作为 ML 工程师,Edge Analytics和Infinity AI的团队非常熟悉与为计算机视觉应用程序获取高质量标记图像相关的挑战。随着生成图像模型的发布,例如来自Stability AI的开源Stable Diffusion,我们探索了使用生成模型来提高特定语义分割模型的性能。
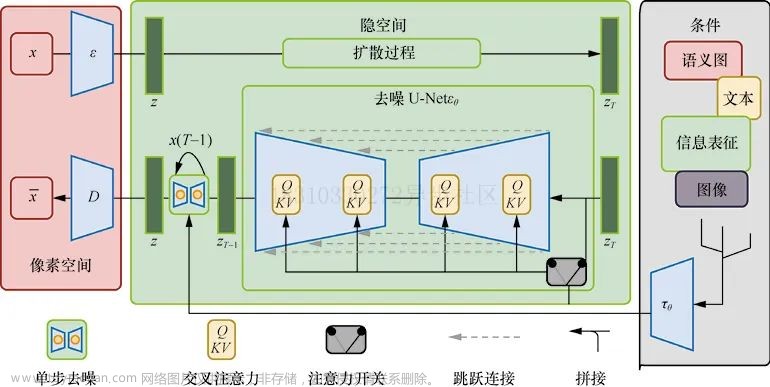
Stable Diffusion是 Stability AI 在今年早些时候发布的一种非常强大的文本到图像模型。在这篇博文中,我们将探索一种使用稳定扩散来增强训练数据的技术,以提高图像分割任务的性能。这种方法在数据有限或需要繁琐的人工标记的应用程序中特别强大。
在计算机视觉模型的上下文中,图像分割是指根据图像的内容将图像分成两个或多个部分。与“图像分类”相比,分割的目标不仅是识别图像包含什么,而且图像的哪些 部分对应于每个类。文章来源:https://www.toymoban.com/news/detail-495818.html
具体来说,我们将查看DeepGlobe 道路提取数据集,其中包含大约 6,000 张乡村道路的航拍照片。该数据集的任务是将图像分为两类:文章来源地址https://www.toymoban.com/news/detail-495818.html
到了这里,关于Stable Diffusion教程之使用Stable Diffusion改进图像分割模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!