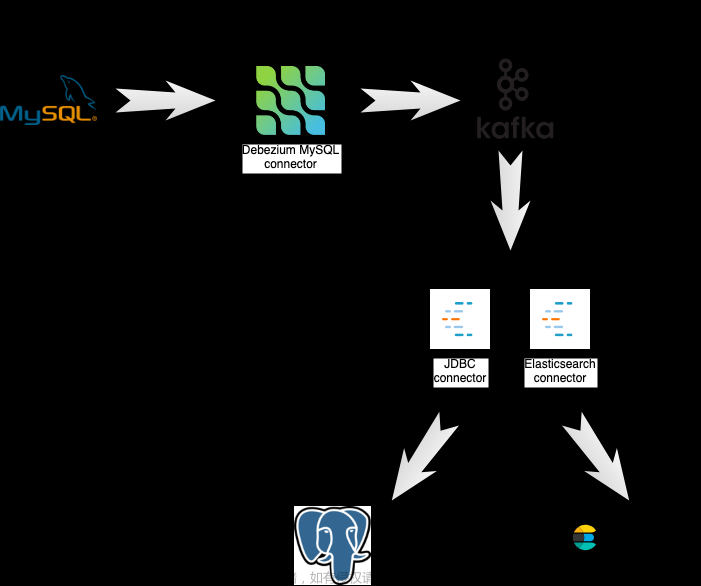
Debezium
环境
Kafka:3.3.2
mysql-connector:1.8.1
部署
(0)前提是安装好mysql,开启binlog
(1)下载kafka
1) tar -zxvf kafka_2.12-3.3.2.tgz -C /opt/software/
2) mkdir /opt/software/kafka_2.12-3.3.2/plugin
(2)下载mysql-connector插件
1)tar -zxvf debezium-connector-mysql-1.8.1.Final-plugin.tar.gz -C /opt/software/kafka_2.12-3.3.2/plugin
(3)编辑配置文件
1)vim connect-distributed.properties
2)尾部追加此配置-》plugin.path=/opt/software/kafka_2.12-3.3.2/plugin
(4)启动kafka自带的zk
nohup bin/zookeeper-server-start.sh config/zookeeper.properties > zkLog.log 2>&1 &
(5)启动kafka
nohup bin/kafka-server-start.sh config/server.properties > kafkaLog.log 2>&1 &
(6)启动connect
bin/connect-distributed.sh config/connect-distributed.properties
(7)调用api
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d '{ "name": "inventory-connector", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "tasks.max": "1", "database.hostname": "localhost", "database.port": "3306", "database.user": "root", "database.password": "Test2022@", "database.server.id": "184055", "database.server.name": "mysql1", "database.include.list": "test", "database.history.kafka.bootstrap.servers": "localhost:9092", "database.history.kafka.topic": "dbhistory.inventory" } }'
注意:当成功调用api,创建此连接器后会有如下主题产生:dbhistory.inventory、mysql1、mysql1.test.people、mysql1.test.student(因为是监控的是test整库,整库下只有people和student两张表,使所以会有此主题),其中dbhistory.inventory、mysql1主题是存储ddl变更记录
【include.schema.changes】改变的是mysql1主题是否会有ddl,默认是true,如果改为false后,此主题不会有ddl过来,但是一旦又改为false后,会把历史没收集的ddl都收集过来,然后继续收集后续的ddl。
【database.history.kafka.topic】无论include.schema.changes是否为true,都会收集对应的ddl,这个主题仅供内部使用,消费者不能使用。
(8)测试
访问http://192.168.31.100:8083/connectors进行测试,如果出现[“inventory-connector”]则成功。
运维
(1)如果要更新配置,则使用此api进行更新【PUT /connectors/{name}/config】eg:
curl -i -X PUT -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/inventory-connector/config -d '{ "connector.class": "io.debezium.connector.mysql.MySqlConnector", "tasks.max": "1", "database.hostname": "localhost", "database.port": "3306", "database.user": "root", "database.password": "Test2022@", "database.server.id": "184055", "database.server.name": "mysql1", "database.include.list": "test", "database.history.kafka.bootstrap.servers": "localhost:9092", "database.history.kafka.topic": "dbhistory.inventory", "include.schema.changes": "true", "database.history.store.only.captured.tables.ddl": "true" }'
(2)动态加表
如果刚开始table.include.list只配置了部分表,后续运行过程中需要动态添加新表,此时通过上述更新接口进行更新table.include.list配置即可,此时会对表进行全量+增量的读取。
(3)路由管理
默认情况下,一个表会创建一个主题。如果表太多,主题就会非常多。此时需要把一批表路由到同一个主题。在连接器配置中加入下几个配置,此时会把全部的表投递到同一个dbz-unique-topic-test主题下。
"transforms": "Reroute",
"transforms.Reroute.type": "io.debezium.transforms.ByLogicalTableRouter", "transforms.Reroute.topic.regex": "(.*)",
"transforms.Reroute.topic.replacement": "dbz-unique-topic-test"
(4)ddl与dml数据的topic合并
通过上述的路由管理,把transforms.Reroute.topic.replacement配置设置成和database.server.name相同的配置。
其他
连接器配置文档
Apache Kafka
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pWCPUTnT-1675678476438)(C:\Users\hp\AppData\Roaming\Typora\typora-user-images\image-20230206143356470.png)]# Debezium
环境
Kafka:3.3.2
mysql-connector:1.8.1
部署
(0)前提是安装好mysql,开启binlog
(1)下载kafka
1) tar -zxvf kafka_2.12-3.3.2.tgz -C /opt/software/
2) mkdir /opt/software/kafka_2.12-3.3.2/plugin
(2)下载mysql-connector插件
1)tar -zxvf debezium-connector-mysql-1.8.1.Final-plugin.tar.gz -C /opt/software/kafka_2.12-3.3.2/plugin
(3)编辑配置文件
1)vim connect-distributed.properties
2)尾部追加此配置-》plugin.path=/opt/software/kafka_2.12-3.3.2/plugin
(4)启动kafka自带的zk
nohup bin/zookeeper-server-start.sh config/zookeeper.properties > zkLog.log 2>&1 &
(5)启动kafka
nohup bin/kafka-server-start.sh config/server.properties > kafkaLog.log 2>&1 &
(6)启动connect
bin/connect-distributed.sh config/connect-distributed.properties
(7)调用api
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d '{ "name": "inventory-connector", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "tasks.max": "1", "database.hostname": "localhost", "database.port": "3306", "database.user": "root", "database.password": "Test2022@", "database.server.id": "184055", "database.server.name": "mysql1", "database.include.list": "test", "database.history.kafka.bootstrap.servers": "localhost:9092", "database.history.kafka.topic": "dbhistory.inventory" } }'
注意:当成功调用api,创建此连接器后会有如下主题产生:dbhistory.inventory、mysql1、mysql1.test.people、mysql1.test.student(因为是监控的是test整库,整库下只有people和student两张表,使所以会有此主题),其中dbhistory.inventory、mysql1主题是存储ddl变更记录
【include.schema.changes】改变的是mysql1主题是否会有ddl,默认是true,如果改为false后,此主题不会有ddl过来,但是一旦又改为false后,会把历史没收集的ddl都收集过来,然后继续收集后续的ddl。
【database.history.kafka.topic】无论include.schema.changes是否为true,都会收集对应的ddl,这个主题仅供内部使用,消费者不能使用。
(8)测试
访问http://192.168.31.100:8083/connectors进行测试,如果出现[“inventory-connector”]则成功。
运维
(1)如果要更新配置,则使用此api进行更新【PUT /connectors/{name}/config】eg:
curl -i -X PUT -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/inventory-connector/config -d '{ "connector.class": "io.debezium.connector.mysql.MySqlConnector", "tasks.max": "1", "database.hostname": "localhost", "database.port": "3306", "database.user": "root", "database.password": "Test2022@", "database.server.id": "184055", "database.server.name": "mysql1", "database.include.list": "test", "database.history.kafka.bootstrap.servers": "localhost:9092", "database.history.kafka.topic": "dbhistory.inventory", "include.schema.changes": "true", "database.history.store.only.captured.tables.ddl": "true" }'
(2)动态加表
如果刚开始table.include.list只配置了部分表,后续运行过程中需要动态添加新表,此时通过上述更新接口进行更新table.include.list配置即可,此时会对表进行全量+增量的读取。
(3)路由管理
默认情况下,一个表会创建一个主题。如果表太多,主题就会非常多。此时需要把一批表路由到同一个主题。在连接器配置中加入下几个配置,此时会把全部的表投递到同一个dbz-unique-topic-test主题下。
"transforms": "Reroute",
"transforms.Reroute.type": "io.debezium.transforms.ByLogicalTableRouter", "transforms.Reroute.topic.regex": "(.*)",
"transforms.Reroute.topic.replacement": "dbz-unique-topic-test"
(4)ddl与dml数据的topic合并
通过上述的路由管理,把transforms.Reroute.topic.replacement配置设置成和database.server.name相同的配置。
其他
1、API接口文档文章来源:https://www.toymoban.com/news/detail-495405.html
Apache Kafka其中的【REST API】部分文章来源地址https://www.toymoban.com/news/detail-495405.html
到了这里,关于Debezium同步Mysql数据到Kafka的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!