分类目录:《深入理解深度学习》总目录
相关文章:
·注意力机制(Attention Mechanism):基础知识
·注意力机制(Attention Mechanism):注意力汇聚与Nadaraya-Watson核回归
·注意力机制(Attention Mechanism):注意力评分函数(Attention Scoring Function)
·注意力机制(Attention Mechanism):Bahdanau注意力
·注意力机制(Attention Mechanism):自注意力(Self-attention)
·注意力机制(Attention Mechanism):多头注意力(Multi-head Attention)
· 注意力机制(Attention Mechanism):带掩码的多头注意力(Masked Multi-head Attention)
·注意力机制(Attention Mechanism):位置编码(Positional Encoding)
· Transformer:编码器(Encoder)部分
· Transformer:解码器(Decoder)的多头注意力层(Multi-headAttention)
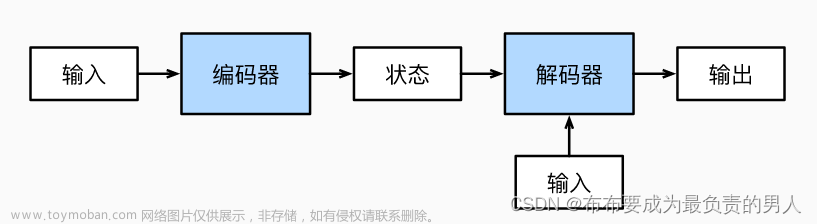
假设我们想把英语句子“I am good.”(原句)翻译成法语句子“Je vais bien.”(目标句)。首先,将原句“I am good.”送入编码器,使编码器学习原句,并计算特征值。《深入理解深度学习——Transformer:编码器(Encoder)部分》中,我们学习了编码器是如何计算原句的特征值的。然后,我们把从编码器求得的特征值送入解码器。解码器将特征值作为输入,并生成目标句Je vais bien,如下图所示。
在编码器部分,我们了解到可以叠加
N
N
N个编码器。同理,解码器也可以有
N
N
N个叠加在一起。为简化说明,我们设定
N
=
2
N=2
N=2。如下图所示,一个解码器的输出会被作为输入传入下一个解码器。我们还可以看到,编码器将原句的特征值(编码器的输出)作为输入传给所有解码器,而非只给第一个解码器。因此,一个解码器(第一个除外)将有两个输入:一个是来自前一个解码器的输出,另一个是编码器输出的特征值。
接下来,我们学习解码器究竟是如何生成目标句的。当
t
=
1
t=1
t=1时(
t
t
t表示时间步),解码器的输入是<sos>,这表示句子的开始。解码器收到<sos>作为输入,生成目标句中的第一个词,即Je,如下图
t
=
1
t=1
t=1所示。当
t
=
2
t=2
t=2时,解码器使用当前的输入和在上一步(
t
−
1
t-1
t−1)生成的单词,预测句子中的下一个单词。在本例中,解码器将<sos>和Je作为输入,并试图生成目标句中的下一个单词,如下图
t
=
2
t=2
t=2所示。同理,解码器在
t
=
3
t=3
t=3时,将<sos>、Je和vais作为输入,并试图生成句子中的下一个单词,如下图
t
=
3
t=3
t=3所示。在每一步中,解码器都将上一步新生成的单词与输入的词结合起来,并预测下一个单词。因此,在最后一步(
t
=
4
t=4
t=4),解码器将<sos>、Je、vais和bien作为输入,并试图生成句子中的下一个单词,如下图
t
=
4
t=4
t=4所示。
从上图中可以看到,一旦生成表示句子结束的<eos>标记,就意味着解码器已经完成了对目标句的生成工作。
在编码器部分,我们将输入转换为嵌入矩阵,并将位置编码添加到其中,然后将其作为输入送入编码器。同理,我们也不是将输入直接送入解码器,而是将其转换为嵌入矩阵,为其添加位置编码,然后再送入解码器。如下图所示,假设在时间步
t
=
2
t=2
t=2,我们将输入转换为嵌入(我们称之为嵌入值输出,因为这里计算的是解码器在以前的步骤中生成的词的嵌入),将位置编码加入其中,然后将其送入解码器。
一个解码器模块及其所有的组件如下图所示。解码器内部有3个子层:
- 带掩码的多头注意力层
- 多头注意力层
- 前馈网络层
与编码器模块相似,解码器模块也有多头注意力层和前馈网络层,但多了带掩码的多头注意力层。
以英法翻译任务为例,假设训练数据集样本如下样本:
| 原句(英语) | 目标句(法语) |
|---|---|
| I am good. | Je vais bien. |
| Good morning. | Bonjour. |
| Thank you very much. | Merci beaucoup. |
上述数据集由两部分组成:原句和目标句。在上文中我们学习了解码器在测试期间是如何在每个步骤中逐字预测目标句的。在训练期间,由于有正确的目标句,解码器可以直接将整个目标句稍作修改作为输入。解码器将输入的<sos>作为第一个标记,并在每一步将下一个预测词与输入结合起来,以预测目标句,直到遇到<eos>标记为止。因此,我们只需将<sos>标记添加到目标句的开头,再将整体作为输入发送给解码器。比如要把英语句子“I am good.”转换成法语句子“Je vais bien.”。我们只需在目标句的开头加上<sos>标记,并将<sos>Je vais bien作为输入发送给解码器。解码器将预测输出为Je vais bien<eos>,如下图所示。
我们不是将输入直接送入解码器,而是将其转换为嵌入矩阵(输出嵌入矩阵)并添加位置编码,然后再送入解码器。假设添加输出嵌入矩阵和位置编码后得到下图所示的矩阵
X
X
X。
将矩阵
X
X
X送入解码器。解码器中的第一层是带掩码的多头注意力层。这编码器中的多头注意力层的工作原理相似,但有一点不同,具体的原理可以参考《深入理解深度学习——注意力机制(Attention Mechanism):带掩码的多头注意力(Masked Multi-head Attention)》中的带掩码的多头注意力。最后,我们把注意力矩阵
M
M
M送到解码器的下一个子层,也就是另一个多头注意力层。这个多头注意力层的设计可以参考文章《深入理解深度学习——Transformer:解码器(Decoder)的多头注意力层(Multi-headAttention)》,它会输出一个注意力矩阵到后面的前馈网络层。
解码器的下一个子层是前馈网络层,且解码器的前馈网络层的工作原理与我们在《深入理解深度学习——Transformer:编码器(Encoder)部分》中学习的编码器部分的前馈网络层完全相同。同样,叠加和归一组件连接子层的输入和输出,如下图所示。
一旦解码器学习了目标句的特征,我们就将顶层解码器的输出送入线性层和Softmax层,如下图所示。
线性层将生成一个logit向量,其大小等于原句中的词汇量。假设原句只由以下3个词组成:
vocabulary = {bien, Je, vais}
那么,线性层返回的logit向量的大小将为3。接下来,使用Softmax函数将logit向量转换成概率,然后解码器将输出具有高概率值的词的索引值。让我们通过一个示例来理解这一过程。假设解码器的输入词是<sos>和Je。基于输入词,解码器需要预测目标句中的下一个词。然后,我们把顶层解码器的输出送入线性层。线性层生成logit向量,其大小等于原句中的词汇量。假设线性层返回如下logit向量:
logit
=
[
45
,
40
,
49
]
\text{logit}=[45, 40, 49]
logit=[45,40,49],则Softmax函数应用于logit向量,从而得到概率:
prob
=
[
0.018
,
0.000
,
0.981
]
\text{prob}=[0.018, 0.000, 0.981]
prob=[0.018,0.000,0.981]。从概率矩阵中,我们可以看出索引2的概率最高。所以,模型预测出的下一个词位于词汇表中索引2的位置。由于vais这个词位于索引2,因此解码器预测目标句中的下一个词是vais。通过这种方式,解码器依次预测目标句中的下一个词。
上文就是解码器的所有组件。下面,让我们把它们放在一起,看看它们是如何作为一个整体工作的。下图显示了两个解码器。为了避免重复,只有解码器1被展开说明。
通过上图,我们可以得出以下几点:文章来源:https://www.toymoban.com/news/detail-495880.html
- 我们将解码器的输入转换为嵌入矩阵,然后将位置编码加入其中,并将其作为输入送入底层的解码器(解码器1)。
- 解码器收到输入,并将其发送给带掩码的多头注意力层,生成注意力矩阵 M M M。
- 将注意力矩阵 M M M和编码器输出的特征值 R R R作为多头注意力层(编码器—解码器注意力层)的输入,并再次输出新的注意力矩阵。
- 把从多头注意力层得到的注意力矩阵作为输入,送入前馈网络层。前馈网络层将注意力矩阵作为输入,并将解码后的特征作为输出。
- 我们把从解码器1得到的输出作为输入,将其送入解码器2。
- 解码器2进行同样的处理,并输出目标句的特征。我们还可以将 N N N个解码器层层堆叠起来。从最后的解码器得到的输出(解码后的特征)将是目标句的特征。
- 我们将目标句的特征送入线性层和Softmax层,通过概率得到预测的词并输出。
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.
[3] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[4] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[5] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[6] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[7] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.文章来源地址https://www.toymoban.com/news/detail-495880.html
到了这里,关于深入理解深度学习——Transformer:解码器(Decoder)部分的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!