1、Kafka combines three key capabilities:
- To publish (write) and subscribe to (read) streams of events,
including continuous import/export of your data from other systems. - To store streams of events durably and reliably for as long as you
want. - To process streams of events as they occur or retrospectively.
And all this functionality is provided in a distributed, highly scalable, elastic, fault-tolerant, and secure manner. Kafka can be deployed on bare-metal hardware, virtual machines, and containers, and on-premises as well as in the cloud. You can choose between self-managing your Kafka environments and using fully managed services offered by a variety of vendors.
2、kafka是如何工作的:
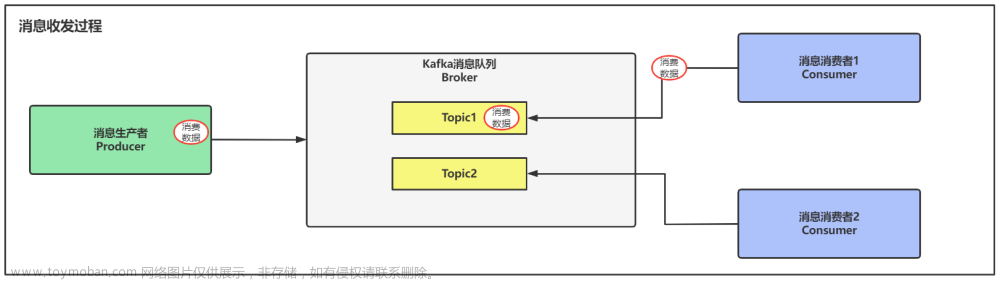
- Kafka 是一个由服务器和客户端组成的分布式系统,它们通过高性能 TCP 网络协议进行通信。
- Services:Kafka 作为一个或多个服务器的集群运行,这些服务器可以跨越多个数据中心或云区域。 其中一些服务器形成存储层,称为代理。其他服务器运行 Kafka Connect 以将数据作为事件流持续导入和导出,以将 Kafka 与您现有的系统(如关系数据库以及其他Kafka 集群)集成。 为了让您实现关键任务用例,Kafka集群具有高度可扩展性和容错性:如果其中任何一个服务器出现故障,其他服务器将接管它们的工作,以确保持续运行而不会丢失任何数据。
- Clients:它们允许您编写分布式应用程序和微服务,以并行、大规模和容错方式读取、写入和处理事件流,即使在网络问题或机器故障的情况下也是如此。 Kafka 附带了一些这样的客户端,这些客户端由 Kafka 社区提供的数十个客户端进行了扩充:客户端可用于 Java 和 Scala,包括更高级别的 Kafka Streams 库,用于 Go、Python、C/C++ 和许多其他编程 语言以及 REST API。
- 生产者是那些向 Kafka 发布(写入)事件的客户端应用程序,而消费者是订阅(读取和处理)这些事件的那些客户端应用程序。 在 Kafka 中,生产者和消费者完全解耦并且彼此不可知,这是实现 Kafka 众所周知的高可扩展性的关键设计元素。 例如,生产者永远不需要等待消费者。 Kafka 提供了各种保证,例如一次性处理事件的能力。
- events存储在topics中,topics类似文件夹,events类似于文件夹中的文件;events被消费之后不会被删除,可以自己设置events被保留多久。
- topics是分区的,这意味着topic分布在位于不同 Kafka broker上的多个“桶”中。 数据的这种分布式放置对于可伸缩性非常重要,因为它允许客户端应用程序同时从多个代理读取和写入数据。 当一个新事件发布到一个topic时,它实际上是加到topic的分区之一。 具有相同事件键(例如,客户或车辆 ID)的事件被写入同一个分区,并且 Kafka 保证给定topic分区的任何消费者将始终以与写入事件完全相同的顺序读取该分区的事件。

every topic can be replicated, even across geo-regions or datacenters
3、Kafka APIS:
除了用于管理和管理任务的命令行工具外,Kafka 还具有五个用于 Java 和 Scala 的核心 API:
(1)管理和检查topics、brokers和其他 Kafka 对象的 Admin API。
(2)The Producer API to publish (write) a stream of events to one or more Kafka topics.
(3)The Consumer API to subscribe to (read) one or more topics and to process the stream of events produced to them.
(4)用于实现流处理应用程序和微服务的 Kafka Streams API。 它提供了更高级别的函数来处理事件流,包括转换、聚合和连接等有状态操作、窗口化、基于事件时间的处理等等。 从一个或多个topics读取输入以生成一个或多个topics的输出,有效地将输入流转换为输出流。
(5)Kafka Connect API 用于构建和运行可重用的数据导入/导出连接器,这些连接器从外部系统和应用程序消费(读取)或产生(写入)事件流,以便它们可以与 Kafka 集成。 例如,与 PostgreSQL 等关系数据库的连接器可能会捕获对一组表的每次更改。 但是,在实践中,您通常不需要实现自己的连接器,因为 Kafka 社区已经提供了数百个即用型连接器。文章来源:https://www.toymoban.com/news/detail-494409.html
4、kafka集群
集群模式文章来源地址https://www.toymoban.com/news/detail-494409.html
到了这里,关于【学习笔记】Java——消息队列kafka的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!