TCP的拥塞控制算法有四种,分别是慢开始、拥塞避免、快重传和快恢复。
1.慢开始和拥塞避免
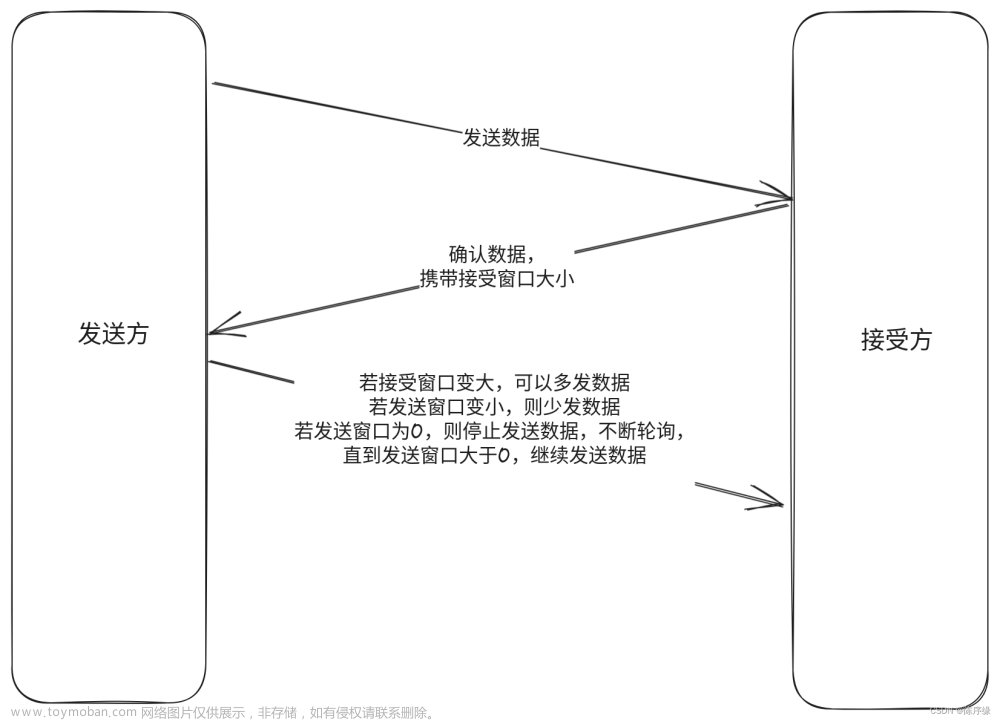
拥塞窗口:
- 基本概念:发送方维持一个叫做拥塞窗口的状态变量。拥塞窗口的大小取决于网络的拥塞程度,并且是动态变化着的。发送方让自己的发送窗口等于拥塞窗口。
- 发送方控制拥塞窗口的原则:只要网络没有出现拥塞,拥塞窗口就可以再增大一些,以便把更多的分组发送出去,这样可以提高网络的利用率。但是只要网络出现拥塞或者可能出现拥塞,就必须把拥塞窗口减小一些,以减小注入到网络中的分组数,以缓解网络出现的拥塞。
- 发送方判断拥塞的方法:因为网络发生拥塞时,路由器就要把来不及处理而排不上队的分组丢弃。因此只要发送方没有按时收到对方的确认报文,也就是出现了超时的情况,就可以认为网络中某处出现了拥塞。
慢开始算法:
- 基本思路:当主机在已经建立的TCP连接上开始发送数据时,并不清楚网络当前的情况。如果贸然把大量数据注入到网络中,则可能引起网络拥塞。经验证明,最好的方式是先探测一下,也就是从小到大逐渐增大注入到网络中的数据量,也就是说,从小到大增大拥塞窗口的值。
- 具体规定:在每收到一个对新的报文段的确认后,可以把拥塞窗口增加最多一个SMSS的数值(往往就是一个)。由此可以看出,发送方并不是在所有的确认都收齐了之后才调整其窗口大小,而是收到一个确认就调整一下拥塞窗口,抓紧时间发送自己的报文段。
-
慢开始门限(ssthresh):为了防止拥塞窗口过大引起网络阻塞,所设置的一个变量,使用方法如下:
- 当cwnd<ssthresh时,使用慢开始算法;
- 当cwnd=ssthresh时,使用两种算法均可;
- 当cwnd>ssthresh时,用拥塞避免算法来代替慢开始算法。
- 意外情况: 有时个别报文会在网络中意外丢失,但是实际网络并未发生拥塞。如果发送方迟迟收不到确认,就会产生超时并误认为网络发生了拥塞。这就导致发送方会启动慢开始算法,把拥塞窗口的值设置为1,从而不必要地降低了传输速率。
拥塞避免算法:
- 基本思想:是的拥塞窗口缓慢增大。
- 具体实现:每经过一个往返时间,发送方的拥塞窗口大小就加一,而不是像开始阶段那样加倍增长。也就是说在拥塞避免阶段采用的是加法增大,比慢开始阶段的增长速率要小得多。
- 发生拥塞情况:当使用拥塞避免算法的过程中出现网络超时,则说明网络发生拥塞。此时,将门限值调整为原先门限值的一半,并从1开始重新执行慢开始算法。
- 注意事项:拥塞避免并非完全避免拥塞,而是让拥塞窗口增长缓慢,使得网络不容易出现拥塞。
2.快重传和快恢复
快重传算法:文章来源:https://www.toymoban.com/news/detail-495364.html
- 作用:可以让发送方尽早知道发生了个别报文段的丢失。可以提高网络整体的吞吐量。
- 基本思想:该算法要求接收方不要等待自己发送数据时才进行捎带确认,而是要立即发送确认。即使收到了失序的报文段也要立即发出对已经收到的报文段的重复确认。
- 算法规定:如果发送方收到3个重复的对某个报文段的确认,则知道当前并未出现网络拥塞,而只是接收方少接收一个报文段,因此立即重传该缺少的报文段。
快恢复算法:文章来源地址https://www.toymoban.com/news/detail-495364.html
- 使用情况:如果发送方知道只是丢失了个别报文段,则不启动慢开始,而是执行快恢复算法。
- 具体操作:在拥塞避免过程中发生了个别报文段的丢失,则发送方将门限值和拥塞窗口都调整为当前拥塞窗口的一半,并继续执行快恢复算法。
到了这里,关于计算机网络笔记:TCP的拥塞控制方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!