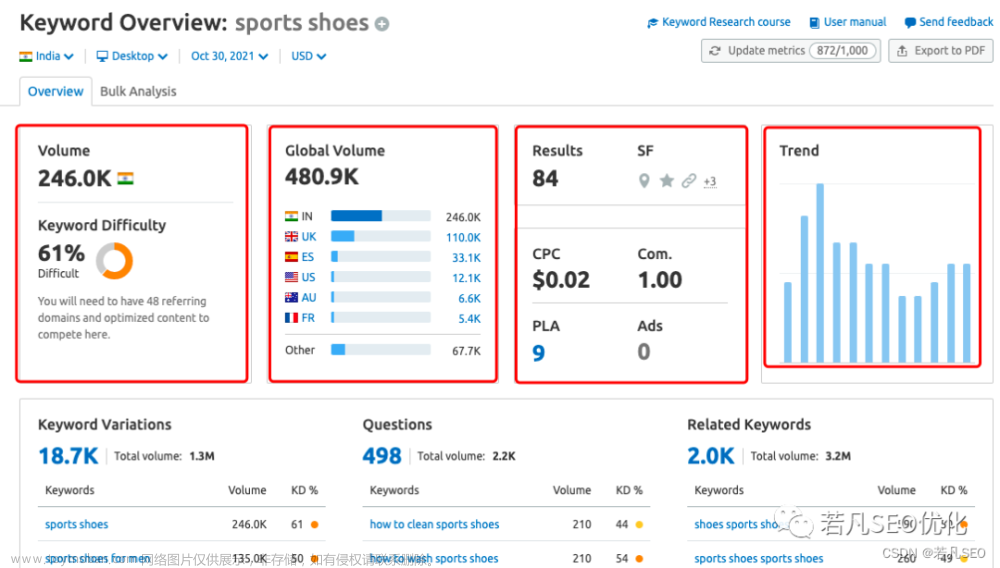
网站关键词查询挖掘,包括三大常用网站seo查询工具站点,爱站,站长,以及5118,其中,爱站及站长最多可查询到50页,5118可查询到100页,如果想要查询完整网站关键词排名数据,需充值购买会员,当然免费的查询也是需要注册会员的,不然也是没有查询权限!
5118
须自行补齐网站地址及Cookie协议头,查询需要登陆权限!
# 5118网站关键词采集
# -*- coding: utf-8 -*-
import requests
from lxml import etree
import time
import logging
logging.basicConfig(filename='s5118.log', level=logging.DEBUG,format='%(asctime)s - %(levelname)s - %(message)s')
#获取关键词
def get_keywords(site,page):
url="https://www.5118.com/seo/baidupc"
headers={
"Cookie":Cookie,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
}
data={
"isPager": "true",
"viewtype": 2,
"days": 90,
"url": site,
"orderField": "Rank",
"orderDirection" : "sc",
"pageIndex": page,
"catalogName": "",
"referKeyword": "",
}
response=requests.post(url=url,data=data,headers=headers,timeout=10)
print(response.status_code)
html=response.content.decode('utf-8')
tree=etree.HTML(html)
keywords=tree.xpath('//td[@class="list-col justify-content "]/a[@class="w100 all_array"]/text()')
print(keywords)
save_txt(keywords, site)
return keywords
#存储为csv文件
def save_csv(keywords,site):
filename=site.replace("www.",'').replace(".com",'').replace(".cn",'').replace('https://','').replace('http://','')
for keyword in keywords:
with open(f'5118_{filename}.csv','a+',encoding='utf-8-sig') as f:
f.write(f'{keyword}\n')
print("保存关键词列表成功!")
#存储为txt文件
def save_txt(keywords,site):
filename=site.replace("www.",'').replace(".com",'').replace(".cn",'').replace('https://','').replace('http://','')
for keyword in keywords:
with open(f'5118_{filename}.txt','a+',encoding='utf-8') as f:
f.write(f'{keyword}\n')
print("保存关键词列表成功!")
def main(site):
logging.info(f"开始爬取网站{site}关键词数据..")
num = 100
keys=[]
for page in range(1,num+1):
print(f"正在爬取第{page}页数据..")
logging.info(f"正在爬取第{page}页数据..")
try:
keywords = get_keywords(site, page)
keys.extend(keywords)
time.sleep(8)
except Exception as e:
print(f"爬取第{page}页数据失败--错误代码:{e}")
logging.error(f"爬取第{page}页数据失败--错误代码:{e}")
time.sleep(10)
keys = set(keys) #去重
save_csv(keys, site)
if __name__ == '__main__':
site=""
main(site)
爱站
须自行补齐网站地址及Cookie协议头,查询需要登陆权限!
# 爱站网站关键词采集
# -*- coding: utf-8 -*-
import requests
from lxml import etree
import time
import logging
logging.basicConfig(filename='aizhan.log', level=logging.DEBUG,format='%(asctime)s - %(levelname)s - %(message)s')
#获取关键词
def get_keywords(site,page):
url=f"https://baidurank.aizhan.com/baidu/{site}/-1/0/{page}/position/1/"
headers = {
"Cookie":Cookie ,
}
response = requests.get(url=url,headers=headers, timeout=10)
print(response.status_code)
html = response.content.decode('utf-8')
tree = etree.HTML(html)
keywords = tree.xpath('//td[@class="title"]/a[@class="gray"]/@title')
print(keywords)
save_txt(keywords, site)
return keywords
#存储为csv文件
def save_csv(keywords,site):
filename=site.replace("www.",'').replace(".com",'').replace(".cn",'').replace('https://','').replace('http://','')
for keyword in keywords:
with open(f'aizhan_{filename}.csv','a+',encoding='utf-8-sig') as f:
f.write(f'{keyword}\n')
print("保存关键词列表成功!")
#存储为txt文件
def save_txt(keywords,site):
filename=site.replace("www.",'').replace(".com",'').replace(".cn",'').replace('https://','').replace('http://','')
for keyword in keywords:
with open(f'aizhan_{filename}.txt','a+',encoding='utf-8') as f:
f.write(f'{keyword}\n')
print("保存关键词列表成功!")
def main(site):
logging.info(f"开始爬取网站{site}关键词数据..")
num = 50
keys=[]
for page in range(1,num+1):
print(f"正在爬取第{page}页数据..")
logging.info(f"正在爬取第{page}页数据..")
try:
keywords = get_keywords(site, page)
keys.extend(keywords)
time.sleep(8)
except Exception as e:
print(f"爬取第{page}页数据失败--错误代码:{e}")
logging.error(f"爬取第{page}页数据失败--错误代码:{e}")
time.sleep(10)
keys = set(keys) #去重
save_csv(keys, site)
if __name__ == '__main__':
site=""
main(site)
站长
须自行补齐网站地址及Cookie协议头,查询需要登陆权限!
# 站长之家网站关键词采集
# -*- coding: utf-8 -*-
import requests
from lxml import etree
import time
import logging
logging.basicConfig(filename='chinaz.log', level=logging.DEBUG,format='%(asctime)s - %(levelname)s - %(message)s')
#获取关键词
def get_keywords(site,page):
headers={
"Cookie":Cookie,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
}
url=f"https://rank.chinaz.com/{site}-0---0-{page}"
response=requests.get(url=url,headers=headers,timeout=8)
print(response)
html=response.content.decode('utf-8')
tree=etree.HTML(html)
keywords=tree.xpath('//ul[@class="_chinaz-rank-new5b"]/li[@class="w230 "]/a/text()')
print(keywords)
save_txt(keywords, site)
return keywords
#存储为csv文件
def save_csv(keywords,site):
filename=site.replace("www.",'').replace(".com",'').replace(".cn",'').replace('https://','').replace('http://','')
for keyword in keywords:
with open(f'chinaz_{filename}.csv','a+',encoding='utf-8-sig') as f:
f.write(f'{keyword}\n')
print("保存关键词列表成功!")
#存储为txt文件
def save_txt(keywords,site):
filename=site.replace("www.",'').replace(".com",'').replace(".cn",'').replace('https://','').replace('http://','')
for keyword in keywords:
with open(f'chinaz_{filename}.txt','a+',encoding='utf-8') as f:
f.write(f'{keyword}\n')
print("保存关键词列表成功!")
def main(site):
logging.info(f"开始爬取网站{site}关键词数据..")
num = 50
keys=[]
for page in range(1,num+1):
print(f"正在爬取第{page}页数据..")
logging.info(f"正在爬取第{page}页数据..")
try:
keywords = get_keywords(site, page)
keys.extend(keywords)
time.sleep(8)
except Exception as e:
print(f"爬取第{page}页数据失败--错误代码:{e}")
logging.error(f"爬取第{page}页数据失败--错误代码:{e}")
time.sleep(10)
keys = set(keys) #去重
save_csv(keys, site)
if __name__ == '__main__':
site=""
main(site)往期推荐:
Python爬虫三种解析方式带你360搜索排名查询
Python与Seo工具全网搜录查询助手exe
Python百度下拉框关键词采集工具
Python制作sitemap.xml文件工具源码
Python调用翻译API接口实现“智能”伪原创
百度快排之Python selenium 实现搜索访问目标网站
·················END·················
你好,我是二大爷,
革命老区外出进城务工人员,
互联网非早期非专业站长,
喜好python,写作,阅读,英语
不入流程序,自媒体,seo . . .
公众号不挣钱,交个网友。
读者交流群已建立,找到我备注 “交流”,即可获得加入我们~
听说点 “在看” 的都变得更好看呐~
关注关注二大爷呗~给你分享python,写作,阅读的内容噢~
扫一扫下方二维码即可关注我噢~


关注我的都变秃了
说错了,都变强了!
不信你试试
扫码关注最新动态文章来源:https://www.toymoban.com/news/detail-495562.html
公众号ID:eryeji文章来源地址https://www.toymoban.com/news/detail-495562.html
到了这里,关于Python与SEO,三大SEO网站查询工具关键词查询采集源码!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!