一、问题重述
今天在问答模块回答了一道问题,要睡觉的时候,又去看了一眼,发现回答错了。
问题描述:下面的z的值是多少。
#define FUN(a,b) a<b?a:b
int x = 5, y = 8, z;
z = 4 + FUN(x, y);
我当时的回答是:z=4+5=9
但是编译运行的结果是:8

又看了一眼,恍然大悟,我曾经在文章中写过:宏的替换是简单的文本替换(请好好理解这句话),它在预处理阶段进行。当编译器遇到宏名称时,会将其替换为定义中指定的代码片段。宏替换是直接替换,没有类型检查或语法分析。
上面的代码经过预处理后是:
z = 4 + 5 < 8 ? 5:8 ;
现在,z=8应该没问题了。
如果是:
#define FUN(a,b) (a<b?a:b)
结果则是9
如果是:
#define FUN(a,b) (a<b)?a:b
结果则是5
二、AI 解题
突然好奇,这个问题,AI会不会做错呢,结果令我大吃一惊😲😲
2.1 ChatGPT
第一次问:
我说答案是8,他依旧坚持9,来来回回拉扯好几次:
n次拉扯后:
2.2 NewBing
只能说孺子可教:
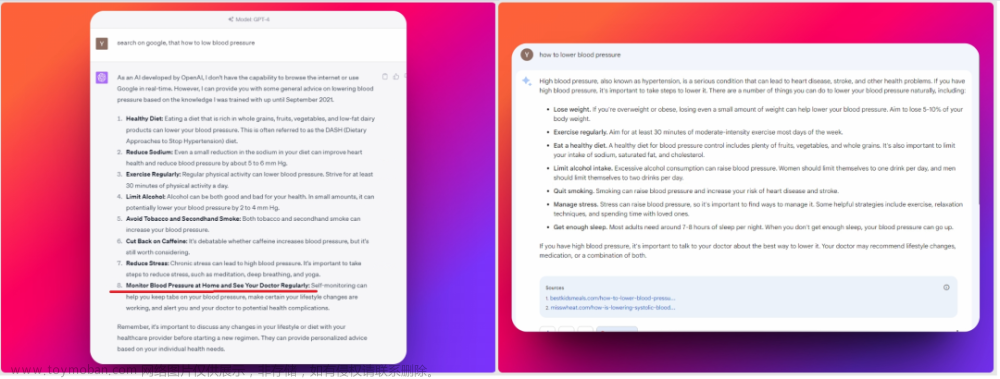
2.3 Google Bard
情况跟ChatGPT差不多:
(1)
(2)

2.4 文心一言
这位更是重量级😅: 毕竟它自称擅长文本创作这方面。

其他国内模型就不展开了,差不多。
2.5 小结
(1)注意细节
我明明知道宏定义是文本替换,仍然反了错,实属不该。
(2)AI 并不完全可靠
从这个例子就可以看出,现在,AI 并不完全可靠(当然AI成长的很快)。如果我不知道宏定义的知识,当问了几个AI模型后,可能就会坚信那个错误答案。所以,对信息的甄别能力是很重要的。另外,也要提升自己的能力,才能在未来更好地使用AI工具。
为什么这些AI模型会犯错呢?
它们并不是万能的,本文的这个问题也不是什么复杂的难题,它们却全答错了,而且还要纠正半天。这应该与模型的训练数据有关,或许很少有人像上面那样写代码,或许很多人都犯这个错。对于保密程度很高的内容、前沿技术、特殊情况…AI或许不比人高明。
(3)AI模型版本
上面的问答中,NewBing的效果相对较好,轻轻一点就能修正错误。
-
ChatGPT iOS手机APP中使用的免费版本是:GPT-.5,Plus是4.0。

-
ChatGPT网页版 :5.10号已经放弃使用GPT-3.5的Lagacy版本,现在使用的是default版本,应该是做了优化,Plus用户可以选择GPT4。

-
NewBing手机版和网页版都是:GPT-4.0

从上面的叙述可以发现,GPT-4貌似比GPT-3.5好上许多。
GPT-4 的提升:
可以在GPT-4的paper中看到与3.5的对比。
paper摘要:
这是一种大规模的多模态模型,可以接受图像和文本输入并产生文本输出。虽然在许多现实场景中的能力不如人类,但 GPT-4 在各种专业和学术基准测试中表现出人类水平的表现,包括通过模拟律师考试,得分在应试者的前 10% 左右。 GPT-4 是一种基于 Transformer 的预训练模型,用于预测文档中的下一个标记。培训后的对齐过程会提高真实性和遵守所需行为的措施的性能。该项目的核心组成部分是开发可在广泛范围内表现可预测的基础设施和优化方法。这使我们能够基于不超过 GPT-4 计算量的 1/1,000 的训练模型准确预测 GPT-4 性能的某些方面。
总结一下GPT3.5和GPT4.0的区别:
-
GPT3和GPT4的最大不同之处在于规模,GPT3拥有175B参数,而GPT4拥有3.3T参数,可以有效地解决复杂语言任务。
-
另一个重要的不同之处在于GPT4使用了树型推理(Tree-Based Reasoning)来完成建模,这使得GPT4更加稳定、精确、高效。GPT4的模型可以有效地解决自然语言交互(NLU)和自然语言理解(NLU)等复杂NLP任务。
-
更创造性的写作能力,包括编歌曲、写剧本、学习用户写作风格
-
可以接受图片输入(暂不可用)、并生成字幕等
-
可以处理超过25000字长文本
-
智能程度大幅提升。以美国BAR律师执照统考为例:GPT3.5可以达到10%水平分,GPT4可以达到90%水平分。生物奥林匹克竞赛从GPT3.5的31%水平分,直接飙升到99%水平分,国际奥赛金奖水准。
真是一场历史性变革~文章来源:https://www.toymoban.com/news/detail-494939.html
把 永 远 爱 你 写 进 诗 的 结 尾 ~ 文章来源地址https://www.toymoban.com/news/detail-494939.html
到了这里,关于一个关于宏定义的问题,我和ChatGPT、NewBing、Google Bard、文心一言 居然全军覆没?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!