = html.find_all("div", class_ = "comment")
s = {"力荐":"❤❤❤❤❤","推荐":"❤❤❤❤❤","还行":"❤❤❤","较差":"❤❤","很差":"❤"}
with open("{}.txt".format(title),"w+",encoding="utf-8") as f:
f.write(str(["用户", "评分", "内容"]))
for div in divs:
print("---------------------------------")
name = div.find("a", class_="").text
print("用户名:",name)
content = div.find("span", class_="short").text
print("用户评论:",content)
score = None
for i in range(1,6):
try:
score = s[div.find("span", class_="allstar{}0 rating".format(i))["title"]]
except:
continue
if score == None:
score = "用户未评分"
print("评分:",score)
print("[+]...{}的评论已爬取".format(name))
f.write("\n")
f.write(str([name,score,content]))
f.close()
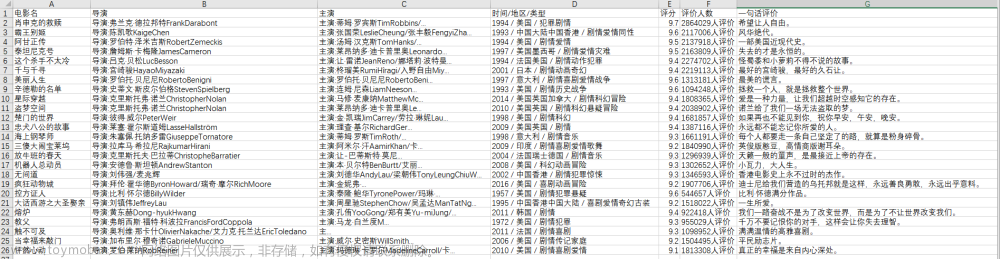
效果演示
以下是控制台的输出结果: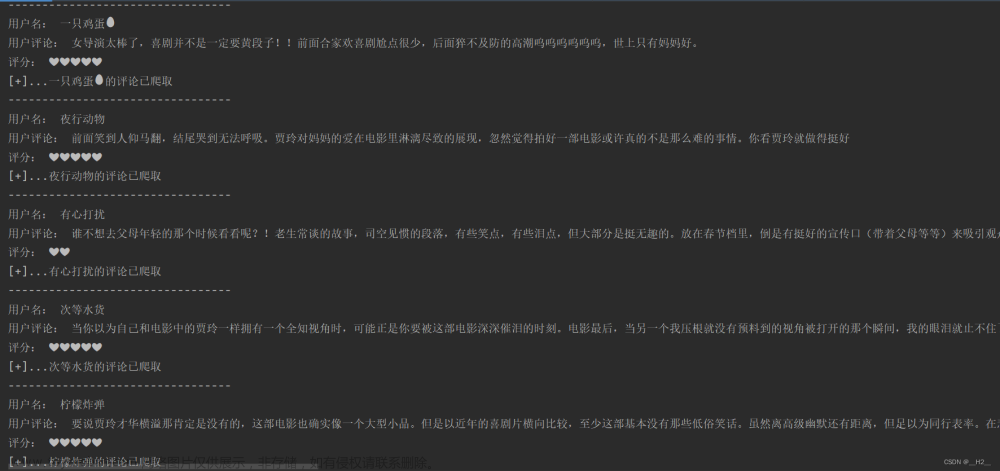
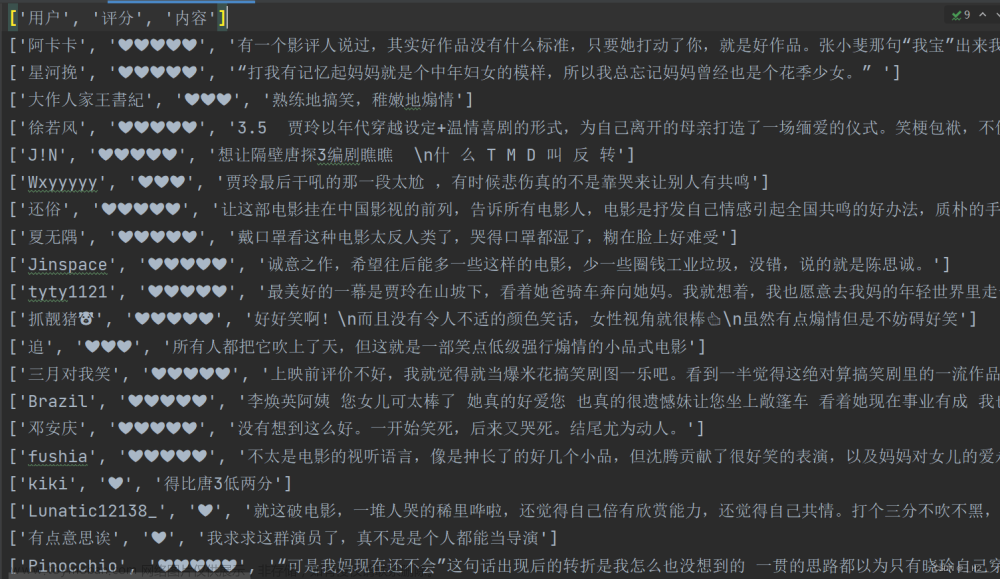
会生成一个以电影名为名字的txt的文件,我们爬取到的数据全部保存在其中,如下:
 文章来源:https://www.toymoban.com/news/detail-494221.html
文章来源:https://www.toymoban.com/news/detail-494221.html
结尾
这个34841067是《你好李焕英》的编码,你可以试着仅仅将这个数字更换成其他电影编码看看会是怎样的结果。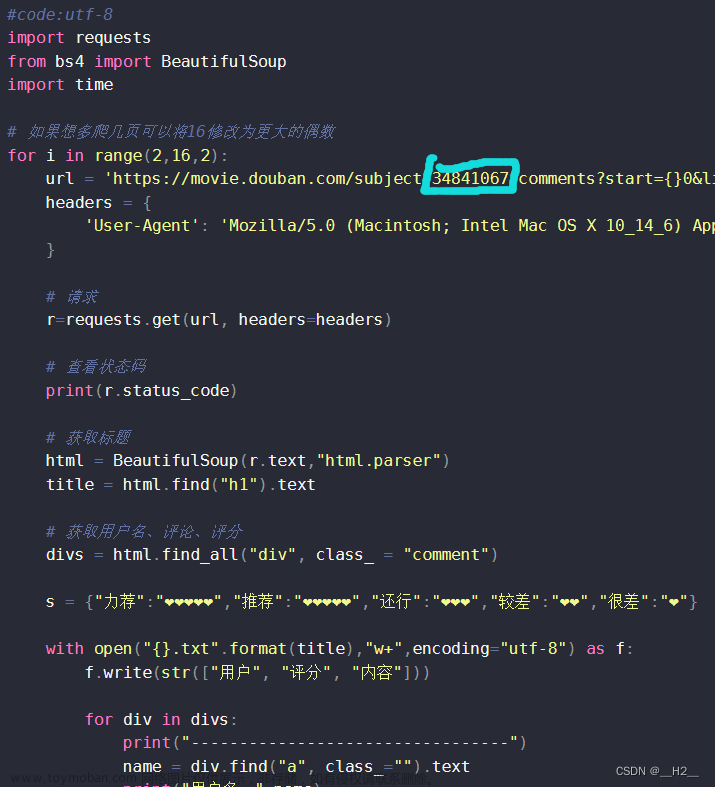 文章来源地址https://www.toymoban.com/news/detail-494221.html
文章来源地址https://www.toymoban.com/news/detail-494221.html
到了这里,关于Python爬虫实战——获取电影影评的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[Python练习]使用Python爬虫爬取豆瓣top250的电影的页面源码](https://imgs.yssmx.com/Uploads/2024/02/797225-1.png)