什么是Apache Kafka?
参考答案:Apache Kafka是一个分布式流处理平台,用于高吞吐量、可持久化、容错的数据传输。它以高效的发布-订阅模型来处理实时数据流。
Kafka的核心概念有哪些?
参考答案:Kafka的核心概念包括主题(Topic)、分区(Partition)、偏移量(Offset)、生产者(Producer)、消费者(Consumer)和消费者组(Consumer Group)。
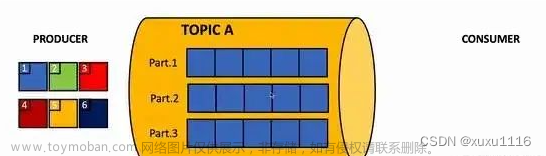
Kafka的主题(Topic)是什么?
参考答案:主题是Kafka中数据的分类,用于将数据进行逻辑上的分组。生产者将消息发布到主题,消费者通过订阅主题来接收消息。
Kafka的分区(Partition)有什么作用?
参考答案:分区是主题的物理分片,用于实现数据的并行处理和负载均衡。每个分区在磁盘上都有自己的日志文件,生产者和消费者可以针对不同的分区进行并行读写。
Kafka的偏移量(Offset)是什么?
参考答案:偏移量是消息在分区中的唯一标识符。消费者通过记录偏移量来追踪已经读取的消息,从而实现消息的精确消费。
Kafka的生产者(Producer)是什么?
参考答案:生产者是向Kafka主题发布消息的客户端。它负责将消息发送到指定的主题和分区。
Kafka的消费者(Consumer)是什么?
参考答案:消费者是从Kafka主题订阅并接收消息的客户端。它可以按照不同的消费模式(如拉取模式和推送模式)从分区中读取消息。
Kafka的消费者组(Consumer Group)是什么?
参考答案:消费者组是一组消费者实例的集合,它共同消费一个或多个主题的消息。Kafka使用消费者组来实现消息的负载均衡和容错性。
Kafka如何保证消息的持久化和可靠性?
参考答案:Kafka通过将消息持久化到磁盘上的日志文件来实现消息的持久化和可靠性。它采用了复制机制,将消息复制到多个副本中,以实现故障恢复和数据冗余。
Kafka与传统消息队列(如ActiveMQ、RabbitMQ)有何不同?
参考答案:Kafka相对于传统消息队列有以下不同之处:
高吞吐量:Kafka具有高吞吐量的特点,适合处理大规模的实时数据流。
分布式和可扩展:Kafka是一个分布式系统,可以水平扩展以适应大规模数据处理。
持久化:Kafka将消息持久化到磁盘,保证消息的可靠性和持久性。
多订阅者模型:Kafka的发布-订阅模型允许多个消费者以消费者组的形式订阅同一个主题。
高并发性能:Kafka能够在多个生产者和消费者之间实现高并发的消息传输。
Kafka的消息是如何进行排序的?
参考答案:Kafka保证同一个分区内的消息顺序性,但在不同分区之间无法保证全局的消息顺序。在单个分区内,消息的顺序是根据消息的偏移量(Offset)进行排序的。
Kafka的消息保留策略有哪些?
参考答案:Kafka的消息保留策略包括时间保留策略和大小保留策略。时间保留策略是基于消息在Kafka中存储的时间来决定消息的保留期限,而大小保留策略是基于主题的总大小来决定消息的保留期限。
Kafka的复制机制是如何工作的?
参考答案:Kafka使用复制机制来提供高可用性和容错性。每个分区的消息被复制到多个副本中,其中一个副本作为领导者(Leader)处理读写请求,其他副本作为追随者(Follower)进行复制。当领导者副本失效时,会从追随者中选举新的领导者。
Kafka中的ISR是什么?
参考答案:ISR(In-Sync Replica)是指与领导者副本保持同步的副本集合。只有在ISR中的副本才能被选为新的领导者,确保数据的一致性。
Kafka的数据压缩有哪些方式?
参考答案:Kafka支持多种数据压缩方式,包括Gzip、Snappy和LZ4。可以通过配置生产者和消费者的压缩类型来选择适合的压缩算法。
Kafka如何处理消费者的消费速度小于生产者的生产速度?
参考答案:Kafka提供了流量控制的机制来处理消费者消费速度小于生产者生产速度的情况。消费者可以通过控制消费的偏移量来调整消费的速率。
Kafka中的零拷贝技术是什么?
参考答案:Kafka使用零拷贝技术来提高数据传输的效率。在数据传输过程中,Kafka避免了数据的多次拷贝操作,直接在操作系统的缓冲区中进行数据传输,减少了CPU和内存的开销。
Kafka如何处理消息丢失的情况?
参考答案:Kafka通过持久化存储、消息复制和故障恢复机制来处理消息丢失的情况。消息被持久化存储在磁盘上,复制到多个副本中,并在领导者副本失效时选择新的领导者进行数据恢复。
Kafka与其他流处理框架(如Storm、Flink)有何不同?
参考答案:Kafka主要关注数据的高吞吐量传输和持久化,而其他流处理框架(如Storm、Flink)更关注数据的实时计算和处理。Kafka可以作为这些流处理框架的数据源或数据接收器。文章来源:https://www.toymoban.com/news/detail-495022.html
Kafka的优缺点是什么?
参考答案:Kafka的优点包括高吞吐量、可扩展性、持久化和容错性等。缺点包括配置复杂、部署和维护成本高、对于简单场景可能过于重量级等。文章来源地址https://www.toymoban.com/news/detail-495022.html
到了这里,关于kafka面试题二十道的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!