这篇文章记录一下我之前做过的通过Spark与Hive实现的基于协调过滤的电影推荐。这篇文章只能提供算法、思路和过程记录,并没有完整的代码,仅尽量全面地记录过程细节方便参考。
一、数据获取
数据集是从下面这个地址下载的,数据集主要内容是关于用户对电影的评分、评价等。免费数据集下载(很全面)_浅笑古今的博客-CSDN博客_数据集下载网站

图1.1 数据获取
我选取的几个数据集表格如下:

图1.2 数据表格

图1.3 rating表

图1.4 movies表

图1.5 tags表

图1.6 genome-tags表

图1.7 genome-scores表
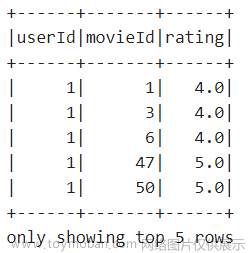
‘ratings’表是关于用户对电影的评分 24404096条
‘movies’表是关于每部电影的基本信息(电影id,名字,种类,电影的上映时间为title的后四个字符) 40110条
‘tags’表是关于用户对电影的评价(后面用tag代替) 259135条
‘genome-tags’表是每个tag的id 1128条
‘genome-scores’表是每部电影与1128个tag的相关度 12040272条

图1.8 数据表总体关系展示
上图中,未被圈起来的内容是表格名称,圈中的内容是表格的字段,表格名称被哪些字段的连线所包围,就说明该表格包括哪些字段,部分被多个表同时拥有的字段也非常恰当的表现在合适的位置从而被多个表关联。
下面也附上各个字段的详细信息介绍:

图1.9 详细字段说明
二、数据清洗与挖掘
2.1获得每部电影的平均得分
首先,根据‘rating’表groupby处理求出每部电影的平均分,再与movies表合并。
代码实现如下(Hive中):
drop table movies;
create table movies (movieId String,title String,genres String) row format delimited fields terminated by ','
tblproperties("skip.header.line.count"="1");
load data local inpath "/usr/local/src/movies.csv" into table movies;
#先把rating表group by处理 带上平均分
select movieId,avg(rating) from ratings group by movieId;
create table movie_avg_rating(movieId String,avg_rating String)
Insert into movie_avg_rating select movieId,avg(rating) from ratings group by movieId;
#再join movies表
create table movies_detail_rating(movieId String,title String,genres String,rating String) ;
Insert into movies_detail_rating
Select movies.movieId,movies.title,movies.genres,movie_avg_rating.avg_rating from movies join movie_avg_rating on movies.movieId =movie_avg_rating.movieId;
得到如下表:

图2.1.1 添加上评分的movies表
2.2 根据tag聚类后对每部电影分类
根据‘genome-scores’中每部电影与tags的相关度进行聚类,将聚类结果分为三类,并加入到movies表中。(这里聚类的原因是因为后面计算电影相似度时如果电影无差别两两计算,数据量会爆炸;因此提前对电影进行聚类,后面只让同类别的电影进行相似度计算,虽然会有损失,但总体上增加计算效率。)
得到的聚类结果如下:

图2.2.1 根据tags相关度聚类结果
聚类代码实现如下(python):
import pandas as pd
import numpy as np
import csv
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
data = pd.read_csv('D:\MovieLens Dataset\ml-latest/genome-scores.csv')
# print(len(data))#1200w条数据
# 逐行读取csv文件
data={}
with open('D:\MovieLens Dataset\ml-latest/genome-scores.csv','r',encoding="utf-8") as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
if data.get(row['movieId'],-1)==-1:
data[row['movieId']]=[row['relevance']]
else:
data[row['movieId']].append(row['relevance'])
print(len(data['1']))
x = []
for k,v in data.items():
# print(k)
x.append(v)
X = np.array(x)
km = KMeans(n_clusters=3).fit(X)
# 标签结果
rs_labels = km.labels_
len(data.keys())
len(rs_labels)
movie_class = pd.DataFrame()
movie_class['movieId']=data.keys()
movie_class['classId']=rs_labels
movie_class.to_csv('D:\MovieLens Dataset\ml-latest/movie_class1.csv',index=False)数据清洗后的‘movies’表格如下。其基本信息包括电影id、title、电影种类(genres)、平均评分(rates)、类别(class)。

图2.2.2 数据清洗后的movies表
2.3 对电影数据可视化分析与数据挖掘
对于已有的数据集,我打算以上映时间为x轴(为了使点离散化,时间在原来基础上增加了一个(0,1)之间的小数),评分为y轴,类别class作为区分色,按电影种类划分的HTML可视化动画(‘All’代表所有种类)。(这部分的实现代码找不到了没贴出来,也不是重点。)
其中三个不同类别电影的可视化动画截图如下:

图2.3.1 Action类别电影评分预览

图2.3.2 Adventure类别电影评分预览

图2.3.3 Comedy类别电影评分预览
通过最后画出来的可视化图像,我们可以清楚的看到每个种类电影的数目、上映时间、评分等信息。 通过观察图标我发现Comedy和Drama类别的电影很多,且评分大都中等偏上,而Child类别评分普遍偏低,其中Film-Noir类别的电影数目很少以至于样点十分稀疏。
之前进行电影推荐时我用了tag来预测电影的class(tag和genres并不一样,是电影的不同属性),正好在可视化的过程中我把点的颜色以class的不同做了划分,来看看基于tag的class在评分上会不会有明显区别。令人惊喜的是:从图上可以看出颜色有明显的分层!说明根据用户评价的tag聚类得到的分类结果是有参考价值的,tag的不同隐约对应或影响着电影评分的分级。这是一个比较有趣的联系。
三、协同过滤算法实现
协同过滤算法的总体思路是根据用户最喜爱的五部电影(该用户评分最高的前五部)找出与这五部电影相关度高的10部电影进行推荐。电影相关度是根据余弦相似度来计算得出的值,每部电影定义为一个向量(如下图),该向量的每一个分量即为不同用户对该部电影的评分,计算每个电影向量与其他电影向量的余弦相似度得到的结果即为电影相关度。

图3.1 电影向量

图3.2 余弦相似度计算公式参考
同时,上面讲了,为了减少计算量,我在计算电影向量的余弦相似度之前,添加限制条件电影的class要相同,并将聚类的结果由原来的3类改为1000类(发现3类还是不太够,再进一步减少计算量),使用的聚类方法还是同上面一致,得到的新类别表为movie_class1.csv,重新导入hive中的movie_class表格。
具体实现步骤如下:
实现代码(hive中):
drop table ratings;
create table ratings (userId String,movieId String,rating String,time String) row format delimited fields terminated by ','
tblproperties("skip.header.line.count"="1");
load data local inpath "/usr/local/src/ratings.csv" into table ratings;
drop table movie_class;
create table movie_class(movieId String,classId String) row format delimited fields terminated by ',' tblproperties("skip.header.line.count"="1");
load data local inpath "/usr/local/src/movie_class1.csv" into table movie_class;
得到的movie_class预览如下:

图3.3 movie_class
将movie_class与rating合并:
drop table rating_class;
create table rating_class(userId String,movieId String,rating String,classId String);
#创建一个新表rating_class并把这些数据放进去 rating_class里包含用户对电影的评分和电影类别。
Insert into rating_class select ratings.userId,ratings.movieId,ratings.rating,movie_class.classId from ratings join movie_class on ratings.movieId=movie_class.movieId ;
得到rating_class如下:

图3.4 rating_calss
来到spark-shell界面,引入必要的扩展包和初始化配置:
import breeze.numerics.{pow, sqrt}
import org.apache.spark.sql.SparkSession
import breeze.numerics.{pow, sqrt}
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions.{desc, row_number, udf}
import org.apache.spark.sql.{DataFrame, SparkSession}
// 在driver端创建 sparksession
val spark = SparkSession.
builder().
master("local").
appName("testRdd1").
config("hive.metastore.uris",
"thrift://"+"192.168.77.10"+":9083").
// config("spark.sql.warehouse.dir", "F:/recommend/spark-warehouse").
enableHiveSupport().
getOrCreate()
在spark中预览一下之前处理好的表格rating_class,将其读取为变量data。

图3.5 rating_calss
为了计算两个电影之间的相关度,新建copy表复制data的数据并将两表合并,为了减少计算量并加快计算速度,加上前提条件两个表的class相同,使数据由原来的120亿减少到3000万。因为我最后就是要基于相似的电影为用户做推荐,因此类别相似的电影提前过滤出来,不仅减少了不必要数据处理规模,也是对算法的优化。
实现代码如下(scala):
val dataCopy = data.selectExpr("userId as userId1", "movieId as movieId1", "rating as rating1","classId as classId1")
val df_item_decare = dataCopy.join(data, dataCopy("userId1") === data("userId")and dataCopy("classId1") === data("classId")).filter("cast(movieId as long)!=cast(movieId1 as long)");
结果如下:

图3.6 电影复制表
现在准备工作做好了,开始计算电影向量的余弦相似度即两向量的余弦值。
首先是计算分子:
val rating_product = df_item_decare.selectExpr("movieId", "movieId1", "rating*rating1 as rating_product")
val itemSameUserRatingProductSum = rating_product. groupBy("movieId", "movieId1"). //直接以物品对位key,这时候用户已经对好了,然后 后面的相加就是这两个物品相似度的分子了
agg("rating_product" -> "sum").
withColumnRenamed("sum(rating_product)", "rating_sum_product")
得到的分子结果:

图3.7 计算余弦相似度的分子
然后是计算分母:
val itemSqrtRatingSum = data.rdd.map(x => (x(1).toString(), x(2).toString)). //直接把物品对应的所有用户评分都算进去了 作为分母 多算的部分其实无所谓
groupByKey().
mapValues(x => sqrt(x.toArray.map(rating => pow(rating.toDouble, 2)).sum)).
toDF("movieId", "sqrtRating")
得到的分母结果:

图3.8 计算余弦相似度的分母
合并后结果:

图3.9 计算余弦相似度的分母与分子
接下来计算余弦相似度即电影相关度,实验代码如下:
val itemSimilar = baseData.selectExpr("movieId", "movieId1", "rating_sum_product/(sqrtRating*sqrtRatingCopy) as itemSimilar")
val itemSimilar_new = itemSimilar.sort(desc("movieId"), desc("itemSimilar")).filter("itemSimilar > 0" )
得到的结果:

图3.10 电影相关度
现在进行推荐:
var itemSimilarCache:DataFrame=spark.sql("select * from homework.itemsimilar") ;
val userLikeItem = data.withColumn("rank",row_number().over(Window.partitionBy("userId").orderBy($"rating".desc))).filter(s"rank <= 5").drop("rank")此处对每个用户进行统计,其最喜欢的top5个电影,得到的结果如下:

图 3.11 每个用户最喜欢的top5电影
根据用户最喜欢的电影中每部电影的评分与该电影和其他电影的电影相关度乘积作为新的权重进行排序,选取前十部电影推荐给该用户。
实验代码如下:
val recommand_list = userLikeItem.join(itemSimilarCache,"movieId").
filter("movieId<>movieId1").
selectExpr("userId","movieId1 as recall_list","rating*itemSimilar as recall_weight").
withColumn("rank",row_number().over(Window.partitionBy("userId").orderBy($"recall_weight".desc))).filter(s"rank <= 10").drop("rank")
得到的结果如下:

图3.12 给用户推荐的10部电影
最后的到的结果有2563891条,将结果存入数据库并导出到本地文件‘result.xlsx’:
recommand_list.write.mode("overwrite").saveAsTable("homework.recommand_list")
Insert overwrite local directory '/usr/local/src/recommand_list' select * from recommand_list;最终相似度矩阵(推荐结果)result.xlsx预览如下:

图3.13 结果预览
第一个深色列是excel自增id与数据无关,因excel显示行数有限所以只展示到104万行,从这也可以看出推荐结果条数仍不少。第二列是用户id,第三列是电影id,第四列是计算得到的用户对这个电影的预期评分,其值越大就越值得推荐,这里对每个用户都已从大到小取了前十个推荐值用以展示。
后续可以根据这个结果表使用django或者其他简单的可视化组件制作电影推荐界面,这里比如可以通过表中的imdbid字段去爬电影的海报等信息用作可视化界面制作,就省略不写了。文章来源:https://www.toymoban.com/news/detail-495130.html
四、小结
这篇文章整理了在Spark Hive中基于协同过滤的电影推荐算法的实现,实现这些需要一步一步去做,细节较多,有些地方难免也会有没讲清楚和遗漏的,仅供参考学习和记录。文章来源地址https://www.toymoban.com/news/detail-495130.html
到了这里,关于Spark Hive实现基于协同过滤的电影推荐(MovieLens数据集)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!