三 Python数据科学工具
1.Numpy
numpy是Python中一个非常重要的科学计算库,其最基础的功能就是N维数组对象——ndarray。
1.1 数组的创建
1)np.array()
用
np.array()函数可以将Python的序列对象(如列表、元组)转换为ndarray数组。
import numpy as np
a = [1, 2, 3, 4]
arr = np.array(a)
print(arr)
2)arange、linspace、logspace
-
np.arange(start, stop, step):创建一个一维数组,其中的值是从start到stop(不包括stop)的等差数列,步长为step。 -
np.linspace(start, stop, num):创建一个一维数组,其中的值是从start到stop(包括stop)的等间距数列,数列中包含num个值。 -
np.logspace(start, stop, num, base):创建一个一维数组,其中的值是从base的start次方到base的stop次方(包括stop),数列中包含num个值。
import numpy as np
# 创建一个等差数列
arr1 = np.arange(0, 10, 2)
print(arr1) # [0 2 4 6 8]
# 创建一个等间距数列
arr2 = np.linspace(0, 1, 5)
print(arr2) # [0. 0.25 0.5 0.75 1. ]
# 创建一个对数间距数列
arr3 = np.logspace(0, 2, 3, base=10)
print(arr3) # [ 1. 10. 100.]
3)创建特定数组
-
np.zeros(shape):创建一个所有元素都为0的数组,其中shape是数组的形状,可以是一个整数、元组或列表。 -
np.ones(shape):创建一个所有元素都为1的数组,形状同上。 -
np.identity(n):创建一个n×n的单位矩阵(即对角线上的元素为1,其余元素为0的矩阵)。 -
np.empty(shape):创建一个指定形状的空数组,其中的元素值可能是未初始化的随机数据。 -
np.diag(v, k=0):创建一个以v为对角线元素的对角矩阵,其中k表示对角线的偏移量,可以为正(表示在主对角线之上)或者负(表示在主对角线之下)。
import numpy as np
# 创建一个所有元素都为0的3×3数组
arr1 = np.zeros((3, 3))
print(arr1)
'''
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
'''
# 创建一个所有元素都为1的2×2数组
arr2 = np.ones([2, 2])
print(arr2)
'''
[[1. 1.]
[1. 1.]]
'''
# 创建一个4×4的单位矩阵
arr3 = np.identity(4)
print(arr3)
'''
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]
'''
# 创建一个2×3的空数组
arr4 = np.empty((2, 3))
print(arr4)
'''
[[1. 1. 1.]
[1. 1. 1.]]
'''
# 创建一个以[1, 2, 3]为对角线元素的对角矩阵
arr5 = np.diag([1, 2, 3])
print(arr5)
'''
[[1 0 0]
[0 2 0]
[0 0 3]]
'''
1.2 数组元素的访问
-
下标或切片:
例如,对于一维数组arr,可以使用arr[0]来访问第一个元素,使用arr[1:3]来访问第2到第4个元素。
-
整数序列:
可以使用整数序列来访问任意元素,例如arr[[0, 2, 3]]将返回第1、3、4个元素组成的数组。
-
布尔数组:
可以使用一个布尔数组进行索引,数组中为True的位置对应的元素会被提取出来,例如arr[arr > 5]将返回所有大于5的元素
import numpy as np
# 创建一个一维数组
arr1 = np.array([1, 2, 3, 4, 5])
print(arr1)
'''
[1 2 3 4 5]
'''
# 创建一个二维数组
arr2 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(arr2)
'''
[[1 2 3]
[4 5 6]
[7 8 9]]
'''
# 使用下标或切片访问数组元素
print(arr1[0]) # 输出第一个元素
print(arr2[1, 2]) # 输出第二行第三列的元素
'''
1
6
'''
# 使用整数序列访问数组元素
print(arr1[[0, 2, 4]]) # 输出第1、3、5个元素
print(arr2[[0, 2], [1, 2]]) # 输出(0,1)和(2,2)位置的元素
'''
[1 3 5]
[2 9]
'''
# 使用布尔数组访问数组元素
print(arr1[arr1 > 3]) # 输出大于3的元素
print(arr2[arr2 % 2 == 0]) # 输出所有偶数元素
'''
[12 15 18]
[2. 5. 8.]
'''
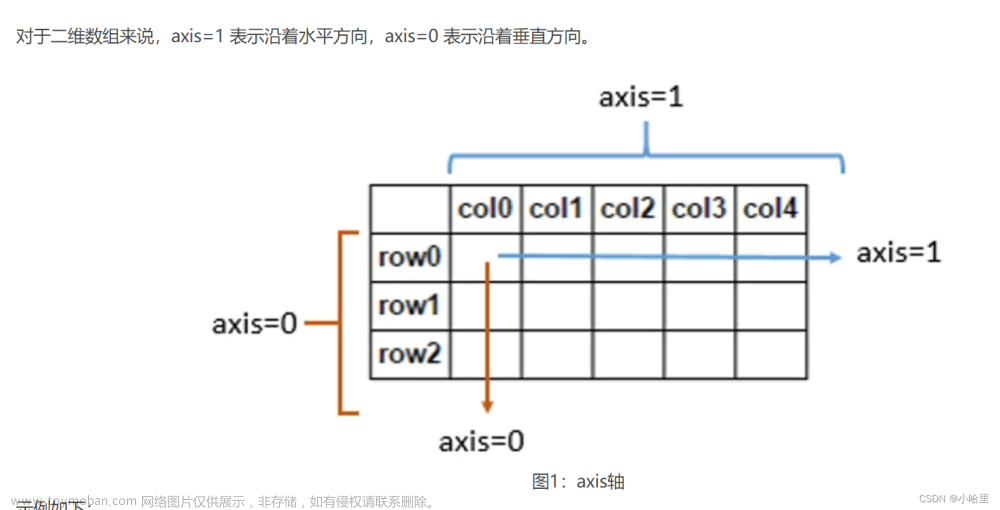
1.3 多维数组的axis参数
在多维数组中,我们可以通过指定axis参数来沿着某个轴进行操作。
axis参数可以取0、1、2等值,表示对应的维度。
例如,
对于一个二维数组,
axis=0表示沿着行的方向进行操作,
而axis=1则表示沿着列的方向进行操作。在一些函数中,axis也可以取负值,表示从后往前数的维度。
在实际操作中,我们经常需要对多维数组进行求和、平均、最大/小值等操作,这时就需要考虑axis参数的取值。
import numpy as np
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 沿着行的方向对数组求和
print(np.sum(arr, axis=0)) # 输出[12 15 18]
# 沿着列的方向对数组求和
print(np.sum(arr, axis=1)) # 输出[ 6 15 24]
# 沿着行的方向对数组求平均值
print(np.mean(arr, axis=0)) # 输出[4. 5. 6.]
# 沿着列的方向对数组求平均值
print(np.mean(arr, axis=1)) # 输出[2. 5. 8.]
# 沿着第三个维度求和,但该数组只有两个维度,所以会报错
try:
print(np.sum(arr, axis=2))
except Exception as e:
print(str(e)) # 输出"axis 2 is out of bounds for array of dimension 2"
# 沿着负数的维度求和,即从后往前数的第二个维度
print(np.sum(arr, axis=-2)) # 输出[12 15 18]
1.4 ufunc运算
import numpy as np
# 创建两个一维数组
x = np.array([1, 2, 3])
y = np.array([4, 5, 6])
# 加法
print(x + y) # 输出[5 7 9]
# 减法
print(x - y) # 输出[-3 -3 -3]
# 乘法
print(x * y) # 输出[ 4 10 18]
# 除法
print(x / y) # 输出[0.25 0.4 0.5 ]
# 幂运算
print(x ** 2) # 输出[1 4 9]
# 正弦函数
print(np.sin(x)) # 输出[0.84147098 0.90929743 0.14112001]
# 余弦函数
print(np.cos(y)) # 输出[-0.65364362 0.28366219 0.96017029]
# 平方根函数
print(np.sqrt(x)) # 输出[1. 1.41421356 1.73205081]
# 指数函数
print(np.exp(y)) # 输出[ 54.59815003 148.4131591 403.42879349]
# 自然对数函数
print(np.log(y)) # 输出[1.38629436 1.60943791 1.79175947]
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 沿着行的方向对数组求和
print(np.sum(arr, axis=0)) # 输出[12 15 18]
# 沿着列的方向对数组求平均值
print(np.mean(arr, axis=1)) # 输出[2. 5. 8.]
1.5 向量与矩阵运算
向量表示为一维数组,矩阵表示为二维数组。
1)向量内积
向量内积是两个向量对应位置元素的乘积之和,可以用来计算向量之间的相似度。
当两个向量之间的夹角越小时,它们的内积也就越大,说明它们之间的相似度越高。
import numpy as np
x1 = np.array([1, 2, 3])
x2 = np.array([4, 5, 6])
print(np.dot(x1, x2))
# 输出32(1*4 + 2*5 + 3*6)
2)矩阵基本运算
import numpy as np
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
print(a + b) # 对应位置相加
# 输出 [[ 6 8]
# [10 12]]
print(a - b) # 对应位置相减
# 输出 [[-4 -4]
# [-4 -4]]
print(a * b) # 对应位置相乘
# 输出 [[ 5 12]
# [21 32]]
print(b / a) # 对应位置相除
# 输出 [[5. 3. ]
# [2.33333333 2. ]]
print(b // a) # 对应位置整除
# 输出 [[5 3]
# [2 2]]
print(b % a) # 对应位置取模
# 输出 [[0 0]
# [1 0]]
print(a ** 2) # 幂运算
# 输出 [[ 1 4]
# [ 9 16]]
print(a @ b) # 矩阵乘积
# 输出 [[19 22]
# [43 50]]
3)矩阵转置
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a.T)
# 输出 [[1 4]
# [2 5]
# [3 6]]
4)数据排序
可以使用
sort()函数对数组进行排序。默认情况下,该函数按升序排序,如果需要降序排序则需要传入参数kind='quicksort', order=大于时为-1, 小于时为1。
import numpy as np
a = np.array([3, 1, 2])
print(np.sort(a)) # 升序排序,输出[1 2 3]
print(np.sort(a)[::-1]) # 降序排序,输出[3 2 1]
sort()函数还支持按照指定轴进行排序。
import numpy as np
a = np.array([[3, 2], [1, 4]])
print(np.sort(a, axis=0)) # 对列排序,输出[[1 2] [3 4]]
print(np.sort(a, axis=1)) # 对行排序,输出[[2 3] [1 4]]
2.Pandas
2.1 Series
Series是一维的序列,可以看作由一组数据及其对应的索引组成。
- 创建
import pandas as pd
data = pd.Series([0.25, 0.5, 0.75, 1.0])
print(data)
'''
0 0.25
1 0.50
2 0.75
3 1.00
dtype: float64
'''
-
访问元素
对于Series,可以使用位置索引或者标签索引来访问单个元素或者多个元素。
import pandas as pd data = pd.Series([0.25, 0.5, 0.75, 1.0]) print(data[0]) # 输出第一个元素 ''' 0.25 ''' print(data[:2]) # 输出前两个元素 ''' 0 0.25 1 0.50 dtype: float64 ''' print(data[[1,3]]) # 输出第二个和第四个元素 ''' 1 0.50 3 1.00 dtype: float64 '''
2.2 DataFrame
DataFrame是二维的表结构,可以看作是由多个Series组成。
每一列的数据类型可以不同,但是同一列中的数据类型必须相同。
- 定义
import pandas as pd
data = {'name': ['Alice', 'Bob', 'Charlie', 'David'],
'age': [25, 30, 35, 40],
'gender': ['F', 'M', 'M', 'F']}
df = pd.DataFrame(data)
print(df)
'''
name age gender
0 Alice 25 F
1 Bob 30 M
2 Charlie 35 M
3 David 40 F
'''
-
访问元素
对于DataFrame,可以使用列标签和行标签来访问单个元素或者多个元素。
import pandas as pd data = {'name': ['Alice', 'Bob', 'Charlie', 'David'], 'age': [25, 30, 35, 40], 'gender': ['F', 'M', 'M', 'F']} df = pd.DataFrame(data) print(df['name']) # 输出name这一列的所有元素 ''' 0 Alice 1 Bob 2 Charlie 3 David Name: name, dtype: object ''' print(df.loc[1]) # 输出第二行的所有元素 ''' name Bob age 30 gender M Name: 1, dtype: object ''' print(df.iloc[0:2, 1:]) # 输出前两行,从第二列开始的所有元素 ''' age gender 0 25 F 1 30 M '''
2.3 布尔类型数组索引
布尔型数组索引是指通过一个布尔值的数组来进行切片。
这个数组的长度必须和被索引的Series或DataFrame的长度相同,其中每个元素代表着这个位置是否被选中。
True:选中
False:未选中
-
对Series
import pandas as pd data = pd.Series([0.25, 0.5, 0.75, 1.0]) bool_arr = [True, False, True, False] print(data[bool_arr]) # 输出第一和第三个元素 ''' 0 0.25 2 0.75 dtype: float64 ''' -
对DataFrame文章来源:https://www.toymoban.com/news/detail-494838.html
import pandas as pd data = {'name': ['Alice', 'Bob', 'Charlie', 'David'], 'age': [25, 30, 35, 40], 'gender': ['F', 'M', 'M', 'F']} df = pd.DataFrame(data) bool_arr = [False, True, False, True] print(df[bool_arr]) # 输出第二和第四行的所有元素 ''' name age gender 1 Bob 30 M 3 David 40 F '''
[bool_arr]) # 输出第一和第三个元素
‘’’
0 0.25
2 0.75
dtype: float64
‘’’文章来源地址https://www.toymoban.com/news/detail-494838.html
* 对DataFrame
```python
import pandas as pd
data = {'name': ['Alice', 'Bob', 'Charlie', 'David'],
'age': [25, 30, 35, 40],
'gender': ['F', 'M', 'M', 'F']}
df = pd.DataFrame(data)
bool_arr = [False, True, False, True]
print(df[bool_arr]) # 输出第二和第四行的所有元素
'''
name age gender
1 Bob 30 M
3 David 40 F
'''
到了这里,关于【Python】数据科学工具(Numpy Pandas np.array() 创建访问数组 向量与矩阵 Series DataFrame)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!