- 认识云存储
1.1存储发展历史
1.1.1云存储出现
云存储技术,孕育在云计算技术的发展历程之中。基于云计算技术的发展,以及宽带业务的大幅度提速,为云存储的普及和发展提供了良好的技术支持。2004年,互联网进入WEB2.0时代后,人们更加注重资源的分析和信息的交互,这种对大容量、方便快捷、随存随取的存储需求,无疑将大大的推动云存储服务的发展和普及。2006年3月,亚马逊(Amazon)推出的亚马逊简易储存服务(Amazon Simple Storage Service,即S3)云存储产品,也正式开启了云存储服务的发展。
至此,云存储产品正式面世,并提供存储服务。而云存储的概念也被进一步的推广和认可,云存储是在云计算概念上延伸和发展出来的一个新的概念,是一种新兴的网络存储技术。和云计算类似,云存储是指通过集群应用、网络技术或分布式文件系统等功能,将网络中大量各种不同类型的、廉价的存储设备通过应用软件集合起来协同工作,共同对外提供数据存储和业务访问功能的一个系统。
通俗上讲,云存储也就是一个在“云”上的一个巨大容量的存储池。通过互联网技术,可供公众随存随取的一种新兴网络存储方案。使用者可以在任何时间、任何地方,透过任何可联网的装置连接到“云”上方便地存取数据。
1.1.2云存储技术的发展
云存储技术的发展除了上面讲到地相关技术的推动,公众对大数据存储需求的推动不可忽视。同时数据安全问题,也将影响着云存储未来的发展方向。
1)数据爆发的推动
随着计算机技术的发展以及互联网技术尤其是移动互联网技术的普及,每个人都成为了海量数据的生产者,全球数据量呈现爆炸式的增长,仅在2015年就达到8.6ZB(1ZB等于1万亿GB)左右,据IDC预计,到2020年全球数据量将增加到40ZB。爆炸式的数据生产,使得人们对大容量、易扩展、低价格的存储设备产生了强烈的需求。
庞大的存储需求,也刺激着云存储服务的市场发展。据IDC的报告显示,在未来四年内,全球云服务市场规模将增长到442亿美元,其中云存储的市场比例将从目前的9%增长到14%,其规模将接近62亿美元,存储市场是增长最快的云计算服务,这也意味着云存储的市场潜力仍是巨大的。国内外互联网巨头,纷纷推出相应的云存储平台,如亚马逊(Amazon)的S3,谷歌的Google Drive,微软(Microsoft)的Windows Azure,百度云盘,360云盘等。
2)数据安全的制约
云存储服务由于其成本低廉、方便快捷等优势,短短几年就得到了迅猛地发展,使用云存储存放数据(文档、图片、音频、视频等)已十分普遍。但是,伴随着云存储数据安全问题频频发生,如数据泄露、数据丢失、账号或服务流量劫持、系统宕机等,使公众对云存储的数据安全问题日益关注。数据安全问题,既会严重制约云存储的发展,又将促进云存储提供商不断对数据存储安全的研究与改善。
3)发展趋势
随着大数据存储需求的刺激,数据安全技术的完善以及宽带网络的发展,云存储提供商开始积极将各类搜索、应用技术和云存储相结合。云存储技术将在数据访问、数据安全、便携性及数据访问方面继续完善和改进。
云存储不仅仅只是简单的大容量存储,而将是云计算时代的一场存储革命。随着云存储的安全性、可靠性、实用性等存储技术的不断成熟与完善,云存储将会给人们的生活方式,企业的运行模式带来更多的机遇与挑战。
1.2.云存储的概念
云存储是在云计算(cloud computing)概念上延伸和发展出来的一个新的概念,是指通过集群应用、网格技术或分布式文件系统等功能,将网络中大量各种不同类型的存储设备通过应用软件集合起来协同工作,共同对外提供数据存储和业务访问功能的一个系统。当云计算系统运算和处理的核心是大量数据的存储和管理时,云计算系统中就需要配置大量的存储设备,那么云计算系统就转变成为一个云存储系统,所以云存储是一个以数据存储和管理为核心的云计算系统。
就如同云状的广域网和互联网一样,云存储对使用者来讲,不是指某一个具体的设备,而是指一个由许许多多个存储设备和服务器所构成的集合体。使用者使用云存储,并不是使用某一个存储设备,而是使用整个云存储系统带来的一种数据访问服务。所以严格来讲,云存储不是存储,而是一种服务。
1.3 云存储分类与特点
1.3.1 云存储分类
1)公共云存储公有云服务商提供的存储服务,它们可以低成本提供大量的文件存储。供应商可以保持每个客户的存储、应用都是独立的,私有的。公共云存储可以划出一部分出来用作私有云存储。
2)内部云存储这种云存储和私有云存储比较类似,唯一的不同点是它仍然位于企业防火墙内部。通过私有云存储,一个公司可以拥有或控制基础架构,以及应用的部署。私有云存储可以部署在企业数据中心或相同地点的设施上。私有云可以由公司自己的IT部门管理,也可以由服务供应商管理。
3)混合云存储这种云存储把公共云和私有云/内部云结合在一起。主要用于按客户要求的访问,特别是需要临时配置容量的时候。从公共云上划出一部分容量配置一种私有或内部云,可以帮助公司面对迅速增长的负载波动或高峰。尽管如此,混合云存储带来了跨公共云和私有云分配应用的复杂性。
1.3.2 云存储的特点
云存储是云计算的延伸和发展,因此继承了云计算的所有特征。虽然私有云存储与公有云存储在部署上和服务模式上有所不同,但仍具有如下共同特点。
(1)可弹性扩展:底层采用虚拟化和分布式技术,单个存储节点的加入和退出不会影响整个服务,其存储量可随着需要进行增加,对于海量数据具有非常好的处理能力。
(2)性价比高:无论是私有云存储还是公有云存储,都可以采用廉价设备构建系统,节约采购存储设备的成本,通过自动化部署及管理可以缩短建设周期,减少运维成本。
(3)同质化:云存储中使用的软件和硬件都趋于同质化,这样可以实现更好的自动化管理。
(4)虚拟化:云存储可以让用户在任意地点使用各种终端获取应用服务,用户无须了解应用所运行的具体位置。
(5)可靠性:从硬件层面到软件层面配备了容灾机制,在增加云存储系统整体高可用性的同时,还能够提高系统整体的运行效率。
(6)安全性:构建服务的安全体系是云存储建设所必备的需求,云存储可靠的数据加密存储方式实现了用户数据的私密性。
- 单节点存储介质
2.1存储介质
存储介质是指存储数据的载体。比如软盘、光盘、DVD、硬盘、闪存、U盘、CF卡、SD卡、MMC卡、SM卡、记忆棒(Memory Stick)、xD卡等。流行的存储介质是基于闪存(Nand flash)的,比如U盘、CF卡、SD卡、SDHC卡、MMC卡、SM卡、记忆棒、xD卡等。
2.1.1、软盘
软盘(FloppyDisk)是个人计算机(PC)中最早使用的可移介质。软盘的读写是通过软盘驱动器完成的。软盘驱动器设计能接收可移动式软盘,目前常用的就是容量为1.44MB的3.5英寸软盘,它曾经盛极一时。之后由于U盘的出现,软盘的应用逐渐衰落直至淘汰。
2.1.2、光盘
光盘是利用激光原理进行读、写的设备,是迅速发展的一种辅助存储器,可以存放各种文字、声音、图形、图像和动画等多媒体数字信息。
2.1.3.DVD
(DigitalVideoDisc)的缩写,又被称为高密度数字视频光盘。它是比VCD更新一代的产品。DVD分别采用MPEG-2技术和AC-3标准对视频和音频信号进行压缩编码。它可以记录135分钟的图像画面。与VCD不同的是它的图像清晰度可达720线。
2.1.4.闪存
快闪存储器(英语fiashmemory).是一种电子式可清除程序化只读存储器的形式,允许在操作中被多次擦或写的存储器,这种科技主要用于一般性数据存储,以及在计算机与其他数字产品间交换传输数据,如储存卡与U盘,闪存是一种特殊的,以宏块抹写的EPROM。早期的闪存进行一次抹除,就会清除掉整颗芯片上的数据。
2.1.5、U盘
U盘是USB(universalserialbus)盘的简称,据谐音也称“优盘”。U盘是闪存的一种,故有时也称作闪盘。U盘与硬盘的最大不同是,它不需物理驱动器,即插即用,且其存储容量远超过软盘,极便于携带。
2.2 硬盘接口
2.2.1 硬盘接口种类
- IDE接口,IDE代表着硬盘的一种类型,IDE接口硬盘多用于家用产品中,也部分应用于服务器。
- SATA接口,使用SATA接口的硬盘又叫串口硬盘,是现在和未来的PC机硬盘主流趋势。
- SCSI接口,SCSI接口具有应用范围广,多任务,带宽大CPU占用率低以及热插拔等优点。
- 光纤通道接口,光纤通道是为向服务器这样的多硬盘系统环境而设计的,有热插拔性,高速带宽,远程连接,连接设备数量大等特点。
- SAS接口,SAS串行连接SCSI,是新一代的SCSI技术,与SATA硬盘相同,都是采用串行技术以获得更高的传输速度。(注:SAS的接口技术可以向下兼容SATA,但反过来SATA系统并不兼容SAS。)
- iSCSI接口:将SCSI命令和数据块封装在TCP中,是一种在TCP/IP上进行数据块传输的标准设备的主机接口一般默认都是IP接口,可以直接与以太网络交换机和iSCSI交换机连接,形成一个存储区域网络。根据主机端HBA卡、网络交换机的不同,iSCSI设备与主机之间有三种连接方式。
- NL-SAS是采用了SAS的磁盘接口和SATA的盘体的综合体。SAS是Serial Attach SCSI(串行SCSI),SATA是串行ATA。
2.3 RAID技术
1).raid概念
磁盘阵列(Redundant Arrays of Independent Disks,RAID),有"独立磁盘构成的具有冗余能力的阵列"之意。
磁盘阵列是由很多价格较便宜的磁盘,组合成一个容量巨大的磁盘组,利用个别磁盘提供数据所产生加成效果提升整个磁盘系统效能。利用这项技术,将数据切割成许多区段,分别存放在各个硬盘上。
磁盘阵列还能利用同位检查(Parity Check)的观念,在数组中任意一个硬盘故障时,仍可读出数据,在数据重构时,将数据经计算后重新置入新硬盘中
2)RAID级别
1、RAID 0
RAID 0是最早出现的RAID模式,即Data Stripping数据分条技术。RAID 0是组建磁盘阵列中最简单的一种形式,只需要2块以上的硬盘即可,成本低,可以提高整个磁盘的性能和吞吐量。RAID 0没有提供冗余或错误修复能力,但实现成本是最低的。
RAID 0最简单的实现方式就是把N块同样的硬盘用硬件的形式通过智能磁盘控制器或用操作系统中的磁盘驱动程序以软件的方式串联在一起创建一个大的卷集。在使用中电脑数据依次写入到各块硬盘中,它的最大优点就是可以整倍的提高硬盘的容量。如使用了三块80GB的硬盘组建成RAID 0模式,那么磁盘容量就会是240GB。其速度方面,各单独一块硬盘的速度完全相同。最大的缺点在于任何一块硬盘出现故障,整个系统将会受到破坏,可靠性仅为单独一块硬盘的1/N。
为了解决这一问题,便出现了RAID 0的另一种模式。即在N块硬盘上选择合理的带区来创建带区集。其原理就是将原先顺序写入的数据被分散到所有的四块硬盘中同时进行读写。四块硬盘的并行操作使同一时间内磁盘读写的速度提升了4倍。
在创建带区集时,合理的选择带区的大小非常重要。如果带区过大,可能一块磁盘上的带区空间就可以满足大部分的I/O操作,使数据的读写仍然只局限在少数的一、两块硬盘上,不能充分的发挥出并行操作的优势。另一方面,如果带区过小,任何I/O指令都可能引发大量的读写操作,占用过多的控制器总线带宽。因此,在创建带区集时,我们应当根据实际应用的需要,慎重的选择带区的大小。
带区集虽然可以把数据均匀的分配到所有的磁盘上进行读写。但如果我们把所有的硬盘都连接到一个控制器上的话,可能会带来潜在的危害。这是因为当我们频繁进行读写操作时,很容易使控制器或总线的负荷 超载。为了避免出现上述问题,建议用户可以使用多个磁盘控制器。最好解决方法还是为每一块硬盘都配备一个专门的磁盘控制器。
虽然RAID 0可以提供更多的空间和更好的性能,但是整个系统是非常不可靠的,如果出现故障,无法进行任何补救。所以,RAID 0一般只是在那些对数据安全性要求不高的情况下才被人们使用。
2、RAID 1
RAID 1称为磁盘镜像,原理是把一个磁盘的数据镜像到另一个磁盘上,也就是说数据在写入一块磁盘的同时,会在另一块闲置的磁盘上生成镜像文件,在不影响性能情况下最大限度的保证系统的可靠性和可修复性上,只要系统中任何一对镜像盘中至少有一块磁盘可以使用,甚至可以在一半数量的硬盘出现问题时系统都可以正常运行,当一块硬盘失效时,系统会忽略该硬盘,转而使用剩余的镜像盘读写数据,具备很好的磁盘冗余能力。虽然这样对数据来讲绝对安全,但是成本也会明显增加,磁盘利用率为50%,以四块80GB容量的硬盘来讲,可利用的磁盘空间仅为160GB。另外,出现硬盘故障的RAID系统不再可靠,应当及时的更换损坏的硬盘,否则剩余的镜像盘也出现问题,那么整个系统就会崩溃。更换新盘后原有数据会需要很长时间同步镜像,外界对数据的访问不会受到影响,只是这时整个系统的性能有所下降。因此,RAID 1多用在保存关键性的重要数据的场合。
RAID 1主要是通过二次读写实现磁盘镜像,所以磁盘控制器的负载也相当大,尤其是在需要频繁写入数据的环境中。为了避免出现性能瓶颈,使用多个磁盘控制器就显得很有必要。
3、RAID0+1
从RAID0+1名称上我们便可以看出是RAID0与RAID1的结合体。在我们单独使用RAID 1也会出现类似单独使用RAID 0那样的问题,即在同一时间内只能向一块磁盘写入数据,不能充分利用所有的资源。为了解决这一问题,我们可以在磁盘镜像中建立带区集。因为这种配置方式综合了带区集和镜像的优势,所以被称为RAID 0+1。把RAID0和RAID1技术结合起来,数据除分布在多个盘上外,每个盘都有其物理镜像盘,提供全冗余能力,允许一个以下磁盘故障,而不影响数据可用性,并具有快速读/写能力。RAID0+1要在磁盘镜像中建立带区集至少4个硬盘。
4、RAID: LSI MegaRAID、Nytro和Syncro
MegaRAID、Nytro和Syncro都是LSI 针对RAID而推出的解决方案,并且一直在创造更新。
LSI MegaRAID的主要定位是保护数据,通过高性能、高可靠的RAID控制器功能,为数据提供高级别的保护。LSI MegaRAID在业界有口皆碑。
LSI Nytro的主要定位是数据加速,它充分利用当今备受追捧的闪存技术,极大地提高数据I/O速度。LSI Nytro包括三个系列:LSI Nytro WarpDrive加速卡、LSI Nytro XD 应用加速存储解决方案和LSI Nytro MegaRAID 应用加速卡。Nytro MegaRAID主要用于DAS环境,Nytro WarpDrive加速卡主要用于SAN和NAS环境,Nytro XD解决方案由Nytro WarpDrive加速卡和Nytro XD 智能高速缓存软件两部分构成。
LSI Syncro的定位主要用于数据共享,提高系统的可用性、可扩展性,降低成本。
LSI通过MegaRAID提供基本的可靠性保障;通过Nytro实现加速;通过Syncro突破容量瓶颈,让价格低廉的存储解决方案可以大规模扩展,并且进一步提高可靠性。
5、RAID2:带海明码校验
从概念上讲,RAID 2 同RAID 3类似, 两者都是将数据条块化分布于不同的硬盘上, 条块单位为位或字节。然而RAID 2 使用一定的编码技术来提供错误检查及恢复。这种编码技术需要多个磁盘存放检查及恢复信息,使得RAID 2技术实施更复杂。因此,在商业环境中很少使用。下图左边的各个磁盘上是数据的各个位,由一个数据不同的位运算得到的海明校验码可以保存另一组磁盘上。由于海明码的特点,它可以在数据发生错误的情况下将错误校正,以保证输出的正确。它的数据传送速率相当高,如果希望达到比较理想的速度,那最好提高保存校验码ECC码的硬盘,对于控制器的设计来说,它又比RAID3,4或5要简单。没有免费的午餐,这里也一样,要利用海明码,必须要付出数据冗余的代价。输出数据的速率与驱动器组中速度最慢的相等。
6 、RAID3:带奇偶校验码的并行传送
这种校验码与RAID2不同,只能查错不能纠错。它访问数据时一次处理一个带区,这样可以提高读取和写入速度。校验码在写入数据时产生并保存在另一个磁盘上。需要实现时用户必须要有三个以上的驱动器,写入速率与读出速率都很高,因为校验位比较少,因此计算时间相对而言比较少。用软件实现RAID控制将是十分困难的,控制器的实现也不是很容易。它主要用于图形(包括动画)等要求吞吐率比较高的场合。不同于RAID 2,RAID 3使用单块磁盘存放奇偶校验信息。如果一块磁盘失效,奇偶盘及其他数据盘可以重新产生数据。 如果奇偶盘失效,则不影响数据使用。RAID 3对于大量的连续数据可提供很好的传输率,但对于随机数据,奇偶盘会成为写操作的瓶颈。
7、RAID4:带奇偶校验码的独立磁盘结构
RAID4和RAID3很象,不同的是,它对数据的访问是按数据块进行的,也就是按磁盘进行的,每次是一个盘。在图上可以这么看,RAID3是一次一横条,而RAID4一次一竖条。它的特点和RAID3也挺象,不过在失败恢复时,它的难度可要比RAID3大得多了,控制器的设计难度也要大许多,而且访问数据的效率不怎么好。
8、RAID5:分布式奇偶校验的独立磁盘结构
从它的示意图上可以看到,它的奇偶校验码存在于所有磁盘上,其中的p0代表第0带区的奇偶校验值,其它的意思也相同。RAID5的读出效率很高,写入效率一般,块式的集体访问效率不错。因为奇偶校验码在不同的磁盘上,所以提高了可靠性。但是它对数据传输的并行性解决不好,而且控制器的设计也相当困难。RAID 3 与RAID 5相比,重要的区别在于RAID 3每进行一次数据传输,需涉及到所有的阵列盘。而对于RAID 5来说,大部分数据传输只对一块磁盘操作,可进行并行操作。在RAID 5中有"写损失",即每一次写操作,将产生四个实际的读/写操作,其中两次读旧的数据及奇偶信息,两次写新的数据及奇偶信息。
9、RAID6:带有两种分布存储的奇偶校验码的独立磁盘结构
名字很长,但是如果看到图,大家立刻会明白是为什么,请注意p0代表第0带区的奇偶校验值,而pA代表数据块A的奇偶校验值。它是对RAID5的扩展,主要是用于要求数据绝对不能出错的场合。当然了,由于引入了第二种奇偶校验值,所以需要N+2个磁盘,同时对控制器的设计变得十分复杂,写入速度也不好,用于计算奇偶校验值和验证数据正确性所花费的时间比较多,造成了不必须的负载。我想除了军队没有人用得起这种东西。
10、RAID7:优化的高速数据传送磁盘结构
RAID7所有的I/O传送均是同步进行的,可以分别控制,这样提高了系统的并行性,提高系统访问数据的速度;每个磁盘都带有高速缓冲存储器,实时操作系统可以使用任何实时操作芯片,达到不同实时系统的需要。允许使用SNMP协议进行管理和监视,可以对校验区指定独立的传送信道以提高效率。可以连接多台主机,因为加入高速缓冲存储器,当多用户访问系统时,访问时间几乎接近于0。由于采用并行结构,因此数据访问效率大大提高。需要注意的是它引入了一个高速缓冲存储器,这有利有弊,因为一旦系统断电,在高速缓冲存储器内的数据就会全部丢失,因此需要和UPS一起工作。当然了,这么快的东西,价格也非常昂贵。
11、RAID10:高可靠性与高效磁盘结构
这种结构无非是一个带区结构加一个镜象结构,因为两种结构各有优缺点,因此可以相互补充,达到既高效又高速的目的。大家可以结合两种结构的优点和缺点来理解这种新结构。这种新结构的价格高,可扩充性不好。主要用于数据容量不大,但要求速度和差错控制的数据库中。
12、RAID53:高效数据传送磁盘结构
越到后面的结构就是对前面结构的一种重复和再利用,这种结构就是RAID3和带区结构的统一,因此它速度比较快,也有容错功能。但价格十分高,不易于实现。这是因为所有的数据必须经过带区和按位存储两种方法,在考虑到效率的情况下,要求这些磁盘同步真是不容易。
- 网络存储技术
1)网络附加存储介绍
NAS(Network Attached Storage,网络附加存储)是一种将分布、独立的数据整合为大型、集中化管理的数据中心,以便于对不同主机和应用服务器进行访问的技术。是三种主要常见存储方式之一(DAS直连存储,NAS网络附加存储,SAN网络存储),NAS被定义为一种特殊的专用数据存储服务器,包括存储器件(例如磁盘阵列、CD/DVD驱动器、磁带驱动器或可移动的存储介质)和内嵌系统软件,可提供跨平台文件共享功能。
NAS被定义为一种特殊的专用数据存储服务器,包括存储器件(例如磁盘阵列、CD/DVD驱动器、磁带驱动器或可移动的存储介质)和内嵌系统软件,可提供跨平台文件共享功能。
一个LAN上占有自己的节点,无需应用服务器的干预,允许用户在网络上存取数据,在这种配置中,NAS集中管理和处理网络上的所有数据,将负载从应用或企业服务器上卸载下来,有效降低总拥有成本,保护用户投资。
NAS本身能够支持多种协议(如NFS、CIFS、FTP、HTTP等),而且能够支持各种操作系统。通过任何一台工作站,采用IE或Netscape浏览器就可以对NAS设备进行直观方便的管理。
NAS和SAN最大的区别就在于NAS有文件操作和管理系统,而SAN却没有这样的系统功能,其功能仅仅停留在文件管理的下一层,即数据管理。SAN和 NAS并不是相互冲突的,是可以共存于一个系统网络中的,但NAS通过一个公共的接口实现空间的管理和资源共享,SAN仅仅是为服务器存储数据提供一个专门的快速后方通道
2)存储区域网络
存储区域网络(Storage Area Network,简称SAN)采用网状通道(Fibre Channel ,简称FC,区别与Fiber Channel光纤通道)技术,通过FC交换机连接存储阵列和服务器主机,建立专用于数据存储的区域网络。SAN经过十多年历史的发展,已经相当成熟,成为业界的事实标准(但各个厂商的光纤交换技术不完全相同,其服务器和SAN存储有兼容性的要求)
2.1)特性
性能:存储区域网络支持两台或多台服务器对磁带或磁带队列的高速并行访问,这增强了系统性能;
有效性:存储区域网络通常在区外场所备份数据、常常超过10公里( 6.2 英里) ,这大大增加了系统的有效性;
可扩展性:存储区域网络能够使用多种技术;这就使得系统间的数据备份、操作、文件转移和数据复制很容易实现重定向。
2.2)结构
SAN实际是一种专门为存储建立的独立于TCP/IP网络之外的专用网络。目前一般的SAN提供2Gb/S到4Gb/S的传输数率,同时SAN网络独立于数据网络存在,因此存取速度很快,另外SAN一般采用高端的RAID阵列,使SAN的性能在几种专业存储方案中傲视群雄。
SAN由于其基础是一个专用网络,因此扩展性很强,不管是在一个SAN系统中增加一定的存储空间还是增加几台使用存储空间的服务器都非常方便。通过SAN接口的磁带机,SAN系统可以方便高效的实现数据的集中备份。
目前常见的SAN有FC-SAN和IP-SAN,其中FC-SAN为通过光纤通道协议转发SCSI协议,IP-SAN通过TCP协议转发SCSI协议。
2.3)优点
SAN提供了一种与现有LAN连接的简易方法,并且通过同一物理通道支持广泛使用的SCSI和IP协议。SAN不受现今主流的、基于SCSI存储结构的布局限制。特别重要的是,随着存储容量的爆炸性增长,SAN允许企业独立地增加它们的存储容量。
SAN的结构允许任何服务器连接到任何存储阵列,这样不管数据置放在那里,服务器都可直接存取所需的数据。因为采用了光纤接口,SAN还具有更高的带宽。
因为SAN解决方案是从基本功能剥离出存储功能,所以运行备份操作就无需考虑它们对网络总体性能的影响。SAN方案也使得管理及集中控制实现简化,特别是对于全部存储设备都集群在一起的时候。最后一点,光纤接口提供了10公里的连接长度,这使得实现物理上分离的、不在机房的存储变得非常容易
2.4)局限
成本和复杂性,特别是在光纤信道中这些缺陷尤其明显。使用光纤信道的情况下,合理的成本大约是1千兆或者两千兆大概需要五万到六万美金。从另一个角度来看,虽然新推出的基于iSCSI的SAN解决方案大约只需要两万到三万美金,但是其性能却无法和光纤信道相比较。在价格上的差别主要是由于iSCSI技术使用的是现在已经大量生产的吉比特以太网硬件,而光纤通道技术要求特定的价格昂贵的设备
- 集群存储技术
1)高可用性和集群技术
1.1高可用性
高可用性H.A.(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性。它与被认为是不间断操作的容错技术有所不同。HA系统是企业防止核心计算机系统因故障停机的最有效手段。
1.1)概述
随着IT信息系统的不断发展,数据在企业的应用越来越广,如何提高IT系统的高可用性成为建设稳健的计算机系统的首要任务之一。构成计算机网络系统的三大要素是:网络系统,服务器系统,存储系统。网络系统包括防火墙,路由器等网络设备,服务器系统主要指用户使用的各种服务器系统,存储系统,则是用户最主要的数据存储的地点。
因此IT系统的高可用建设应包括网络设备高可用性,服务器设备高可用性,及存储设备的高可用性三个方面。
1.2)分类
一:网络高可用
由于网络存储的快速发展,网络冗余技术被不断提升,提高IT系统的高可用性的关键应用就是网络高可用性,网络高可用性与网络高可靠性是有区别的,网络高可用性是通过匹配冗余的网络设备实现网络设备的冗余,达到高可用的目的。
比如冗余的交换机,冗余的路由器等
二:服务器高可用
服务器高可用主要使用的是服务器集群软件或高可用软件来实现。
三:存储高可用
使用软件或硬件技术实现存储的高度可用性。其主要技术指标是存储切换功能,数据复制功能,数据快照功能等。当一台存储出现故障时,另一台备用的存储可以快速切换,达到存储不停机的目的。
1.3)功能
1)软件故障监测与排除
2)备份和数据保护
3)管理站能够监视各站点的运行情况,能随时或定时报告系统运行状况,故障能及时报告和告警,并有必要的控制手段
4)实现错误隔离以及主、备份服务器间的服务切换
HA的工作方式:HA有主从方式和双工方式两种工作模式
1.2 集群技术
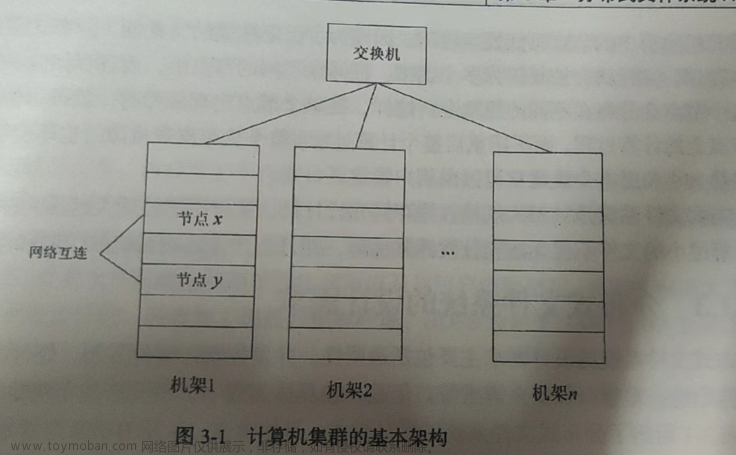
集群(cluster)技术是一种较新的技术,通过集群技术,可以在付出较低成本的情况下获得在性能、可靠性、灵活性方面的相对较高的收益,其任务调度则是集群系统中的核心技术。
集群是一组相互独立的、通过高速网络互联的计算机,它们构成了一个组,并以单一系统的模式加以管理。一个客户与集群相互作用时,集群像是一个独立的服务器。集群配置是用于提高可用性和可缩放性。
1.2.1 目的
1 )提高性能
一些计算密集型应用,如:天气预报、核试验模拟等,需要计算机要有很强的运算处理能力,现有的技术,即使普通的大型机器计算也很难胜任。这时,一般都使用计算机集群技术,集中几十台甚至上百台计算机的运算能力来满足要求。提高处理性能一直是集群技术研究的一个重要目标之一。
2) 降低成本
通常一套较好的集群配置,其软硬件开销要超过100000美元。但与价值上百万美元的专用超级计算机相比已属相当便宜。在达到同样性能的条件下,采用计算机集群比采用同等运算能力的大型计算机具有更高的性价比。
3) 提高可扩展性
用户若想扩展系统能力,不得不购买更高性能的服务器,才能获得额外所需的CPU 和存储器。如果采用集群技术,则只需要将新的服务器加入集群中即可,对于客户来看,服务无论从连续性还是性能上都几乎没有变化,好像系统在不知不觉中完成了升级。
4 )增强可靠性
集群技术使系统在故障发生时仍可以继续工作,将系统停运时间减到最小。集群系统在提高系统的可靠性的同时,也大大减小了故障损失。
1.2.2分类
1 )科学集群
科学集群是并行计算的基础。通常,科学集群涉及为集群开发的并行应用程序,以解决复杂的科学问题。科学集群对外就好像一个超级计算机,这种超级计算机内部由十至上万个独立处理器组成,并且在公共消息传递层上进行通信以运行并行应用程序。
2 )负载均衡集群
负载均衡集群为企业需求提供了更实用的系统。负载均衡集群使负载可以在计算机集群中尽可能平均地分摊处理。负载通常包括应用程序处理负载和网络流量负载。这样的系统非常适合向使用同一组应用程序的大量用户提供服务。每个节点都可以承担一定的处理负载,并且可以实现处理负载在节点之间的动态分配,以实现负载均衡。对于网络流量负载,当网络服务程序接受了高入网流量,以致无法迅速处理,这时,网络流量就会发送给在其它节点上运行的网络服务程序。同时,还可以根据每个节点上不同的可用资源或网络的特殊环境来进行优化。与科学计算集群一样,负载均衡集群也在多节点之间分发计算处理负载。它们之间的最大区别在于缺少跨节点运行的单并行程序。大多数情况下,负载均衡集群中的每个节点都是运行单独软件的独立系统。
但是,不管是在节点之间进行直接通信,还是通过中央负载均衡服务器来控制每个节点的负载,在节点之间都有一种公共关系。通常,使用特定的算法来分发该负载。
3 )高可用性集群
当集群中的一个系统发生故障时,集群软件迅速做出反应,将该系统的任务分配到集群中其它正在工作的系统上执行。考虑到计算机硬件和软件的易错性,高可用性集群的主要目的是为了使集群的整体服务尽可能可用。如果高可用性集群中的主节点发生了故障,那么这段时间内将由次节点代替它。次节点通常是主节点的镜像。当它代替主节点时,它可以完全接管其身份,因此使系统环境对于用户是一致的。
高可用性集群使服务器系统的运行速度和响应速度尽可能快。它们经常利用在多台机器上运行的冗余节点和服务,用来相互跟踪。如果某个节点失败,它的替补者将在几秒钟或更短时间内接管它的职责。因此,对于用户而言,集群永远不会停机。
在实际的使用中,集群的这三种类型相互交融,如高可用性集群也可以在其节点之间均衡用户负载。同样,也可以从要编写应用程序的集群中找到一个并行集群,它可以在节点之间执行负载均衡。从这个意义上讲,这种集群类别的划分是一个相对的概念,不是绝对的。
1.2.3 系统结构
根据典型的集群体系结构,集群中涉及到的关键技术可以归属于四个层次:
(1)网络层:网络互联结构、通信协议、信号技术等。
(2)节点机及操作系统层高性能客户机、分层或基于微内核的操作系统等。
(3)集群系统管理层:资源管理、资源调度、负载平衡、并行IPO、安全等。
(4)应用层:并行程序开发环境、串行应用、并行应用等。
集群技术是以上四个层次的有机结合,所有的相关技术虽然解决的问题不同,但都有其不可或缺的重要性。
集群系统管理层是集群系统所特有的功能与技术的体现。在未来按需(On Demand)计算的时代,每个集群都应成为业务网格中的一个节点,所以自治性(自我保护、自我配置、自我优化、自我治疗)也将成为集群的一个重要特征。自治性的实现,各种应用的开发与运行,大部分直接依赖于集群的系统管理层。此外,系统管理层的完善程度,决定着集群系统的易用性、稳定性、可扩展性等诸多关键参数。正是集群管理系统将多台机器组织起来,使之可以被称为"集群"。
2)集群存储技术
集群存储
集群存储是将多台存储设备中的存储空间聚合成一个能够给应用服务器提供统一访问接口和管理界面的存储池,应用可以通过该访问接口透明地访问和利用所有存储设备上的磁盘,可以充分发挥存储设备的性能和磁盘利用率。
数据将会按照一定的规则从多台存储设备上存储和读取,以获得更高的并发访问性能。
2.1定义
集群存储是将多台存储设备中的存储空间聚合成一个能够给应用服务器提供统一访问接口和管理界面的存储池,应用可以通过该访问接口透明地访问和利用所有存储设备上的磁盘,可以充分发挥存储设备的性能和磁盘利用率。数据将会按照一定的规则从多台存储设备上存储和读取,以获得更高的并发访问性能。
2.2概述
集群存储是指:由若干个"通用存储设备"组成的用于存储的集群,组成集群存储的每个存储系统的性能和容量均可通过"集群"的方式得以叠加和扩展。
传统的存储系统由于受到其物理组成(例如:控制器性能,总线性能,磁盘驱动器的数量,所连接服务器的数量,内存大小,NAS头的性能等)的限制,以及功能上的局限(例如:支持文件系统的容量,元数据和数据处理通路的耦合,快照或复制的数量等),造成了存储系统瓶颈的出现。
一旦遇到存储系统的瓶颈,就会有两种选择:一是:采用硬件更加强大的单个存储系统;二是:采用若干个普通性能的存储系统来组成"存储的集群"。"集群"作为一项已被广泛使用的体系结构,如果采用到存储上组成"集群存储",就可提供按比例增加的存储资源的性能、容量、可靠性及可用性,突破了单机设备的种种限制。
2.3特点
1)开放式架构(高扩展性)
它针对集群存储内部构成元素而言。一般集群存储应该包括存储节点、前端网络、后端网络等三个构成元素,每个元素都可以非常容易地采用业界最新技术而不用改变集群存储的架构,且扩展起来非常方便,像搭积木一样进行存储的扩展。特别是对于那些对数据增长趋势较难预测的用户,可以先购买一部分存储,当有需求的时候,随时添加,而不会影响现有存储的使用。
2)分布式操作系统
这是集群存储的灵魂所在。所有对集群存储的操作都经由分布式操作系统统一调度和分发,分散到集群存储各个存储节点上完成。使用分布式操作系统带来的好处是各节点之间没有任何区别,没有主次、功能上的区别,所有存储节点功能完全一致,这样才能真正做到性能最优。
3)统一命名空间
统一命名空间在很多厂家的存储概念中都出现过。在集群存储中,统一命名空间强调的是同一个文件系统下的统一命名空间。它同样可以支持上PB级别的存储空间。如果是通过将若干有空间上限的卷挂载到某一个根目录的方式来达到统一命名空间,其效率和出现存储热点时的性能将会大大低于把上PB级别的存储空间置于同一个文件系统下管理的统一命名空间。
4)易管理性
目前存储业界的管理方式都是通过各厂商的管理工具,或通过Web界面进行管理和配置,往往客户端还需要安装相关软件才能访问到存储上的空间。随着需要管理的存储空间逐渐增大,管理存储的复杂度和管理人员的数量也将会随之增加。而集群存储应该提供一种集中的、简便易用的管理方式,对客户端没有任何影响,采用业界标准的访问协议(比如NFS,CIFS)访问集群存储。
5)负载均衡
集群存储通过分布式操作系统的作用,会在前端和后端都实现负载均衡。前端访问集群存储的操作,通过几种负载均衡策略,将访问分散到集群存储的各个存储节点上。后端访问数据,通过开放式的架构和后端网络,数据会分布在所有节点上进行存放和读取。
6)高性能
关于高性能领域,目前对集群存储的讨论还仅局限在高带宽、高并发访问的应用模式下。毫无疑问,集群存储对于该类应用可以提供比传统存储架构更优的性能。但目前应用除了高带宽、高并发访问类的之外,还有高IOPS、随机访问、小文件访问以及备份归档等其他类的应用,集群存储应该在以上领域同样提供高性能的解决方案。
- 数据灾备技术
1)数据备份与灾难恢复
1.1数据备份
数据备份是指为防止系统出现操作失误或系统故障导致数据丢失,而将全部或部分数据集合从应用主机的硬盘或阵列复制到其他存储介质的过程,其目的是在发生破坏之后,能够恢复原来的数据。
1.2.灾难恢复
灾难恢复是将信息系统从灾难造成的故障或瘫痪状态恢复到可正常运行状态,并将其支持的业务功能从灾难造成的不正常状态恢复到可接收状态,而设计的活动和流程。因此,数据备份的目的是进行灾难恢复,这里有两方面的含义:一方面是指备份数据的恢复,另一个方面是指业务功能的恢复。
1.3.备份数据恢复的目的
备份数据恢复的根本目的是数据恢复,在数据遭受破坏或其他特定情况下能够
快速、正确、方便地恢复数据,才是备份系统的真正价值所在。
1.4.数据备份分类
按照备份介质存放的地理位置,可以将数据备份分为本地备份和异地备份。本地备份是将备份文件放在本地的存储介质中,或者直接放在与源数据相同的存储介质中;异地备份则是容灾的基础,将本地重要数据通过网络实时传送到异地备份介质中。
1.4.1备份还可以分为热备和冷备,热备指的是备份介质带电运行,需要时可以快速连接使用;冷备是指将备份介质掉电保存,使用时需接入电,有时也称“离线备份”。通常热备数据是访问频次较高的数据,使用的存储介质一般为磁盘、阵列等,而冷备数据通常访问频次很低,多使用磁带库等低成本、大容量设备。热备又分为本机热备和网络备份,网络备份一般使用局域网或备份网络将数据备份在其他存储介质中。
1.5数据备份的组成部分:
- 备份客户端:系统内需要进行数据各份的任何计算机都可以称为备份客户端。备份客户端通常是指的用服务器、数据库服务器或文件服务器。备份客户端也用来表示能从在线存储器上读取数据来将数据传送到备份服务器的软件组件。
(2)备份服务器:将数据复制到各类介质并保存历史备份信息的计算机系统称为备份服务器。备份服务器通常分成主备份服务器和介质服务器。
(3)备份存储单元:备份存储单元包括数据磁带、磁盘、光盘或磁盘阵列。通常由介质服务器控制和管理。备份是主备份服务器、备份客户端和介质服务器三方协作的过程。
- 备份管理软件:备份硬件是完成备份任务的基础,而备份软件则关系到是否能够将备份硬件的优良特性完全发挥出来。必须采用可靠的硬件产品与具有在线备份功能的自动备份软件(在使用磁带库的时代,要求磁带库能够自动加载)来进行按策略、按计划、按时备份。备份管理软件同时也是进行数据恢复的管理软件。
1.6.数据备份架构:基于主机(Host-Base)、基于局域网(LAN-Base)、基于SAN的LAN-Free和Server-Free等。
1.7.数据备份的三中类型:
(1)完全备份:完全备份是将需要备份的所有数据、系统和文件完整备份到备份存储介质中。备份系练不会检查自上次备份后,档案有没有被改动过,它只是机械性地将每个档案读出、写入。备份全部选中的文件及文件夹,并不依赖文件的存盘属性来确定备份哪些文件。
每个档案都要写到备份装置上会浪费大量存储空间。例如,完整的备份文件要占据50GB的存储空间,而每天发生改变的文件只有几十MB,每次备份却要将50GB的内容进行完全备份,显然太浪费时间和空间,且没有必要。因此不会每次备份都使用完全备份。
(2)增量备份:增量备份是备份自上一次备份(包含完全备份、差异备份、增量备份)之后有变化的数据,每次备份只需备份与前一次相比增加或被修改的文件。这就意味着,第一次增量备份的对象是进行完全备份后所产生的增加和修改的文件;第二次增量备份的对象是进行第一次增量备份后所产生的增加和修改的文件,以此类推。这种备份方式最显著的优点就是没有重复的备份数据,因此备份的数据量不大,备份所需的时间很短。但增量备份的数据恢复是比较麻烦的,必须具有上一次完全备份和所有增量备份文件,并且它们必须沿着从完全备份到依次增量备份的时间顺序逐个恢复,极大地延长了数据恢复所需时间。
要避免复原一个又一个的递增数据,提升数据恢复的效率,把增量备份的方法稍微改变一下,就变成了差异备份。
(3)差异备份:差异备份是指在一次完全备份后到进行差异备份的这段时间内,对那些增加或修改文件的备份。在进行恢复时,我们只需对第一次完全备份和最后一次差异备份进行恢复。差异备份在避免了另外两种备份策略缺陷的同时,又具备了它们各自的优点。首先,它具有增量备份需要时间短、节省磁盘空间的优势;其次,它又具有完全备份恢复所需磁带少、恢复时间短的特点。
差异备份的大小会随着时间不断增加(假设在完全备份期间,每天修改的档案都不一样)。以备份空间与速度来说,差异备份介于增量备份与完全备份之间,但无论复原一个档案或整个系统,其速度通常比完全备份、增量备份快。
基于这些特点,差异备份是值得考虑的方案,增量备份与差异备份技术在部分中高端的网络附加存储设备的附带软件中已内置。
2)容灾技术
2.1容灾概述
容灾是指在相隔较远的异地,建立两套或多套功能相同的IT系统,它们之间可以进行健康状态监视和功能切换,当一处系统因意外(如火灾、地震等)停止工作时,整个应用系统可以切换到另一处,使得该系统功能可以继续正常工作。
备份是容灾的基础,容灾不只是备份,还要保证业务的连续性。容灾技术是系统高可用性技术的一个组成部分,容灾系统更加强调处理外界环境对系统的影响,特别是灾难性事件对整个IT节点的影响,提供节点级别的系统恢复功能。
2.2容灾级别
根据容灾系统对灾难的抵抗程度,可分为数据容灾和应用容灾。数据容灾是指建立一个异地的数据系统,该系统对本地系统关键应用数据实时复制。当出现灾难时,可由异地系统迅速接替本地系统从而保证业务的连续性。应用容灾比数据容灾层次更高,即在异地建立一个完整的、与本地数据系统相当的备份应用系统(可以同本地应用系统互为备份,也可与本地应用系统共同工作)。在灾难出现后,远程应用系统迅速接管或承担本地应用系统的业务运行。
2.3容灾的两个最重要的技术指标是RTO和RPO
(1)RTO(Recovery Time Objective,恢复时间目标):指灾难发生后,将信息系统从灾难造成的故障或瘫痪状态恢复到可正常运行状态,并将其支持的业务功能从灾难造成的不正常状态恢复到可接收状态所需的时间,其中包括备份数据恢复到可用状态所需的时间、数据处理系统切换时间、备用网络切换时间等。该指标用以衡量容灾方案的业务恢复能力,是企业可容许服务中断的时间长度。比如灾难发生后半天内便需要恢复,RTO值就是12。
(2)RPO (Recovery Point Objective,恢复点目标):灾难发生后,系统和数据必须恢复到的时间点要求,是指业务系统所允许的灾难过程中的最大数据丢失量(以时间来度量),这是一个与数据备份系统所选用的技术有密切关系的指标,用以衡量灾难恢复方案的数据冗余备份能力。
两者的值要充分考虑到备份数据的重要程度和业务中断时间的允许范围。目前很多公司的容灾备份方案都可以实现RPO=0,RTO接近于0,即保证数据0丢失,业务停顿时间可缩短至60秒内。
2.4容灾关键技术
远程镜像技术、快照技术、互联技术、重复数据删除技术。
2.5云计算环境下的数据灾备
数据实时备份、应用级集中云容灾、云到云的容灾(多云系统)
- 分布式存储
- 分布式存储概述
1.1集中式存储系统
集中式存储系统是指由一台或多台计算机组成中心管理节点,数据集中存储于这个中心节点,整个系统的所有业务单元也都集中部署在这个中心节点,系统所有功能均由其集中处理。也就是说,在集中式存储系统中,每个终端或客户端仅负责数据的录入和输出,而数据的存储与控制处理完全交由主机来完成。
集中式存储系统最大的特点就是部署结构简单,由于集中式存储系统往往基于底层性能卓越的大型主机,因此无须考虑如何对服务进行多个节点的部署,也就无须考虑多个节点之间的分布式协作问题。
1.2 分布式存储系统
分布式存储系统是大量普通PC服务器通过 Internet互联、应用分布式软件对外作为一个整体提供存储服务。分布式存储系统主要有可扩展、低成本、高性能、易用性等特点。
分布式架构存储的出现带来了新的活力,在每次添加新的节点和服务后,其数据存储容量和性能得到提升。分布式存储是存储架构上的重大创新,在设计上采用 Scale out 架构,针对海量数据需求,集中式存储扩展能力有限,或者说扩展成本过高,出于成本上的考虑,用户开始转向分布式存储。
1.3 分布式存储分类
分布式存储系统目前将其分为四种系统:分布式文件系统,分布式键值系统,分布式表格系统和分布式数据库系统
- 分布式文件系统。互联网应用需要存储大量的图片、照片、视频等非结构化数据对象,这类数据以对象的形式组织,它们之间没有关联,这样的数据一般为Blob(Binary Large Object,二进制大对象)数据。分布式文件系统存储三种数据:Blob对象、定长块及大文件。在系统的实现层面,分布式文件系统内部按照数据块(Chunk)来组织数据,每个数据块的大小相同,每个数据可以包含多个Blob对象或定长块,一个大文件也可以拆分成为多个数据块。分布式文件系统将这些数据块分散存储到分布式存储集群中去,处理数据的复制、一致性、负载均衡、容错等分布式系统难题,并将用户对Blob对象、定长块及大文件的操作映射成对底层数据块的操作。另外,分布式文件系统也常作为分布式表格系统及分布式数据库系统的底层存储。
(2)分布式键值系统。分布式键值系统用于存储关系简单的半结构化数据,它只提供基于主键的CRUD(Create/Read/Update/Delete)功能,即根据主键创建、读取、更新或删除键值记录。典型的系统有 Amazon Dynamo 及 Taobao Tair。分布式键值系统是分布式表格系统的一种简化的实现,一般用来对数据进行缓存。一致性哈希是分布式键值系统中常用的数据分布技术。
- 分布式表格系统。分布式表格系统用于存储关系较为复杂的半结构化数据,与分布式键值系统相比,分布式表格系统不但支持简单的CRUD操作,而且支持扫描某个主键范围。典型的系统包括 Google Bigtable、Megastore、Microsoft Azure Table Storage、Amazon DynamoDB等。
(4)分布式数据库系统。分布式数据库系统是从单机关系的数据库扩展而来的,用于存储结构化数据。分布式数据库采用二维表的形式组织数据,根据SQL关系查询语言,支持多表关联、嵌套子查询等复杂操作,并提供数据库事务及并发控制。典型的系统包括MySQL数据库分集(MySQL Sharding), Amazon RDS 及 Microsoft SQL Azure。
另外,根据分布式存储的应用场景和存储接口不同,可以将分布式存储分为三种类型:块存储、文件存储、对象存储。
- 分布式文件系统
分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。分布式文件系统的设计基于客户机/服务器模式。一个典型的网络可能包括多个供多用户访问的服务器。另外,对等特性允许一些系统扮演客户机和服务器的双重角色。例如,用户可以"发表"一个允许其他客户机访问的目录,一旦被访问,这个目录对客户机来说就像使用本地驱动器一样,下面是三个基本的分布式文件系统。
2.1简介
计算机通过文件系统管理、存储数据,而信息爆炸时代中人们可以获取的数据成指数倍的增长,单纯通过增加硬盘个数来扩展计算机文件系统的存储容量的方式,在容量大小、容量增长速度、数据备份、数据安全等方面的表现都差强人意。分布式文件系统可以有效解决数据的存储和管理难题:将固定于某个地点的某个文件系统,扩展到任意多个地点/多个文件系统,众多的节点组成一个文件系统网络。每个节点可以分布在不同的地点,通过网络进行节点间的通信和数据传输。人们在使用分布式文件系统时,无需关心数据是存储在哪个节点上、或者是从哪个节点从获取的,只需要像使用本地文件系统一样管理和存储文件系统中的数据。
2.2决定因素
文件系统最初设计时,仅仅是为局域网内的本地数据服务的。而分布式文件系统将服务范围扩展到了整个网络。不仅改变了数据的存储和管理方式,也拥有了本地文件系统所无法具备的数据备份、数据安全等优点。判断一个分布式文件系统是否优秀,取决于以下三个因素:
l 数据的存储方式,例如有1000万个数据文件,可以在一个节点存储全部数据文件,在其他N个节点上每个节点存储1000/N万个数据文件作为备份;或者平均分配到N个节点上存储,每个节点上存储1000/N万个数据文件。无论采取何种存储方式,目的都是为了保证数据的存储安全和方便获取。
l 数据的读取速率,包括响应用户读取数据文件的请求、定位数据文件所在的节点、读取实际硬盘中数据文件的时间、不同节点间的数据传输时间以及一部分处理器的处理时间等。各种因素决定了分布式文件系统的用户体验。即分布式文件系统中数据的读取速率不能与本地文件系统中数据的读取速率相差太大,否则在本地文件系统中打开一个文件需要2秒,而在分布式文件系统中各种因素的影响下用时超过10秒,就会严重影响用户的使用体验。
l 数据的安全机制,由于数据分散在各个节点中,必须要采取冗余、备份、镜像等方式保证节点出现故障的情况下,能够进行数据的恢复,确保数据安全。
2.2.1 mooseFS
MooseFS是一个具备冗余容错功能的分布式网络文件系统,它将数据分别存放在多个物理服务器或单独磁盘或分区上,确保一份数据有多个备份副本。对于访问的客户端或者用户来说,整个分布式网络文件系统集群看起来就像一个资源一样。从其对文件操作的情况看,MooseFS就相当于一个类UNIX文件系统
1)适用场景
MooseFS是一款相对小众的分布式文件系统,不需要修改上层应用接口即可直接使用,支持FUSE的操作方式,部署简单并提供Web界面的方式进行管理与监控,同其他分布式操作系统一样,支持在线扩容,并进行横向扩展。MooseFS还具有可找回误操作删除的文件,相当于一个回收站,方便业务进行定制;同时MooseFS对于海量小文件的读写要比大文件读写的效率高的多。但MooseFS的缺点同样明显,MFS的主备架构情况类似于MySQL的主从复制,从可以扩展,主却不容易扩展。短期的对策就是按照业务来做切分,随着MFS体系架构中存储文件的总数上升,Master Server对内存的需求量会不断增大。并且对于其单点问题官方自带的是把数据信息从Master Server同步到Metalogger Server上,Master Server一旦出问题Metalogger Server可以恢复升级为Master Server,但是需要恢复时间。目前,也可以通过第三方的高可用方案(heartbeat+drbd+moosefs)来解决 Master Server 的单点问题。
2)四大组件
MooseFS文件系统主要由四大组件构成,分别为管理服务器、元数据日志服务器、数据存储服务器、客户端,相关解释如下:
2.1)管理服务器(Master Server):这个组件的角色是管理整个mfs文件系统的主服务器,除了分发用户请求外,还用来存储整个文件系统中的每个数据文件的metadata信息,metadata(元数据)信息包括文件(也可以是目录、socket、管道、设备等)的大小、属性、文件位置路径等,以及文件空间的回收和恢复,控制多chunk server节点的数据拷贝。很类似lvs负载均衡主服务器,不同的是lvs仅仅根据算法分发请求,而master根据内存里的metadata信息来分发请求。这个master只能有一台处于激活工作的状态。
2.2)元数据日志服务器(metalogger Server):作用是备份管理服务器master的变化的metadata信息日志文件,文件类型为changelog_ml.*.mfs,以便于在主服务器出现问题的时候,可以经过简单的操作即可让新主服务器进行工作。这很类似Mysql的主从同步,只不过他不像mysql从库那样在本地应用数据,而只是接收主服务器上文件写入时记录的文件相关的metadata信息。这个backup可以有一台或多台,它很类似于lvs从负载均衡器。
2.3)数据存储服务器(Chunk Servers):存放数据文件实体的服务器了,这个角色可以有多台不同的物理服务器或不同的磁盘及分区来充当,当配置数据的副本多于一份时,剧写入到一个数据服务器后,会根据算法在其他数据服务器上进行同步备份。
2.4)客户端(Client):挂载并使用mfs文件系统的客户端,当读写文件时,客户端首先连接主管理服务器获取数据的metadata信息,然后根据得到的metadata信息,访问数据服务器读取或写入文件实体。mfs客户端通过FUSE mechanism实现挂载MFS文件系统的。因此,只要系统支持FUSE,就可以作为客户端访问MFS整个文件系统。所谓的客户端并不是网站用户,而是前端访问文件系统的应用服务器,如web
2.2.2 HDFS
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。
HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。
1)特点和目标
(1)硬件故障
硬件故障是常态,而不是异常。整个HDFS系统将由数百或数千个存储着文件数据片段的服务器组成。实际上它里面有非常巨大的组成部分,每一个组成部分都很可能出现故障,这就意味着HDFS里的总是有一些部件是失效的,因此,故障的检测和自动快速恢复是HDFS一个很核心的设计目标。
(2)数据访问
运行在HDFS之上的应用程序必须流式地访问它们的数据集,它不是运行在普通文件系统之上的普通程序。HDFS被设计成适合批量处理的,而不是用户交互式的。重点是在数据吞吐量,而不是数据访问的反应时间,POSIX的很多硬性需求对于HDFS应用都是非必须的,去掉POSIX一小部分关键语义可以获得更好的数据吞吐率。
(3)大数据集
运行在HDFS之上的程序有很大量的数据集。典型的HDFS文件大小是GB到TB的级别。所以,HDFS被调整成支持大文件。它应该提供很高的聚合数据带宽,一个集群中支持数百个节点,一个集群中还应该支持千万级别的文件。
(4)简单一致性模型
大部分的HDFS程序对文件操作需要的是一次写多次读取的操作模式。一个文件一旦创建、写入、关闭之后就不需要修改了。这个假定简单化了数据一致的问题,并使高吞吐量的数据访问变得可能。一个Map-Reduce程序或者网络爬虫程序都可以完美地适合这个模型。
(5)移动计算比移动数据更经济
在靠近计算数据所存储的位置来进行计算是最理想的状态,尤其是在数据集特别巨大的时候。这样消除了网络的拥堵,提高了系统的整体吞吐量。一个假定就是迁移计算到离数据更近的位置比将数据移动到程序运行更近的位置要更好。HDFS提供了接口,来让程序将自己移动到离数据存储更近的位置。
(6)异构软硬件平台间的可移植性
HDFS被设计成可以简便地实现平台间的迁移,这将推动需要大数据集的应用更广泛地采用HDFS作为平台。
(7)名字节点和数据节点
HDFS是一个主从结构,一个HDFS集群是由一个名字节点,它是一个管理文件命名空间和调节客户端访问文件的主服务器,当然还有一些数据节点,通常是一个节点一个机器,它来管理对应节点的存储。HDFS对外开放文件命名空间并允许用户数据以文件形式存储。
内部机制是将一个文件分割成一个或多个块,这些块被存储在一组数据节点中。名字节点用来操作文件命名空间的文件或目录操作,如打开,关闭,重命名等等。它同时确定块与数据节点的映射。数据节点负责来自文件系统客户的读写请求。数据节点同时还要执行块的创建,删除,和来自名字节点的块复制指令。
名字节点和数据节点都是运行在普通的机器之上的软件,机器典型的都是GNU/Linux,HDFS是用java编写的,任何支持java的机器都可以运行名字节点或数据节点,利用java语言的超轻便性,很容易将HDFS部署到大范围的机器上。典型的部署是由一个专门的机器来运行名字节点软件,集群中的其他每台机器运行一个数据节点实例。体系结构不排斥在一个机器上运行多个数据节点的实例,但是实际的部署不会有这种情况。
集群中只有一个名字节点极大地简单化了系统的体系结构。名字节点是仲裁者和所有HDFS元数据的仓库,用户的实际数据不经过名字节点。
2.2.3 TFS
-TFS(Taobao FileSystem)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化了文件的访问流程,一定程度上为TFS提供了良好的读写性能。
-特性
1) 采用扁平化的数据组织结构
2)使用HA架构和平滑扩容
3)支持多种客户端
4)支持大小文件存储
5)可为外部提供高可靠和高并发的存储访问
6)支持大文件功能
7)Resource Center Server,用于管理TFS集群的用户资源配置
8)TFS服务程序开发框架,统一TFS网络客户端库,并新增异步回调功能
9)优化数据流,让写请求尽可能均匀的分布在不同的DataServer
-总体结构
一个TFS集群由两个NameServer节点(一主一备)和多个!DataServer节点组成。这些服务程序都是作为一个用户级的程序运行在普通Linux机器上的。
在TFS中,将大量的小文件(实际数据文件)合并成为一个大文件,这个大文件称为块(Block), 每个Block拥有在集群内唯一的编号(Block Id), Block Id在NameServer在创建Block的时候分配, NameServer维护block与DataServer的关系。Block中的实际数据都存储在DataServer上。而一台DataServer服务器一般会有多个独立DataServer进程存在,每个进程负责管理一个挂载点,这个挂载点一般是一个独立磁盘上的文件目录,以降低单个磁盘损坏带来的影响。
3)分布式对象存储
3.1对象存储与文件存储的区别
对象存储和文件存储的区别不大,只是文件管理方式不同,抛弃了统一命名空间的目录树结构,使得扩展起来桎梏少一些。
3.2 Amazon S3
amazon (S3) 是一个公开的服务,Web 应用程序开发人员可以使用它存储数字资产,包括图片、视频、音乐和文档。 S3 提供一个 RESTful API 以编程方式实现与该服务的交互。
1)概述
amazon (S3) 是一个公开的服务,Web 应用程序开发人员可以使用它存储数字资产,包括图片、视频、音乐和文档。 S3 提供一个 RESTful API 以编程方式实现与该服务的交互。
云是一个抽象的概念,表示松散连接在一起的计算机组,这些计算机共同执行某项任务或者服务,就像是使用一个单独的实体完成一样。此概念背后的架构也很抽象:每个云提供者都可以根据各自情况随意设计它的产品。软件即服务(Software as a Service,SaaS)是一个与云相关的概念,表示云向用户提供某种服务。云模型可以降低用户成本,因为他们无需购买软件和硬件也可以运行 - 服务提供者已经为用户提供了必要的组件。
3.3 Swift
Swift,苹果于2014年WWDC苹果开发者大会发布的新开发语言,可与Objective-C共同运行于macOS和iOS平台,用于搭建基于苹果平台的应用程序。
Swift是一款易学易用的编程语言,而且它还是第一套具有与脚本语言同样的表现力和趣味性的系统编程语言。Swift的设计以安全为出发点,以避免各种常见的编程错误类别。
1)应用范围
Swift是一种新的编程语言,用于编写iOS和macOS应用。Swift结合了C和Objective-C的优点并且不受C兼容性的限制。Swift采用安全的编程模式并添加了很多新特性,这将使编程更简单,更灵活,也更有趣。Swift是基于成熟而且倍受喜爱的Cocoa和Cocoa Touch框架,他的降临将重新定义软件开发。
Swift的开发从很久之前就开始了。为了给Swift打好基础,苹果公司改进了编译器,调试器和框架结构。我们使用自动引用计数(Automatic Reference Counting, ARC)来简化内存管理。我们在Foundation和Cocoa的基础上构建框架栈并将其标准化。Objective-C本身支持块、集合语法和模块,所以框架可以轻松支持现代编程语言技术。正是得益于这些基础工作,我们才能发布这样一个用于未来苹果软件开发的新语言。
Objective-C开发者对Swift并不会感到陌生。它采用了Objective-C的命名参数以及动态对象模型,可以无缝对接到现有的Cocoa框架,并且可以兼容Objective-C代码。在此基础之上,Swift还有许多新特性并且支持过程式编程和面向对象编程。
2)操作优点
Swift 对于初学者来说也很友好。它是第一个既满足工业标准又像脚本语言一样充满表现力和趣味的编程语言。它支持代码预览,这个革命性的特性可以允许程序员在不编译和运行应用程序的前提下运行Swift代码并实时查看结果。
3)应用优势
Swift将现代编程语言的精华和苹果工程师文化的智慧结合了起来。编译器对性能进行了优化,编程语言对开发进行了优化,两者互不干扰,鱼与熊掌兼得。Swift 既可以用于开发"hello, world"这样的小程序,也可以用于开发一套完整的操作系统。所有的这些特性让 Swift对于开发者和苹果来说都是一项值得的投资。
3.4 Ceph
Linux持续不断进军可扩展计算空间,特别是可扩展存储空间。Ceph 最近加入到 Linux 中令人印象深刻的文件系统备选行列,它是一个分布式文件系统,能够在维护 POSIX 兼容性的同时加入了复制和容错
1)基本简介
Ceph是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式文件系统。
2)由来
其命名和UCSC(Ceph 的诞生地)的吉祥物有关,这个吉祥物是 "Sammy",一个香蕉色的蛞蝓,就是头足类中无壳的软体动物。这些有多触角的头足类动物,是对一个分布式文件系统高度并行的形象比喻。
Ceph 最初是一项关于存储系统的 PhD 研究项目,由 Sage Weil 在 University of California, SantaCruz(UCSC)实施。
3)未来发展
作为分布式文件系统,其能够在维护 POSIX 兼容性的同时加入了复制和容错功能。从 2010 年 3 月底,您可以在Linux 内核(从2.6.34版开始)中找到 Ceph 的身影,作为Linux的文件系统备选之一,Ceph.ko已经集成入Linux内核之中。虽然目前Ceph 可能还不适用于生产环境,但它对测试目的还是非常有用的。
Ceph 不仅仅是一个文件系统,还是一个有企业级功能的对象存储生态环境。
现在,Ceph已经被集成在主线 Linux 内核中,但只是被标识为实验性的。在这种状态下的文件系统对测试是有用的,但是对生产环境没有做好准备。但是考虑到Ceph 加入到 Linux 内核的行列,不久的将来,它应该就能用于解决海量存储的需要了。
一些开源的云计算项目已经开始支持Ceph,事实上Ceph是目前OpenStack生态系统中呼声最高的开源存储解决方案。这些项目都支持通过libvirt调用Ceph作为块设备进行读写访问。
- 软件定义存储
- 软件定义存储概述
1.1 软件定义的概念
软件定义的存储产品是一个将硬件抽象化的解决方案,它可以轻松地将所有资源池化并通过一个友好的用户界面(UI)或API来提供给消费者。一个软件定义存储的解决方案可以在不增加任何工作量的情况下进行纵向扩展(Scale Up)或横向扩展(Scale Out)。
1.2软件定义存储的概念
软件定义存储(SDS)是一种能将存储软件与硬件分隔开的存储架构。运行在行业标准系统或 x86 系统上执行,从而消除了软件对于专有硬件的依赖性。
1.2.1软件定义存储的优点:
1)可以自行选择运行存储服务的硬件。
2)采用横向扩展的分布式结构,允许对性能和容量进行独立扩展。
3)提供API等管理方式,可实现自动化运维。
4)完美支持云原生架构。
1.3 SDS与存储虚拟化
SDS和存储虚拟化非常类似,但是并不是存储虚拟化。
存储虚拟化可以将多个存储设备或阵列的容量组成一个池,使其看起来就像在一个设备上,通常只能在专门的硬件设备上使用。SDS 并没有将存储容量与存储设备剥离开来,而是将存储功能或服务与存储设备剥离开来。SDS的目标是将复杂的存储系统封装成为易操作的服务,用户可以通过一个软件或管理界面方便地管理自己的所有存储资源和内容。
SDS应包括以下几种功能。
(1)自动化:简化管理,降低维护存储架构的成本。
(2)标准接口:提供应用编程接口,用于管理、部署和维护存储设备和存储服务。
(3)虚拟数据路径:提供块、文件和对象的接口,支持应用通过这些接口写入数据。
(4)扩展性:无须中断应用,便可以提供可靠性和性能的无缝扩展。
(5)透明性:提供存储消费者对存储使用状况及成本的监控和管理。
1.4 SDS产品分类
1.4.1.SDS控制平面
在SDS控制平面这一层,比较著名的有:VMware SPBM (Storage Policy Base Management,基于存储策略的管理)、OpenStack Cinder(块存储服务)、EMC ViPR、HP StoreVirtual、ProphetStor(希智)的Federator、FalconStor(飞康)的Freestor。
1.4.2.SDS数据平面
在SDS数据平面这一层的构成比较复杂,组成部分较多。
“基于商用的硬件”只是一个笼统的说法,其产品种类繁多,这里主要罗列了 Server SAN,并将超融合架构作为 Server SAN 的一个子集。
传统的外置磁盘阵列,包括SAN存储或NAS存储也纷纷加入SDS浪潮。例如,EMCVNX、NetApp FAS 系列、HDS HUS、DELL SC 系列和PS系列、HP 3PAR、IBMV系列和DS系列、华为OceanStor系列等。
云存储和对象存储作为数据平面的组成部分,实际上是以后端存储的身份为VM/App提供存储资源的。VM/App可以通过RESTful API等接口与对象存储进行数据的输入和输出。目前有三种 RESTful API: Amazon S3、 SNIA CDMI 和 OpenStack Swift。
- server SAN
2.1 Server SAN的概念
Server SAN架构属于Hyperscale,聚合和闪存趋势交汇的技术。随着设备和联网存储(包括DAS和SAN)的分离,共享和管理大量数据的需求促生了存储阵列。而企业闪存方案的出现后,存储智能又回到运算的范畴。聚合型架构和Hyperscale架构通过创建可重复堆栈级别的部署来简化操作。高速低延时,闪存,数据爆炸和新应用设计等等,都为IT架构的重组带来了机遇。
2.2 sever SAN特点
Server SAN主要有以下特点:聚合存储和计算;可口开命;者灵活,可“动态”添加/删除服务器和容量;性能高,适合大规模1/O并行处理。
2.3 Server SAN 与集群 NAS
集群NAS是集群存储的实现方式,是将NAS服务器构建集群,以集群文件系统管理后端SAN存储设备池,集群NAS属于文件系统存储,其本质上计算和存储仍是分离的。而ServerSAN是给SAN加上Server,实现计算和存储的统一,Server SAN一般属于块存储系统。
- 超融合架构
3.1 超融合架构的概念
超融合架构系统是指要具备在各个水平上均可用的存储弹性。例如,超融合系统依赖于软件将各种组件联系在一起,所以不允许有任何的单点故障。有很多方式可以实现超融合架构弹性设计。像是VMware,在一个虚拟设备中运行软件,必要时可以故障转移到另外的节点。
3.2超融合应用场景
从存储属性来看,正如软件定义存储的分类所描述的那样,HCI属于软件定义存储的数据平面。HCI具有在线横向扩展的特性,非常适合云化的时代,但云化所需的存储资源即刻交付、动态扩展、在线调整,其实还需要借助控制平面的存储策略才能完成。软件定义存储还包含能被控制平面层(如VMware SPBM、OpenStack Cinder等)驱动的外置共享存储,不过这部分发展在国内还相对缓慢。
在进行超融合架构评估时,首先要考虑的事情之一就是可扩展性。只要通过增加另外一个节点,你就能够扩展你的超融合部署。底层软件应该足够智能,能够自动将虚拟服务器负载分布于集群各个节点,而无需管理员手动执行负载平衡。同样,新节点应该提供一个线性的性能增益
- 网盘技术应用
- 网盘概述
1.1网盘的概念
网盘 ,又称网络U盘、网络硬盘,是由互联网公司推出的在线存储服务,服务器机房为用户划分一定的磁盘空间,为用户免费或收费提供文件的存储、访问、备份、共享等文件管理等功能,并且拥有高级的世界各地的容灾备份。 用户可以把网盘看成一个放在网络上的硬盘或U盘,不管你是在家中、单位或其它任何地方,只要你连接到因特网,你就可以管理、编辑网盘里的文件。不需要随身携带,更不怕丢失。
1.2网盘的分类
网盘产品种类繁多,下面分别从云端应用模式、同步方式、收费模式、产品面向角度进行分类介绍。
1)云端应用模式来分
从云端应用模式来分,网盘可以分为公有云网盘、私有云网盘、个人网盘。
市场上的网盘产品大部分属于公有云网盘,如百度网盘、腾讯微云、360云盘、OneDrive、Google Drive等。这类网盘产品技术比较成熟,服务质量比较稳定。大部分都提供永久免费存储空间,例如,百度网盘提供2TB免费空间(永久)、腾讯微云提供10GB免费空间(永久)、360云盘提供5GB免费空间(30天)等。
目前公有云网盘的缺点就是下载速度慢,例如,百度网盘非会员账号下载速度是会员账号下载速度的数十甚至数百分之一。考虑到其他公有云存储服务使用时,网络下行流量的收费价格,非会员网盘下载速度受限也就可以理解了。
出于性能要求和数据安全方面的考虑,不少企事业单位选择部署私有云网盘(企业网盘),为单位员工提供网盘服务,具体实现有两种:一种是直接购买整体解决方案,将网盘服务器部署在单位机房;另一种是在单位原有服务器上自己部署的开源网盘系统。
私有云网盘最大的优点之一是灵活可控、安全有保障,其缺点是购置成本较高、需要持续维护。
个人网盘是一些DIY爱好者不甘心受制于网盘服务商在价格、速度上的约束,而自行使用开源软件部署在空闲主机上的网盘系统。用户可以根据自己的喜好和需求进行自我定制,其最大的问题之一是为了保证能随时使用,承载网盘系统的主机需要经常保持在开启状态,这在家用环境下不太现实。
2)从同步方式来分
从同步方式来分,网盘有同步网盘和非同步网盘。
3)从收费模式来分
从收费模式来分,网盘可以分为免费网盘和付费网盘。这里的免费网盘是指提供永久免费存储空间的网盘,如腾讯微云、百度网盘等。虽然扩容和提升服务需要付费,但免费空间是永久的。从这个角度看,百度网盘提供的2TB存储空间太大方了。
付费网盘是指没有永久免费空间的收费网盘,这类网盘在经过短暂的免费试用期后,必质付费才能继续使用,不想付费使用的用户只能直接放弃试用,以免网上数据丢失或转存文件麻烦。
4)从产品面向角度来分
从产品面向角度来分,网盘分为个人网盘和企业网盘。
这里讲的个人网盘是指针对个人客户的网盘,给个人用户提供文档资料和图片的存储服务,包括百度网盘、360云盘、华为网盘、QQ网盘等。
企业网盘给企业用户提供文档资料存储、外链分享、同步、沟通协作等服务。目前提供企业网盘服务的有:搜狐企业网盘、燕麦(OATOS)企业云盘、115网盘等。
1.3网盘主要有如下性能特点:
(1)网盘有方便的文件管理功能。支持多文件类型,实现在线集中管理;支持断点续传;单个文件上传网盘大小无限制;支持在线预览功能,无须下载,可直接查看文件内容;具有用户习惯的目录结构。
(2)网盘能够实现多平台数据同步。支持Web客户端、电脑客户端、手机客户端操作;同步网盘能够实现共享文件自动同步,并实时查看最新修改的内容。
(3)网盘可以实现高效的协同共享。当多人共同编辑一份文档时,无须借助其他工具就能实现文档同步更新,并能够自动生成新版本,随时可以找回历史版本进行还原。对共享文件夹的访问权限可基于角色进行动态设定。通过邮件通知文件夹的修改动态。
(4)网盘能实现快捷的文件分享,可以与其他应用无缝连接。
(5)网盘有灵活的权限管理功能,可以按照需要分配子账号空间,按群组管理部门或团队(企业私有云网盘具有的功能)。支持详细日志查询使用记录,支持回收站误删恢复。
(6)网盘有全方位安全机制,采用必要的加密措施,有完善的数据备份和容灾机制,保障稳定运营,实现自动备份保障数据安全
2)网盘产品简介
2.1 Cloudreve
Cloudreve是一个开源网盘系统,使用 ThinkPHP+ React+ Redux+ Material-UI构建,能够帮助用户以较低成本快速搭建起公私兼备的网盘。Cloudreve提供三种搭建方式:通过Composer安装、通过 Docker 安装和通过官网安装包安装。 Cloudreve 最典型的特点之一是支持用户搭建的网盘系统对接多家公有云存储的对象服务。Cloudreve具体有如下鲜明特点。
1.)对接公有云存储
用户可以将文件存放在本地,也可以经过简单配置快速对接七牛、又拍云、阿里云OSS、AWS S3,前提是购买了公有云存储的资源。
2.)多用户系统
可以将 Cloudreve作为私有云使用,它提供的强大的用户系统也可作为公有云平台使用,实现多人协作。
3.)可设置上传策略
不同用户组可绑定不同上传策略,并在多个上传策略间快速切换,充分利用存储资源。
4.)支持在线预览
免费的公有云网盘系统一般都不支持文件的预览和在线编辑,而搭建Cloudreve可以支持图片、视频、音频、Office文档在线预览,以及文本文件、Markdown文件的在线编辑。
5.)文件分享
文件分享是网盘的必备功能,但私有网盘一般很难提供。Cloudreve用户可以创建私有或公有分享链接,快速将文件、目录分享给好友。
6. )webdev 支持
Cloudreve 支持将网盘映射到本地管理,或者使用其他支持 webdev 协议的文件管理器,实现无缝跨平台。
2.2 青云本地盘
青云QingStor推出了一款本地盘产品,用户可以将QingStor对象存储的存储空间挂载为Windows/Linux平台下的磁盘或文件目录,由QingStor对象存储为其提供无限容量的在线文件存储空间,而不占用本地磁盘空间。用户可以像操作本地磁盘一样方便、快捷地访问或存取QingStor对象存储空间(Bucket)中的各常用类型文件(如文档、图片、音视频、二进制归档、压缩文件等)。它适用于数据迁移或备份、应用系统无缝对接对象存储、个人用户磁盘扩容等场景。
2.2.1
青云本地盘使用了两种方式实现资源本地挂载。
Mountain Duck 是 Windows平台上挂载访问对象存储的第三方客户端软件,推荐使用其作为QingStor对象存储的挂载工具。由QingStor对象存储为其提供无限容量的在线文件存储空间,而不占用本地磁盘空间。通过 Mountain Duck 可以像操作本地磁盘(如C盘、D盘等)一样方便、快捷地访问或存取 QingStor Bucket 中的各种类型文件。
QingStor对象存储本地盘for Linux(又名qsfs)是Linux平台上的挂载工具,基于FUSE的文件系统,允许 Linux 将 QingStor对象存储的存储空间挂载成本地目录,可以像操作本地目录一样方便、快捷地访问或存取QingStor对象存储的存储空间中的各常用类型文件。
2.2.2青云本地盘产品具有如下特点。
1.)高可靠、高可用
依托QingStor对象存储,提供高可靠、高可用的在线文件存储。
2.)无限水平扩展
可承载无限存储空间,存储空间的容量可无限扩展。
3.)简单易用
可直接通过本地磁盘的操作方式对 QingStor对象存储中的文件、文件夹进行增加、删除、
修改、查看等操作。
4.)开机启动
开机时可自动启动并挂载到相应的QingStor对象存储的存储空间中。
5.)应用系统无缝对接对象存储
企业为了解决应用系统对接对象存储,往往需要修改应用程序代码,把对文件系统的读写改成调用对象存储SDK。如果不便于修改应用系统程序,依然想要使用对象存储作为存储后端,则可以通过 Mountain Duck 实现和 QingStor对象存储无缝对接,使应用系统即刻拥有海量的数据存储空间。
6.)个人用户磁盘扩容文章来源:https://www.toymoban.com/news/detail-494869.html
个人用户的电脑磁盘容量比较有限,通过 Mountain Duck 将 QingStor 对象存储的存储空间挂载为本地磁盘或文件系统后,可以扩展用户个人电脑的本地磁盘容量,相当于增加一个可无限水平扩展的磁盘,作为一个类似于网盘的方式进行使用。文章来源地址https://www.toymoban.com/news/detail-494869.html
到了这里,关于云存储技术与应用学习小结的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!